Если вы занимаетесь машинным обучением, вы неизбежно столкнетесь с такой штукой, которая называется «One Hot Encoding». Однако это одна из тех вещей, которые трудно понять новичку в машинном обучении, поскольку вам нужно кое-что знать о машинном обучении, чтобы понять его. Чтобы помочь, я решил попытаться дать объяснение для новичков.
Когда вы создаете какую-либо программу машинного обучения, первое, что вы делаете, - это, как правило, предварительная обработка. Под этим я подразумеваю подготовку данных для анализа вашей программой. В конце концов, вы не можете просто добавить электронную таблицу или несколько изображений в свою программу и ожидать, что она будет знать, что делать. Мы еще не достигли такого уровня ИИ.
Большая часть предварительной обработки - это что-то кодирование. Это означает представление каждого фрагмента данных способом, понятным компьютеру, отсюда и название encode, что буквально означает «преобразовать в [компьютерный] код». Существует множество различных способов кодирования, таких как Кодирование метки или, как вы уже догадались, Одно горячее кодирование. Кодирование меток интуитивно понятно и легко, поэтому сначала я объясню это. Надеюсь, оттуда вы сможете полностью понять одну горячую кодировку.
Предположим, мы работаем с категориальными данными, такими как кошки и собаки. Глядя на название кодировки метки, вы можете догадаться, что она кодирует метки, где метка - это просто категория (например, кошка или собака), а кодирование просто означает присвоение им числа, представляющего эту категорию (1 для кошки и 2 для собаки). Дав каждой категории номер, компьютер теперь знает, как их представлять, поскольку компьютер знает, как работать с числами. И вот мы уже закончили объяснение кодировки меток. Но есть проблема, из-за которой он часто не работает с категориальными данными.
Проблема в том, что при кодировании меток категории теперь имеют естественные упорядоченные отношения. Компьютер делает это, потому что он запрограммирован на то, чтобы рассматривать более высокие числа как более высокие числа; он, естественно, придает более высоким числам более высокие веса. Мы можем увидеть проблему с этим на примере:
- Представьте, что у вас есть 3 категории продуктов: яблоки, курица и брокколи. Используя кодировку меток, вы должны присвоить каждому из них номер, чтобы разделить их на категории: яблоки = 1, курица = 2 и брокколи = 3. Но теперь, если ваша модель внутренне должна рассчитывать среднее значение по категориям, она может сделать 1+ 3 = 4/2 = 2. Это означает, что в соответствии с вашей моделью среднее количество яблок и курицы вместе составляет брокколи.
Очевидно, что такой образ мышления вашей модели приведет к тому, что корреляции будут совершенно неверными, поэтому нам нужно ввести одноразовое кодирование.
Вместо того, чтобы обозначать объекты как числа, начиная с 1 и затем увеличиваясь для каждой категории, мы воспользуемся более двоичным стилем категоризации. Вы могли бы подумать, если бы знали, что такое горячо (оно относится к двоичному кодированию, но не беспокойтесь об этом). Позвольте мне представить визуализированную разницу между меткой и горячим кодированием. Посмотрите, сможете ли вы найти разницу:
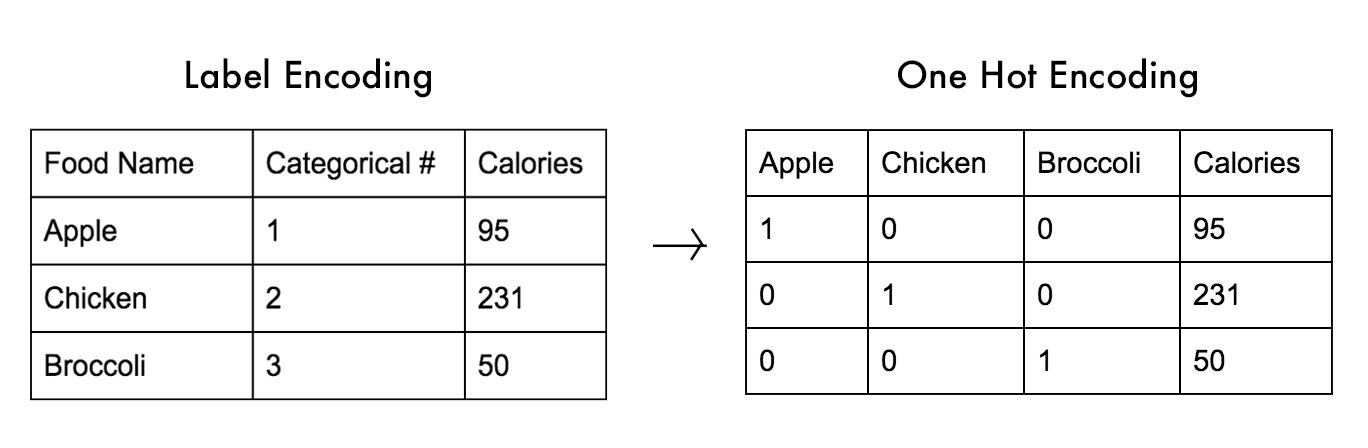
Какая разница? Ну, наши категории раньше были строками, но теперь они столбцы. Однако наша числовая переменная, калории, осталась прежней. 1 в определенном столбце сообщит компьютеру правильную категорию для данных этой строки. Другими словами, мы создали дополнительный двоичный столбец для каждой категории.
Не сразу понятно, почему это лучше (помимо проблемы, о которой я упоминал ранее), и это потому, что нет явной причины. Как и многие другие вещи в машинном обучении, мы не будем использовать это в каждой ситуации; это не совсем лучше, чем кодирование ярлыков. Он просто решает проблему, с которой вы столкнетесь с кодировкой ярлыков при работе с категориальными данными.
Одна горячая кодировка в коде (поняли? Это каламбур)
Всегда полезно увидеть, как это делается в коде, поэтому давайте рассмотрим пример. Обычно я твердо убежден, что мы должны делать что-то без каких-либо библиотек, чтобы изучить это, но просто для этой утомительной предварительной обработки нам действительно не нужно. Библиотеки могут сделать это настолько простым. Мы собираемся использовать numpy, sklearn и pandas, поскольку вы обнаружите, что используете эти 3 библиотеки во многих своих проектах.
from sklearn.preprocessing import LabelEncoder, OneHotEncoder import numpy as np import pandas as pd
Теперь, когда у нас есть инструменты, приступим. Мы будем работать с вымышленным набором данных. Введите набор данных с помощью функции pandas .read_csv:
dataset = pd.read_csv('made_up_thing.csv')
Надеюсь, это говорит само за себя. Дальше все немного сложнее. Особенность электронных таблиц в том, что некоторые столбцы могут вас беспокоить, а могут и нет. Для простоты предположим, что мы заботимся обо всем, кроме последнего столбца. Мы собираемся использовать функцию pandas .iloc, которая получает данные из любых столбцов, в которые вы указываете:
X = dataset.iloc[:, :-1].values.iloc фактически принимает [строки, столбцы], поэтому мы ввели [:,: -1]. : Потому что нам нужны все строки в этих столбцах, и: именно так вы это делаете. Мы добавляем .values, ну, получаем значения в тех сегментах, которые мы выбрали. Другими словами, первая часть выбирает значения, вторая часть получает значения.
Теперь займемся кодированием. Sklearn делает это невероятно простым, но есть загвоздка. Вы могли заметить, что мы импортировали и labelencoder, и один горячий кодировщик. Один из самых популярных кодировщиков Sklearn на самом деле не умеет преобразовывать категории в числа, он знает только, как преобразовывать числа в двоичные. Сначала мы должны использовать labelencoder.
Во-первых, мы настроим лабеленкодер, как и любой обычный объект:
le = LabelEncoder()
Затем нам нужно использовать функцию .fit_transform в sklearn. Допустим, нам нужно закодировать только первый столбец. Мы бы сделали:
X[:, 0] = le.fit_transform(X[:, 0])
Эта функция представляет собой комбинацию команд .fit и .transform. .fit принимает X (в данном случае первый столбец X из-за нашего X [:, 0]) и преобразует все в числовые данные. .transform затем применяет это преобразование.
Все, что осталось, - это использовать один горячий кодировщик. К счастью, это почти то же самое, что мы только что сделали:
ohe = OneHotEncoder(categorical_features = [0]) X = ohe.fit_transform(X).toarray()
Category_feartures - это параметр, который указывает, какой столбец мы хотим кодировать одним горячим способом, и, поскольку мы хотим кодировать первый столбец, мы помещаем [0]. Наконец, мы помещаем_transform в двоичный файл и превращаем его в массив, чтобы мы могли легко работать с ним в будущем.
Вот и все! Все очень просто. И последнее замечание: если вам нужно сделать больше, чем просто первый столбец, вы делаете то, что мы только что сделали, но вместо 0 вы помещаете любой столбец, который хотите. Для многих столбцов вы можете поместить его в цикл for:
le = LabelEncoder()
#for 10 columns
for i in range(10):
X[:,i] = le.fit_transform(X[:,i])
Удачи вам в приключениях с машинным обучением!