
Введение
Если вы один из многих пользователей R, которые переходят на Python, вы можете оказаться в зависимости от удобства некоторых из самых любимых библиотек R. На первый взгляд переход от удобства и простоты R может показаться немного пугающим, поскольку ландшафт Python, хотя и достаточный, часто может производить то, что кажется слишком большим количеством переводов для данной части функциональности. Найти прямой перевод не всегда легко.
Цель этого — поделиться осознанной точкой зрения о том, на какие методы следует опираться, когда вы переводите свой рабочий процесс на Python.
В этой статье мы рассмотрим альтернативы удобным методам dplyr для выполнения всех видов объединений.
Следите за новостями, чтобы не пропустить другие статьи, посвященные некоторым из этих ключевых вопросов.
Что вы узнаете
В этой статье мы разберем первичные переводы функций соединения R в библиотеке dplyr.
Прочитав эту статью, вы можете ожидать изучения основных переводов Python для следующих функций:
- left_join
- право_присоединиться
- внутреннее соединение
- внешнее_соединение
- анти_присоединение
- semi_join
Обзор объединений
Функции соединения используются для объединения двух или более фреймов данных на основе общего столбца.
Ниже приведен краткий обзор различных определений
- left_join: возвращает все строки из левой таблицы и любые совпадающие строки из правой таблицы
- right_join: возвращает все строки из правой таблицы и любые совпадающие строки из левой таблицы.
- inner_join: возвращает только те записи, которые присутствуют в обеих таблицах.
- external_join: эта функция возвращает все строки из обеих таблиц и заполняет любые отсутствующие значения NA.
- anti_join: эта функция возвращает все строки из левой таблицы, которые не совпадают в правой таблице.
- semi_join: эта функция возвращает все строки из левой таблицы, которые совпадают в правой таблице.
Время сравнения
Прежде чем мы начнем, мы будем использовать два примера фреймов данных. Я включу код для создания этих двух образцов фреймов данных, чтобы вы могли следовать:
# libraries
import pandas as pd
# sample df1
df1 = pd.DataFrame({
'join_column': ['A', 'B', 'C', 'D'],
'col1': [10, 20, 30, 40],
'col2': [100, 200, 300, 400]
})
# sample df2
df2 = pd.DataFrame({
'join_column': ['B', 'D', 'E', 'F'],
'col3': ['X', 'Y', 'Z', 'W'],
'col4': ['P', 'Q', 'R', 'S']
})
С этим покончено, давайте погрузимся
Левое соединение
R
В r вы получаете удовольствие от простоты и потока dplyr, вы указываете интересующий вас фрейм данных, в данном случае df1, и присоединяете к нему df2 в общем поле.
df3 <- df1 %>%
left_join(df2, by = "join_column")
Питон
К счастью, в Python все не так уж и отличается. Основное различие заключается в синтаксисе, merge по сравнению с left_join, on, а не by и так далее.
Еще одно отличие состоит в том, что мы можем использовать .merge в качестве метода для левого фрейма данных. Одним из интересных и более удобных аспектов слияния является параметр how. Это позволяет нам определить интересующий нас тип соединения. Не то чтобы было так уж сложно запомнить left_join, right_join, inner_join, но эй… иногда нужно получать удовольствие от простых вещей.
df3 = df1.merge(df2, on = "join_column", how = "left")
Еще одно замечание: вы также можете вызывать слияние как функцию, и в этом случае команда будет выглядеть так:
df3 = pd.merge(df1, df2, on = "join_column", how = "left")
Не супер разные, но полезно знать, что и функция, и метод взяты из панд, и оба доступны.
Результат:

Право присоединиться
Почти самоочевидно, единственное, что здесь меняется, это то, что мы выполняем правильное соединение, а также то же самое, что и замена того, какой фрейм данных мы вызываем первым.
Мы рассмотрим примеры здесь.
R
Единственное, что здесь меняется, это функция
df3 <- df1 %>%
right_join(df2, by = "join_column")
Питон
df3 = df1.merge(df2, on = "join_column", how = "right")
Результат:
Внутреннее соединение
Подобно правому соединению, следующие несколько функций очень просты, так что мы быстро разберемся.
R
df3 <- df1 %>%
inner_join(df2, by = "join_column")
Питон
df3 = df1.merge(df2, on = "join_column", how = "inner")
Результат:
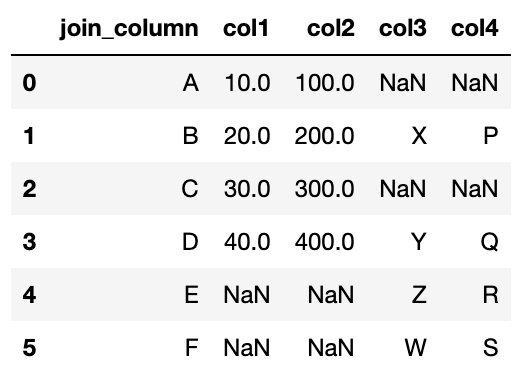
Внешнее соединение
R
df3 <- df1 %>%
outer_join(df2, by = "join_column")
Питон
df3 = df1.merge(df2, on = "join_column", how = "outer")
Анти присоединение
Вот где Python вмешивается немного больше, но в его защиту анти-объединения не самые распространенные.
R
df3 <- df1 %>%
anti_join(df2, by = "join_column")
Питон
df3 = df1.merge(df2["join_column"], on = "join_column", how = "left", indicator=True)
.query('_merge == "left_only"')
.drop('_merge', 1)
Здесь нужно объяснить несколько разных частей.
Когда мы устанавливаем для параметра indicator значение True, добавляется новый столбец с именем «_merge», который в случае левого соединения говорит «left_only» или «both». Как вы могли догадаться, «left_only» означает, что совпадения в правом фрейме данных не было, а в случае «обоих» совпадение было.
Мы указываем True, чтобы затем использовать .query, чтобы указать, что нам нужны только те записи, которые не были найдены в правильном фрейме данных.
И, наконец, в качестве небольшой очистки мы удаляем столбец «_merge».
И последняя часть, которую я упомяну, мы также должны подмножить правильный фрейм данных только для столбца соединения. В противном случае мы также добавим все нулевые столбцы из правого фрейма данных. Что было бы бессмысленно и противоречило бы традиционному использованию класса anti_join.
Как я уже сказал, намного сложнее, но все еще достаточно просто концептуально.
Результаты:
Полуприсоединиться
Напоминаем, что semi-соединения являются противоположностью anti_join. Мы будем возвращать только записи из левого фрейма данных, в которых есть совпадения с правым фреймом данных.
Фактически ничего не меняется в R.
R
df3 <- df1 %>%
anti_join(df2, by = "join_column")
Питон
Подобно тому, что мы видели выше с анти-объединениями; однако в этом случае мы запрашиваем, где _merge равно «оба», что требует совпадения.
pd.merge(df1, df2['join_column'], on = "column_name", how = "left", indicator=True)\
.query('_merge == "both"')\
.drop('_merge', 1)

Заключение:
Мы быстро покрыли много земли. Когда дело доходит до объединения панд, шаги аналогичны dplyr в R. Мы изучили простые и эффективные переводы python для ключевых функций соединения в R, в частности, dplyr.
В частности, мы исследовали следующие типы соединений:
- left_join
- право_присоединиться
- внутреннее соединение
- внешнее_соединение
- анти_присоединение
- semi_join
Мы надеемся, что эта статья окажется полезной. Сообщите нам, какие альтернативные методы вы используете в Python вместо функции merge в pandas.