Эта статья посвящена тому, как реализовать линейную регрессию и градиентный спуск
с нуля без помощи какой-либо библиотеки машинного обучения.
в первую очередь читаем данные из CSV
В этот раз я использую датасеты зарплат из Kaggle
Но вы также можете сделать то же самое с любыми данными или наборами данных
, если они имеют корреляцию!
data = pd.read_csv('./Salary.csv')

Постройте данные с
plt.plot(data['Salary']) plt.plot(data['YearsExperience'])


Тогда давайте смоделируем нашу линейную регрессию!
Но ПРЕЖДЕ всего нам нужно понять, что такое линейная регрессия и как мы можем оптимизировать их с помощью градиентного спуска.
линейная регрессия — это просто попытка подогнать линию так, чтобы она лучше всего подходила к точке данных
, которую мы назвали «Линия наилучшего соответствия».

сначала мы рисуем линию (случайно или просто устанавливаем значение)
мы назвали эту линию регрессии, которая включает 2 параметра
f(x) = mx+ b [если вы этого не понимаете, попробуйте смоделировать формулу в Desmos]
M заставляет функцию вращаться, а b сдвигает функцию по оси Y
поэтому чтобы создать линию регрессии, мы просто устанавливаем параметры M и B случайным образом
class ln():
# setup parameters
def __init__(self):
# f(x) = mx + b : axis*X+intercept
self.axis = np.random.normal(-1,1,(1,1))
self.intercept = np.random.normal(-1,1,(1,1))
print('Axis:', self.axis, 'Intercept:', self.intercept)

затем мы вычисляем ошибку, измеряя расстояние y в точке x на линии регрессии по сравнению с реальным y в этой точке данных x, возводя его в квадрат, чтобы избавиться от отрицательного значения. Затем находим среднее значение.
мы назвали это ФУНКЦИЕЙ СТОИМОСТИ. Потеря
Эта функция представляет собой MSE или среднеквадратичную ошибку.
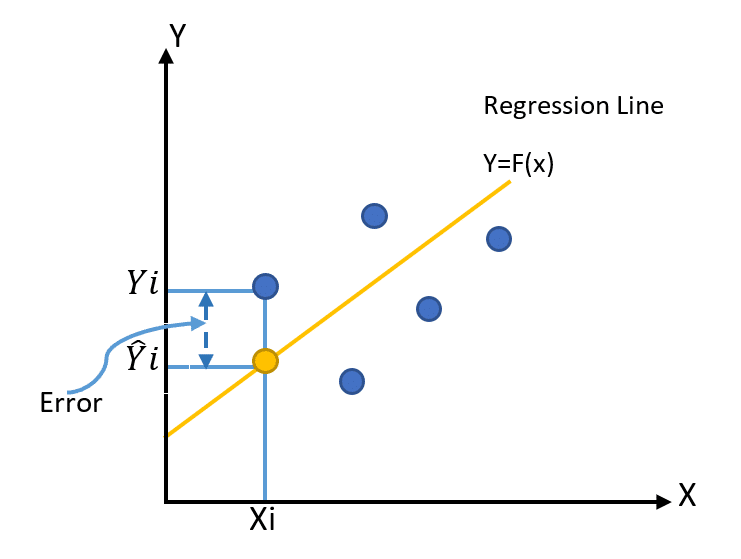

Чтобы реализовать это в python, мы просто пройдемся по нашим обучающим данным
подставим их (x) в нашу строку регрессии и сравним результаты (y) с (y_real)
# Cost Function
def loss(self, real, pred):
loss = np.sqrt((np.sum((real-pred)**2))/real.shape[1])
return loss
# Use To Predict
def forward(self, x):
# normalize
x = self.norm(x)
# do f(x) = m*x+b
y = (self.axis*np.array(x)+self.intercept)
return y
когда мы подключим убыток (реальный, предварительный), вы получите убыток, но только для визуализации, лол
нам действительно нужно немного больше поработать с нашей потерей, чтобы получить новый вес
в этом случае нам нужно вычислить частную производную параметров m и b относительно x и вычесть ее из старого веса
# Find Gradient
def grad(self, real, pred, x):
# partial derivative of axis & intercept
grad_axis = 0
grad_intercept = 0
n = len(x)
# Sum of
for i in range(n):
# Partial Derivatives
grad_axis += (2/n) * x[i] * (real[0,i]-pred[i])
grad_intercept += (2/n) * (real[0,i] -pred[i])
return grad_axis, grad_intercept
# Training model
def fit(self, x, y, epoch=1, lr=0.001):
# Training Loop
for i in range(epoch):
real = self.norm(y)
pred = self.forward(x)
# compute loss(for logging)
loss = self.loss(pred, real)
if i % 100 == 0:
print('MSE:', loss)
# calc grad
grad_axis, grad_intercept = self.grad(pred, real, x)
# take a descent step
new_axis = self.axis - (lr*grad_axis)
new_intercept = self.intercept - (lr*grad_intercept)
# update weight
self.update_weight(new_axis, new_intercept)
Итак, наши полные классы линейной регрессии будут выглядеть так:
class ln():
# setup parameters
def __init__(self):
self.axis = np.random.normal(-1,1,(1,1))
self.intercept = np.random.normal(-1,1,(1,1))
print('Axis:', self.axis, 'Intercept:', self.intercept)
# normalizer scaling down by 1000 denominators to make compuational more effective
def norm(self,x, reverse=False):
scale = 1000
if not reverse:
x = x/scale
return x
elif reverse:
x = x*scale
return x
# function just to cahneg weight (make code cleaner)
def update_weight(self, weight, intercept):
self.axis = weight
self.intercept = intercept
# plotting the equation line
def plot(self, data):
# [0] to get data out of list (plt.plot require 1 dimensional data)
m = self.axis[0]
b = self.intercept[0]
print(f'm{m} b{b}')
x = np.array(data[data.columns[0]])
y = np.array(data[data.columns[1]])
y_pred = self.forward(x).tolist()[0]
y_pred = [self.norm(x, reverse=True) for x in y_pred]
plt.plot(x, y, 'o')
plt.plot(x, y_pred)
plt.show()
# Cost Function
def loss(self, real, pred):
loss = np.sqrt((np.sum((real-pred)**2))/real.shape[1])
return loss
# Find Gradient
def grad(self, real, pred, x):
# partial derivative of axis & intercept
grad_axis = 0
grad_intercept = 0
n = len(x)
# Sum of
for i in range(n):
# Partial Derivatives
grad_axis += (2/n) * x[i] * (real[0,i]-pred[i])
grad_intercept += (2/n) * (real[0,i] -pred[i])
return grad_axis, grad_intercept
# Use To Predict
def forward(self, x):
x = self.norm(x)
y = (self.axis*np.array(x)+self.intercept)
return y
# Training model
def fit(self, x, y, epoch=1, lr=0.001):
# Training Loop
for i in range(epoch):
real = self.norm(y)
pred = self.forward(x)
# compute loss(for logging)
loss = self.loss(pred, real)
if i % 100 == 0:
print('MSE:', loss)
# calc grad
grad_axis, grad_intercept = self.grad(pred, real, x)
# take a descent step
new_axis = self.axis - (lr*grad_axis)
new_intercept = self.intercept - (lr*grad_intercept)
# update weight
self.update_weight(new_axis, new_intercept)
Гитхаб: https://github.com/HRNPH/linear_regression_from_scratch