
Люди любят слова и обычно используют их для представления и описания данных (категориальных признаков). К сожалению, алгоритмы машинного обучения не разделяют нашей страсти к словам, они предпочитают числа. Вот почему на этапе предварительной обработки, прежде чем мы снабдим нашу модель ML для прогнозирования, необходимо закодировать категориальные признаки.
Кодирование — это, по сути, присвоение продуманного номера каждой категории функции. Существует множество методов, наиболее популярными из которых являются горячее кодирование (n категорий) и фиктивная переменная (n-1 категорий), которые создают двоичный столбец для каждой категории. : 1, если категория присутствует, и 0, если нет. Проблема с этими методами возникает, когда в функции слишком много категорий, потому что она создаст много столбцов, и большинство из них будут нулями, поэтому это может запутать нашу модель или даже замедлить ее.
Введение в целевое кодирование
Целевое кодирование — это метод, использующий среднее значение выходных данных для каждой категории. Например, на изображении ниже показано, что результат равен 1 в 3 из 4 случаев в категории A, поэтому среднее значение равно 0,75;0,25 в категории B,и 0,33 в категории C. По сравнению с горячим кодированием (ohe) нам не нужны три столбца (или намного больше), достаточно одного. И это существенное преимущество этого метода, он может работать со многими категориями.

Легкий гороховый лимонный сок, верно? Что ж, есть проблема. Как видите, метод строго зависит от целевой переменной, той, которую мы хотим предсказать. Это создает проблему, известную как утечка. Вкратце, это когда мы «даем» некоторые интерпретационные ответы (данные, к которым у нее не должно быть доступа) модели, поэтому она использует это преимущество и возвращает выдающиеся результаты в обучающем наборе, но в тестовом наборе и реальных данных, производительность может быть плохой, приводя к переоснащению.
Существует несколько подходов к решению или минимизации этой проблемы (отказ от ответственности: источники — это то, где я это видел, не обязательно первоисточник):
- Временные окна [Zheng & Casari (2018)]: используйте ранний и независимый пакет данных для вычисления целевой кодировки; затем используйте фактические данные (другой пакет) для обучения с целевым кодированием первого пакета и, наконец, используйте будущие данные для тестирования. Это решение особенно хорошо подходит для производственных ситуаций в режиме реального времени, но требует задержки для сбора ранней партии.
- Шум [Доктор. Dataman (2019)]: внесите случайный шум в результаты целевого кодирования, чтобы он не был слишком точным на тренировочном наборе. Шум колеблется от 0 до доли целевой переменной. Аналитик выбирает дробное значение (как гиперпараметр).
- наборы k-валидации [Thakur (2021)]: случайным образом присваивайте каждой точке данных k-значение для создания подмножеств в любом количестве (5 — хорошее число). Это итеративный процесс, аналогичный исключению одного.
Создайте два набора: проверку (одно подмножество: k = k_n) и обучение (другие подмножества: k != k_n).
Целевое кодирование вычисляется с обучающим набором, и результатыleft_joinс проверочным набором, а затем процесс повторяется для каждого подмножества. Наконец, используйте среднее значение всех из них для каждой категории.
Подход Тхакура был принят в функции, представленной здесь. Но вы можете реализовать свой любимый или найти больше решений.
Еще одна небольшая проблема с целевым кодированием заключается в том, что его необходимо часто обновлять, если распределение категорий постоянно меняется. Например, в маркетинговой аналитике, где тенденции и интересы клиентов меняются каждую минуту, задержка обновлений и последующие неверные данные могут привести к потере прибыли.
Раздел, за которым вы пришли
Данные были сгенерированы случайным образом с использованием вектора LETTERS и бинарного целевого объекта. Кроме того, аргумент prob тоже был случайным, так что во всех категориях не было примерно одинакового количества.
set.seed(946) #in case you want the same results
data <- tibble(cat = sample(LETTERS, 6000,
replace = TRUE,
prob = rep(runif(26))),
target = sample(c(0, 1), 6000,
replace = TRUE))

Теперь мы создаем значение k для каждой строки. Я использовал 5 подмножеств, но вы можете использовать больше или меньше. prob является универсальным, потому что мы хотим, чтобы подмножества имели в основном одни и те же данные.
set.seed(123)
data <- data %>%
mutate(k = sample(1:5,
nrow(.),
replace = TRUE))
head(data, 10)
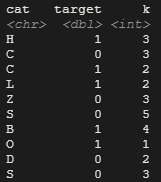
Хорошо! Мы все настроили. Теперь давайте посмотрим на функцию.
Функция использует tidyverse, поэтому убедитесь, что она у вас установлена [install.packages(“tidyverse”)]. Он имеет 6 аргументов:
- data (dataframe или tibble): данные, содержащие все переменные.
- enc_col (строка): имя столбца, которое мы хотим закодировать.
- tar_col (строка): имя столбца целевого объекта.
- k_col (строка): имя столбца с наборами k.
- kmin и kmax (целое число): минимум и максимум k. Предполагается последовательность с шагом 1.
С помощью map_df мы перебираем вектор k, заданный kmin и kmax, map_df возвращает кадр данных. Разделите данные обучения (xtrain) и проверки (xvalid). Целевая кодировка вычисляется с помощью xtrain. Результаты left_join с xvalid и select интересующими нас столбцами (категория и категория закодированы). Результаты для каждого k в цикле хранятся в temp_df.
Затем мы вычисляем последние результаты с mean каждой категории и с этими результатами, left_join к исходным данным.
target_enc <- function(data, enc_col, tar_col, k_col,
kmin, kmax){
require(tidyverse)
col_name <- paste0("tar_enc_", enc_col)
temp <- map_df(kmin:kmax, function(k){
xtrain <- data[data[k_col] != k, ]
xvalid <- data[data[k_col] == k, ]
feat <- xtrain %>% group_by_at(enc_col) %>%
summarise_at(.vars = tar_col, mean)
colnames(feat)[2] <- col_name
temp_df <- xvalid %>% left_join(feat, by = enc_col) %>%
select(all_of(enc_col), all_of(col_name))
return(temp_df)
})
temp_enc <- temp %>% group_by_at(enc_col) %>%
summarise_at(.vars = col_name, .funs = mean) %>%
ungroup()
data %>% left_join(temp_enc, by = enc_col)
}
Рекомендация: объединить редкие категории в одну категорию. Целевая кодировка может привести к бессмысленным или несбалансированным результатам с категориями, которые появляются несколько раз.
Я суммирую в одну категорию все категории с n ‹ 75 перед использованием функции. Как видите, все категории закодированы.
data <- data %>%
mutate(cat = fct_lump_min(cat, 75))
target_enc(data = data, enc_col = "cat",
tar_col = "target", k_col = "k",
kmin = 1, kmax = 5)

Если вы хотите увидеть закодированное значение для каждой категории (обратите внимание, что некоторые буквы исчезают и появляется категория “Other”):
target_enc(data = data, enc_col = "cat",
tar_col = "target", k_col = "k",
kmin = 1, kmax = 5) %>%
distinct(cat, tar_enc_cat) %>%
arrange(cat) %>% View()
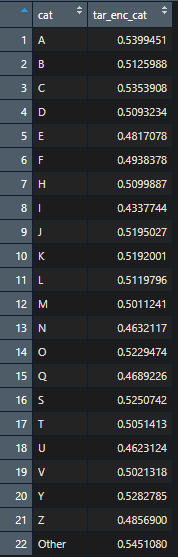
Ура! Мы сделали это. Надеюсь, это поможет вам когда-нибудь! Увидимся в следующий раз.