Cele mai bune practici de răzuire a datelor folosind seleniu în Python

Seleniu pentru răzuire web
Selenium este o bibliotecă de automatizare a browserului. Cel mai adesea folosit pentru testarea aplicațiilor web, Selenium poate fi folosit pentru orice sarcină care necesită automatizarea interacțiunii cu browserul. Aceasta poate include web-scraping.
Următorul tutorial va fi un ghid condus de utilizatori cu cele mai bune practici pentru web-scraping folosind seleniu. Am enumerat cele mai bune 5 sfaturi ale mele care vor ajuta utilizatorul să răzuiască orice date pe care le solicită cât mai eficient posibil folosind Python cu cât mai puțin cod posibil.
Scop:
Pentru a extrage titlurile globale despre Coronavirus din știrile BBC.
Cerințe preliminare
Pentru a urma acest tutorial, va trebui să:
- Descărcați un driver web selenium. Driverul Chrome poate fi folosit pentru a interacționa cu Chrome și este disponibil „aici”.
pip install selenium
5 Sfaturi de bune practici pentru seleniu
Sfat 1: plasați executabilul webdriver în PATH
Pentru a începe sarcina noastră de web scraping, trebuie mai întâi să navigăm la următoarea pagină, „https://www.bbc.co.uk/news””. Acest pas poate fi realizat în doar trei linii de cod. Mai întâi importăm webdriver-ul din selenium, creăm o instanță a webdriver-ului Chrome și, în sfârșit, apelăm metoda get pe obiectul webdriver numit driver.
Pentru a face acest cod scurt și lizibil, executabilul chromedriver poate fi plasat într-un folder ales de utilizator. Această destinație poate fi apoi adăugată la PATH sub variabilele de mediu. Webdriver-ul este apoi gata de funcționare, folosind pur și simplu webdriver.Chrome() fără argumente transmise Chrome în paranteze.
Sfat 2. Găsiți orice element web folosind consola
Când am navigat la pagina web, am dori să găsim caseta de căutare, să facem clic pe ea și să începem să tastați pentru „actualizări globale de coronavirus”.
Pentru a găsi acest element web, putem pur și simplu, faceți clic dreapta pe Chrome și selectați inspectați. În colțul din stânga sus al paginii care se deschide când inspectăm, putem folosi cursorul pentru a trece cu mouse-ul peste și a selecta elementele web de interes. După cum se arată, caseta de căutare are o etichetă de intrare, cu o valoare de id „orb-search-q”.
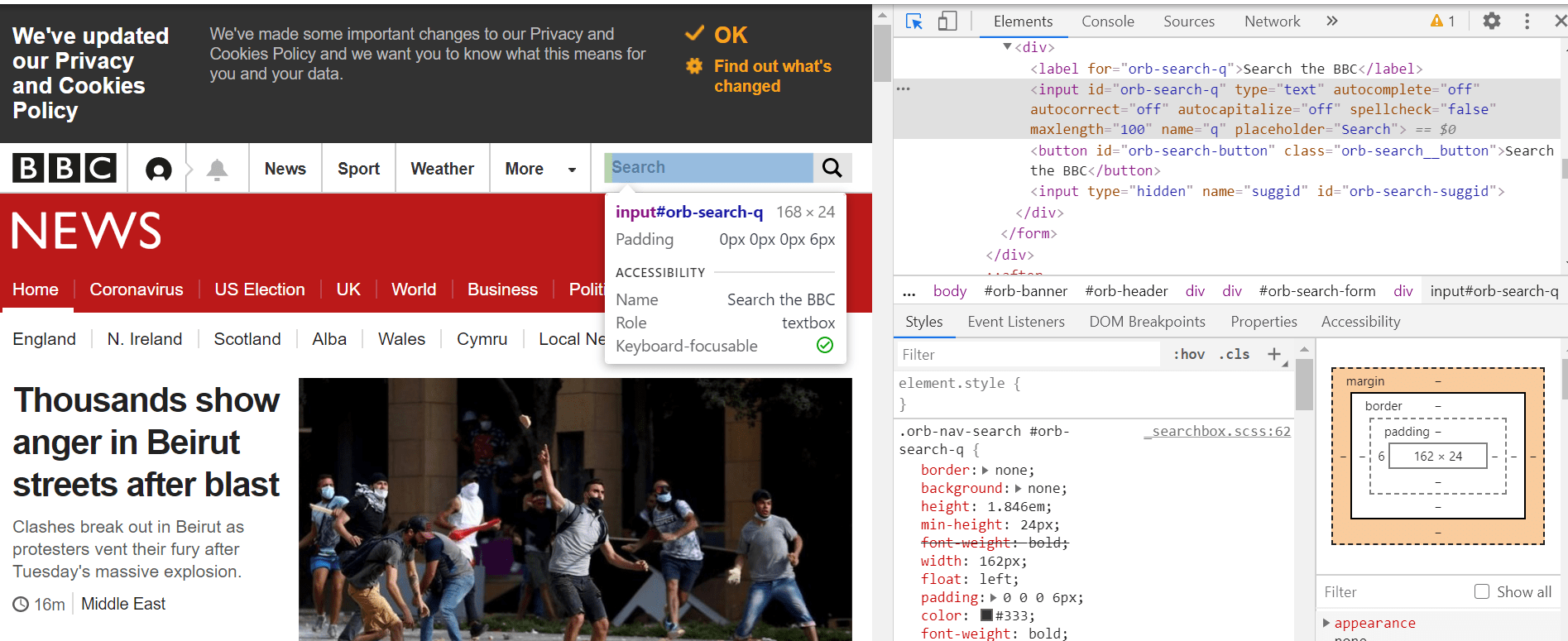
Cum ne putem asigura că acesta este singurul element de căutare care ne interesează?
Putem pur și simplu să selectăm fereastra filei console și apoi să introducem două semne de dolar, urmate de paranteze și citate. În ghilimele, scriem introducerea etichetei urmată de paranteze pătrate. În acele paranteze pătrate putem adăuga id-ul și valoarea acestuia.
Format to find CSS selectors
$$('tag[attribute="attribute value"]')
După cum se arată, este returnată o matrice de un singur element. Putem fi siguri că acum avem caseta de căutare potrivită pe care să facem clic și să începem să introducem interogările noastre de căutare.
Conținutul ghilimelelor din consolă este un selector CSS valid și îl putem folosi în scriptul nostru pentru a găsi elementul web.
Acest lucru duce la următorul sfat.

Sfat 3: Scraping puternic de date One-liners: ActionChains și Keys
Acum putem apela metoda find_element_by_css_selector pe driverul obiectului webdriver.
Dorim ca driverul nostru web să treacă la acest element web, să faceți clic pe el, să introduceți interogarea noastră de căutare „Actualizări globale de coronavirus” și să apăsați pe Enter.
Acest lucru poate fi realizat cu ușurință folosind clasele ActionChains și Keys din selenium. Pur și simplu trecem driverul la ActionChains și lanțul de metode folosind metodele move_to_element, click, send_keys pentru a introduce intrare și key_downcu Keys.ENTER transmis pentru a imita enter. Pentru a rula această comandă, adăugați metoda perform la sfârșitul ActionChain.
Rularea ActionChain ne duce aici:

Sfat 4: Capturarea datelor
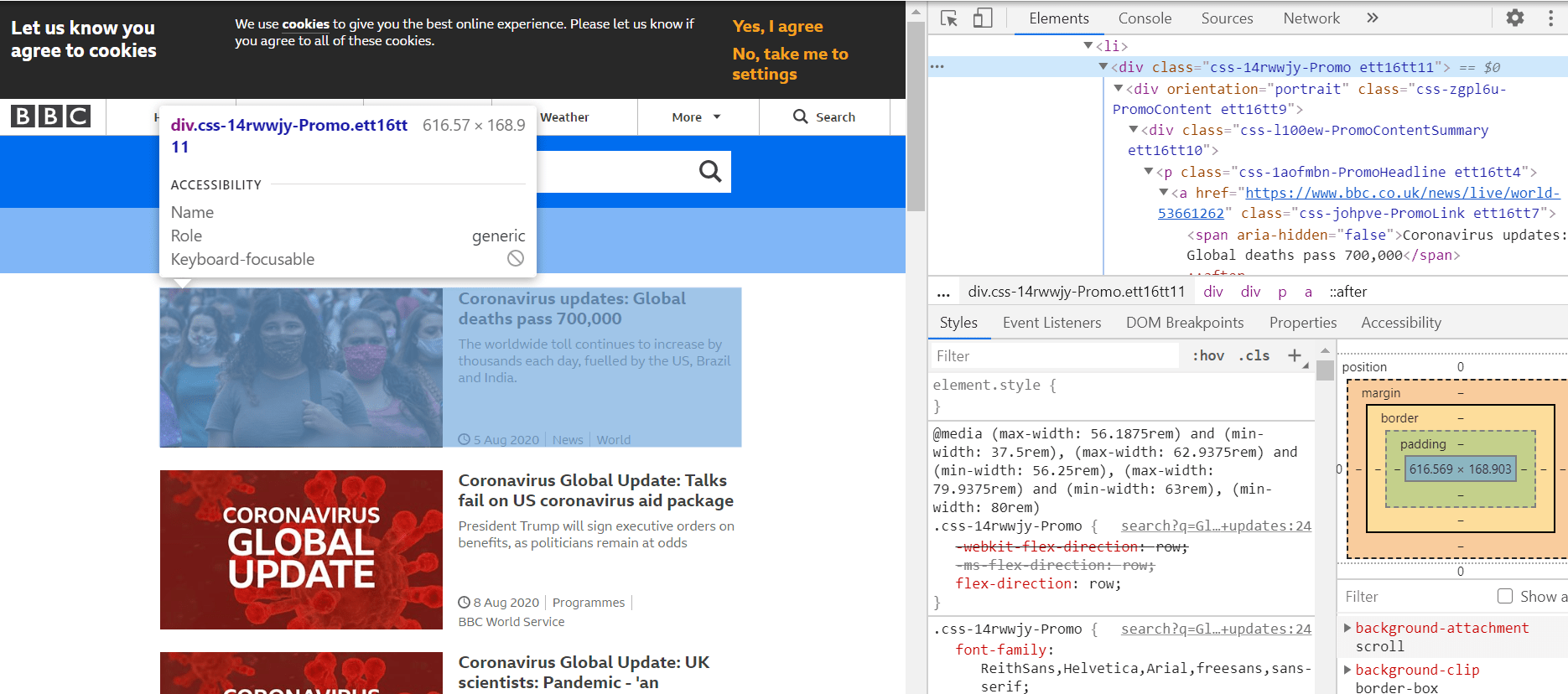
Elementul web afișat returnează o imagine, un titlu, un subtitlu și câteva informații accesorii, cum ar fi data publicării.
Cum putem surprinde doar titlul din fiecare poveste?
Dacă introducem elementul web afișat mai jos în consolă, acesta va returna o listă de 10 elemente web. Vrem să extragem doar titlul din fiecare dintre aceste povești.
Pentru a face acest lucru, putem repeta simplu peste cele 10 povești. Pentru a face acest lucru, apelăm find_elements_by_css_selectorcu elementul web trecut. Această metodă returnează un obiect asemănător unei liste pe care îl putem itera.
Putem atribui aceasta variabilei numelui top_titles și să iterăm peste ele folosind o buclă for. În bucla for putem găsi elementul asociat fiecărui titlu folosind Sfatul numărul 2 și extragem textul apelând .text pe elementul web.
Pe lângă tipărirea pe consola terminalului, putem scrie și într-un fișier .txt, astfel încât să avem o copie permanentă a titlurilor ori de câte ori rulăm scriptul.
Sfat 5: driver web fără cap
Când rulăm scriptul pentru a extrage titlurile, va apărea o fereastră de browser și va rula așa cum se arată în videoclipul de mai jos.
Deși acest lucru poate fi interesant de urmărit, în cea mai mare parte, acest lucru poate să nu fie dorit.
Pentru a elimina browserul, importați clasa Opțiuni din modulul selenium, creați o instanță a acestei clase și apelați metoda add_argument pe această instanță cu argumentul șir „ — headless” transmis. În cele din urmă, în webdriver, sub parametrul opțiuni, adăugați variabila care indică browserul fără cap.
Sfat bonus: adăugați așteptări pentru a găsi elemente în cazurile de conexiune lentă
Webdriver wait, By și wait_conditions
Pentru a ne asigura că webscraping are succes, putem introduce o așteptare în scriptul nostru. Această caracteristică poate fi deosebit de utilă în cazurile în care paginile web se încarcă lent. Pentru a face acest lucru, importăm cele trei clase afișate.
Ceea ce este frumos la introducerea așteptărilor este că, atunci când sunt construite, pot fi aproape scrise ca o propoziție. În plus, ei pot căuta elementul web atât timp cât alegem noi. Dacă elementul web este găsit mai devreme, scriptul pur și simplu se execută și mai devreme.
Aici, trecem clasa WebDriverWait, obiectul nostru driver, îi spunem să aștepte maxim 10 secunde, până când elementul este localizat. În metoda until, trecem clasaExpectedConditons cu aliasul EC și apelăm metoda prezenței elementului localizat pe ea. Apoi trecem acestei metode un tuplu de localizare, care detaliază ce element căutăm (By.CSS_SELECTOR) și elementul web.
O așteptare va face scripturile dvs. mai robuste și mai puțin susceptibile la excepțiile de expirare.
Scriptul pentru aceste exemple este prezentat complet aici.
Transformarea scriptului de automatizare într-o clasă
Cursul titlurilor Coronavirus
Când suntem siguri că automatizarea web funcționează conform intenției, acum putem transforma codul într-o clasă. Pentru a menține lucrurile simple pentru orice utilizator potențial al acestei clase, am decis să numesc clasa CoronaVirusHeadlines.
În initconstructor, am setat un atribut driver în obiect care indică driverul web Chrome.
Codul este exact același cu codul de procedură prezentat în secțiunile anterioare (cu excepția faptului că am eliminat opțiunea fără cap). Singura excepție este că driverul a fost setat ca atribut în obiect. Driverul este inițializat în metoda init și este folosit în metoda get_headlinespentru a prelua titlurile.
Pentru a obține titlurile, pur și simplu creez o instanță a acestei clase numită virus_data. Apoi apelez metoda get_headlines pe această clasă pentru a prelua titlurile într-un fișier .txt.
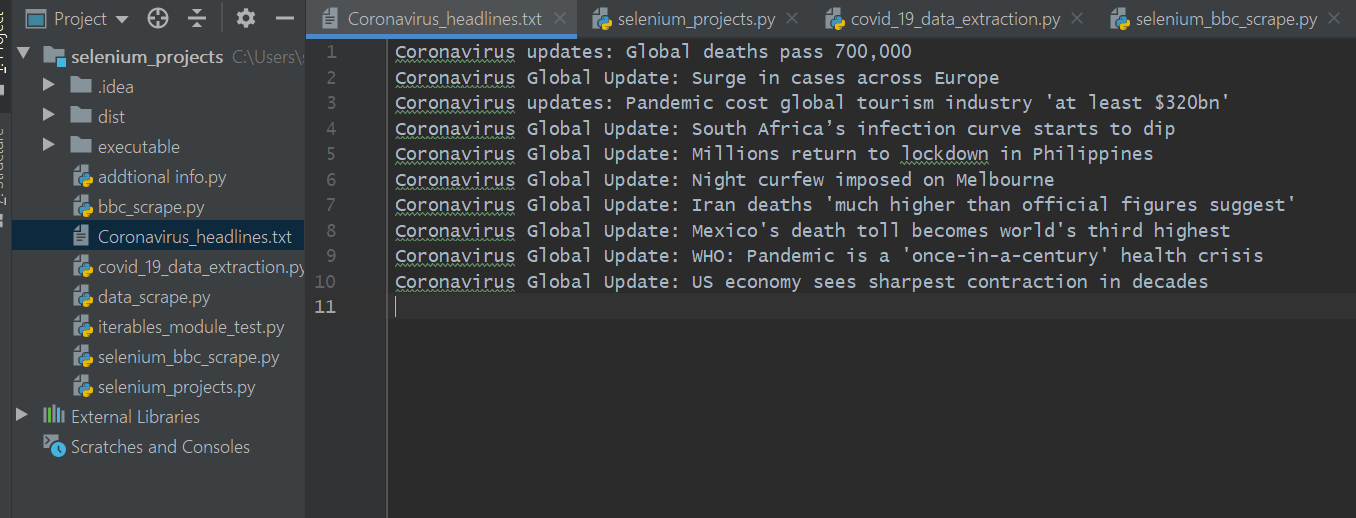
În directorul meu local, pot verifica acum fișierul numit „Coronavirus_headlines.txt”.
După cum se arată mai jos, titlurile au fost răzuite într-un fișier .txt. Vă rugăm să rețineți că, dacă executați singur codul, titlurile vor fi, desigur, diferite, deoarece pandemia de coronavirus evoluează continuu cu noi povești publicate pentru cotidianul BBC.
Rezumat și extensii
Acestea sunt câteva dintre cele mai bune sfaturi ale mele pentru răzuirea folosind seleniu. Unele sfaturi, inclusiv lanțul de acțiuni și sfaturi de așteptare, pot fi foarte lizibile și ușor de înțeles de către alții care vă pot citi și codul.
Scenariul ar putea fi ușor extins. De asemenea, puteți naviga pe a doua pagină pentru a prelua următoarele 10 titluri. Sau poate ai dori ca titlurile să fie trimise prin e-mail sau convertite într-un fișier executabil, astfel încât titlurile să poată fi partajate cu tine și cu colegii/prietenii tăi interesați, care s-ar putea să nu folosească neapărat Python. Acest lucru poate fi realizat folosind modulele smtplib sau, respectiv, PyInstaller .
Multumesc pentru lectura.