Analiza cuprinzătoare a algoritmilor de detectare a obiectelor

Prezentare generală
Mecanismul vizionar uman este fascinant. Senzorii vizuali percep o imagine și o transformă în semnale electrice, pe care le transmit sistemelor neuronale. Creierul procesează apoi semnalele, permițând în cele din urmă oamenilor să vadă, precum și să înțeleagă contextul unei imagini, inclusiv ce obiecte sunt în imagine și unde și câte dintre ele sunt. Toate aceste procese complexe au loc instantaneu. Dacă unuia i se dă un stilou și i se cere să deseneze o casetă în jurul tuturor obiectelor vizibile, acest lucru poate fi ușor de realizat.
Cu toate acestea, este îndoielnic dacă o mașină poate efectua acest proces la fel de eficient ca oamenii. Rețelele neuronale convoluționale (ConvNets sau CNN) sunt bune la extragerea de caracteristici dintr-o anumită imagine și în cele din urmă să o clasifice ca pisică sau câine. Acest proces este cunoscut sub numele de clasificare a imaginilor. Aceasta este o sarcină ușoară dacă obiectele sunt centrate și doar câteva obiecte sunt în imagine. Dacă numărul de obiecte este crescut și obiectele aparțin unor clase diferite, acestea trebuie să fie distinse și localizate în cadrul unei imagini. Acest lucru este cunoscut sub numele de detectarea și localizarea obiectelor. Zhao presupune că detectarea obiectelor este un proces de construire a unei înțelegeri complete, inclusiv clasificarea și estimarea conceptelor și locației obiectelor în fiecare imagine. (Zhao, et al., 2019). Detectarea obiectelor implică, de asemenea, sarcini secundare, cum ar fi detectarea feței, detectarea pietonilor și detectarea punctelor cheie. Aceste subsarcini alimentează numeroase aplicații, inclusiv analiza comportamentului uman, recunoașterea facială și conducerea autonomă (Zhao, et al., 2019).
În acest articol, mă concentrez pe algoritmii de detectare a obiectelor, care sunt algoritmi din familia R-CNN; R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN, SSingle Shot Multibox Detector (SSD), RetinaNet și YOLO strong> algoritmi de familie; YOLO, YOLO-9000, YOLOv3, YOLOv4 și YOLOv5.
Potrivit lui Bochkovskiy și colab., detectorii de obiecte au două părți principale: o coloană vertebrală antrenată pe ImageNet și un cap folosit pentru predictorii cutiei de delimitare. În primul rând, VGG, ResNet, ResNeXt și Darknet sunt folosite pentru platformele GPU, în timp ce SqueezeNet, MobileNet sau ShuffleNet sunt folosite pentru platformele CPU ca arhitectură „backbone”. Majoritatea detectoarelor de obiecte inserează straturi de conexiune între coloana vertebrală și cap pentru a colecta hărți de caracteristici din diferite etape. Acesta este cunoscut sub numele de „gât”. Pot fi utilizate diferite gâturi, cum ar fi Feature Pyramid Networks, PANet sau Bi-FPN. În funcție de detectorul de obiect, pot fi utilizate diverse „capete”, inclusiv YOLO, SSD sau RetinaNet ca detectoare cu o etapă sau familia R-CNN ca detectoare în două trepte (Bochkovskiy, et al., 2020).
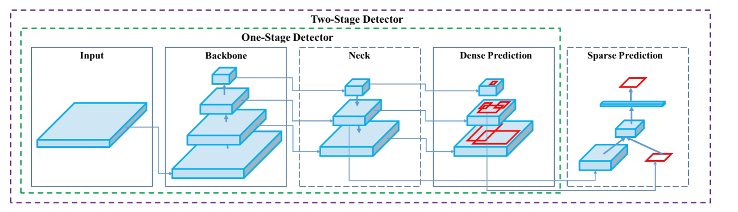
R-CNN-uri – Rețele neuronale convoluționale bazate pe regiune
R-CNN și Fast R-CNN
În prima versiune, rețelele neuronale convoluționale bazate pe regiune (R-CNN) au trei etape. Prima etapă este generarea propunerilor de regiune, care definește setul de detectări candidate. A doua etapă este extracția caracteristicilor pentru fiecare regiune, în timp ce etapa finală este clasificarea (Girshick, et al., 2013). Girshick şi colab. utilizați un algoritm de căutare selectivă pentru a genera propuneri de regiune și utilizați arhitectura AlexNet CNN ca un extractor de caracteristici. În etapa finală, caracteristicile extrase sunt introduse în SVM-uri liniare, care sunt optimizate pe clasă, pentru a clasifica prezența obiectelor în propunerea regiunii candidate. În plus față de prezicerea clasei propunerii de regiune, algoritmul prezice și patru valori, care sunt valori compensate pentru a crește precizia casetei de delimitare. Mai multe dezavantaje însoțesc algoritmii R-CNN. În primul rând, sunt lent de instruit, iar clasificarea fiecărei propuneri de regiune (~2000) per imagine este costisitoare. În al doilea rând, R-CNN nu poate fi utilizat în scenarii în timp real, deoarece este nevoie de aproximativ 47 de secunde pentru a testa o imagine. În al treilea rând, algoritmul de căutare selectivă al R-CNN este fix. Astfel, nu există învățare în această etapă, ceea ce poate duce la o propunere proastă de candidat.
În 2015, Girshick a propus o versiune îmbunătățită a R-CNN, cunoscută și sub numele de Fast R-CNN(Girshick, 2015).Această abordare este similar cu originalul, dar în loc să alimenteze propunerile de regiune către stratul convoluțional, imaginea originală este folosită pentru a genera o hartă a caracteristicilor convoluționale. Propunerile de regiune sunt identificate din harta caracteristicilor și apoi procesate de un strat de grup RoI(regiune de interes) pentru a le remodela într-o dimensiune fixă; acestea sunt apoi introduse într-un strat complet conectat. Există două straturi duble de ieșire. Primul strat emite distribuția de probabilitate discretă pe RoI pe categorii. Al doilea strat scoate decalările de regresie a casetei de delimitare. Acest lucru se realizează printr-o așa-numită pierdere de sarcini multiple.

Ca rezultat, din vectorul caracteristic RoI văzut în Figura 2, valorile de clasă și de offset sunt prezise pentru fiecare regiune propusă. O componentă importantă în Fast R-CNN este RoIPooling, care permite reutilizarea hărții caracteristicilor dintr-o rețea de convoluție anterioară; această tehnică îmbunătățește semnificativ timpul de pregătire și testare și permite unui sistem de detectare a obiectelor să fie antrenat end-to-end (Grel, 2017).
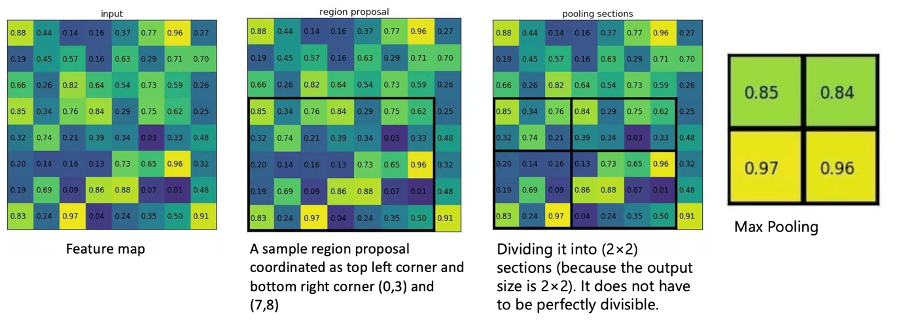
Problema cu Fast R-CNN este că încă folosește un algoritm de căutare selectivă pentru a genera propuneri de regiune. Deoarece acest proces este costisitor și consuma mult timp, generarea propunerii de regiune a devenit un blocaj pentru algoritm.
R-CNN mai rapid
În 2015, Ren et al. a propus Faster R-CNN, care elimină algoritmul de căutare selectivă pentru propunerile de regiune și utilizează Rețelele de propuneri regionale (RPN) pentru a afla propunerile de regiune (Ren, et al., 2015).
În lucrarea lor originală, Ren et al. utilizați modelul Zeiler și Fergus - care are 5 straturi convoluționale partajabile, precum și VGG16, care are 13 straturi convoluționale partajabile - ca extractoare de caracteristici, cunoscute și sub numele de coloana vertebrală. În implementarea PyTorch, Faster R-CNN utilizează ResNet cu FPN sau MobileNetV3 cu FPN ca extractoare de caracteristici; arhitectura este ilustrată în figura 4.

Rețeaua de propuneri de regiune (RPN) este o rețea mică care alunecă peste harta caracteristică convoluțională rezultată de ultimul strat convoluțional partajat. Acesta generează propuneri de obiecte dreptunghiulare cu scoruri de obiectitate prin luarea unei ferestre spațiale de 3 x 3 a hărților de caracteristici convoluționale de intrare generate de extractorul de caracteristici. La fiecare locație al ferestrei glisante, RPN generează k propuneri posibile diferite. Aceste k propuneri diferite duc la scoruri de obiectitate de 2k și coordonate de 4k. În plus, aceste k propuneri diferite sunt legate de o cutie de referință k diferită, denumită ancore. Aceste ancore vin în diferite dimensiuni și forme (Ren, et al., 2015). În lucrarea lor, Ren et al. precizați că au folosit 3 scale și 3 rapoarte de aspect, însumând 9 ancore. RPN-urile sunt antrenate prin atribuirea de etichete de clasă binare fiecărei ancori pentru a verifica dacă există sau nu vreun obiect. Etichetele pozitive sunt pentru ancorele cu cel mai mare IoU și pentru ancorele cu suprapunere IoU mai mare de 0,7 cu o casetă de adevăr la sol. Etichetele negative sunt atribuite unei ancori non-pozitive cu IoU 0,3 pentru toate casetele de adevăr la sol. Conform acestor definiții, funcția de pierdere pentru RPN este definită așa cum se arată în ecuația 1:

unde i este indicele unei ancore dintr-un mini-lot și pi este probabilitatea ca acea ancoră să aibă un obiect în ea. Eticheta de fond-adevăr p*i este 1 dacă ancora este pozitivă și este 0 dacă ancora este negativă; ti este vectorul reprezentând cele 4 coordonate parametrizate ale casetei de delimitare; iar t*i este cea a casetei de adevăr de bază asociată cu o ancoră pozitivă. Pierderea de clasificare este entropia încrucișată binară, iar pierderea de regresie este lină L1. Pierderea de regresie este activată numai pentru ancore pozitive unde p*i nu este zero. Pentru cele 4 coordonate casete de delimitare, sunt utilizați următorii parametri, așa cum sunt definiți în ecuația 2:
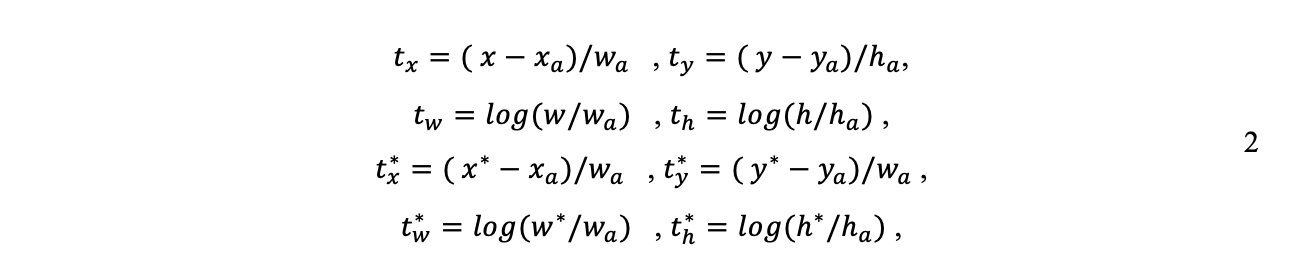
unde x și y reprezintă coordonatele centrale ale unei casete, iar h și w indică înălțimea și lățimea; x, xa și x* denotă căsuța de delimitare prezisă, ancora și adevărul de bază.
După ce RPN generează propuneri de regiune, Faster R-CNN utilizează, de asemenea, ROI Pooling - ca și în Fast R-CNN - pentru a combina propunerile regionale și hărțile caracteristicilor pentru sarcinile de detectare.
Mască R-CNN
El și colab. a dezvoltat Mask R-CNN în 2017, extinzând Faster R-CNN și adăugând o ramură pentru prezicerea măștii obiectului în paralel cu predicția cutiei de delimitare (He, et al., 2017). Masca R-CNN rulează la 5 fps. Scopul principal este segmentarea instanțelor. Noua ramură a modelului Mask R-CNN prezice pixeli prin măști de segmentare a pixelilor pe fiecare regiune de interes (RoI). RoIAlign este folosit în loc de RoIPool, deoarece nu necesită cuantizare și pentru că remediază dezalinierea și păstrează locațiile spațiale.
În implementarea PyTorch, Mask R-CNN utilizează ResNet cu FPN sau MobileNetV3 cu FPN ca extractoare de caracteristici; arhitectura este ilustrată în figura 5.

După cum se arată în Tabelul 1, Mask-RCNN depășește, de asemenea, Faster RCNN în sarcinile de detectare a obiectelor în mAP. El și colab. sugerează că această îmbunătățire se datorează RoIAlign (+1.1AP), instruirea multitask (+0.9AP) și ResNeXt101 (+1.6AP) (He, et al., 2017).

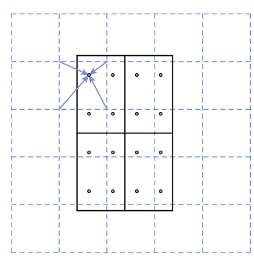
El și colab. propune RoIAlign pentru rezolvarea problemei de cuantificare cauzată de RoIPooling (RoIPool este introdus în Secțiunea 1.1.1.1. RoIAlign evită pur și simplu orice cuantificare a limitelor RoI; folosește interpolarea biliniară pentru a calcula valorile exacte ale caracteristicilor din fiecare bin RoI și agregează rezultatele. După cum se arată în Figura 6, grila întreruptă este harta caracteristicilor, în timp ce liniile continue sunt pentru regiunile de interes (RoI), iar cele patru puncte sunt punctele de eșantionare RoI calculează interpolarea biliniară a punctului din grila din apropiere Prin urmare, nu are loc nicio cuantizare în timpul acestor operații.
Masca R-CNN folosește aceeași funcție de pierdere ca Faster R-CNN. În plus, are o pierdere de mască așa cum este definită de ecuația 3:

Lcls și Lbox sunt definite ca în Faster R-CNN. Ramura masca are o masca binara K pentru fiecare ROI, iar fiecare masca este o rezolutie m x m care este rezultatul iesirii dimensionale Km2 pentru fiecare ROI. Prin urmare, este posibil să se creeze măști pentru fiecare clasă de către rețea, ceea ce împiedică competiția între clase. El și colab. aplicați sigmoid per pixel și folosit Lmask ca pierdere binară de entropie încrucișată (He, et al., 2017).
Detector MultiBox cu o singură lovitură (SSD)
Detectoarele de obiecte bazate pe regiune, cum ar fi familia R-CNN, necesită cel puțin detectoare de obiecte în 2 etape, unde prima etapă este generarea propunerii, iar a doua etapă constă în detectarea obiectelor pentru fiecare propunere. Detectorul MultiBox Single Shot, cunoscut și sub numele de SSD, este un detector cu o singură etapă, ceea ce înseamnă că atât localizarea obiectelor, cât și clasificarea sunt finalizate într-o singură trecere de tip feed-forward a rețelei care produce o colecție de dimensiuni fixe de cutii de delimitare și scoruri pentru prezența instanțelor clasei de obiecte, urmată de o suprimare non-max pentru a elimina aceleași detecții pentru un obiect (Liu, et al., 2016). SSD rulează la 59 de cadre pe secundă (FPS), cu o mAP de 74,3% pe setul de date de testare VOC2007. Prin comparație, Faster R-CNN a rulat la 7 FPS cu o mAP de 73,2%, în timp ce YOLO a rulat la 45 FPS cu o mAP de 63,4% (Liu, et al., 2016).
Potrivit lui Liu et al. cea mai mare îmbunătățire vine din eliminarea propunerilor de casete de delimitare și reeșantionarea caracteristicilor. Contribuțiile SSD-ului sunt triple. În primul rând, este mai rapid și semnificativ mai precis decât detectorul de ultimă oră (YOLO). În al doilea rând, prezice scorurile categoriei și decalajele casetei de delimitare pentru un set fix de bbox implicite, folosind mici filtre convoluționale aplicate hărților caracteristici. În al treilea rând, generează predicții pentru diferite scale din hărți de caracteristici de diferite scale și separă predicțiile în funcție de raportul de aspect.
Arhitectura SSD-ului se bazează pe VGG-16, deși elimină straturile complet conectate. Straturi convoluționale suplimentare sunt adăugate pentru a extrage caracteristici de la diferite scale și pentru a reduce progresiv dimensiunea intrării la fiecare strat. Acest lucru este declarat ca hărți de caracteristici multi-scale pentru detectare. SSD calculează scorurile de locație și de clasă folosind filtre convoluționale mici, care sunt 3x3 și produc fie un scor pentru o categorie, fie un decalaj de formă în raport cu coordonatele implicite ale casetei pentru fiecare celulă (Liu, et al., 2016). Aceste filtre sunt cunoscute ca predictori convoluționali pentru detectare. SSD utilizează casete de delimitare implicite, cum ar fi ancore în Faster R-CNN.

Liu și colab. descrie, de asemenea, o tehnică numită hard negative mining, care folosește câteva exemple negative și pozitive în timpul antrenamentului. Deoarece majoritatea casetelor de delimitare au intersectare peste unire (IoU) scăzută și sunt interpretate ca exemple negative, Liu și colab. utilizați un raport de 3:1 între exemplele negative și exemplele pozitive pentru a echilibra exemplele de antrenament. Acest lucru ajută, de asemenea, rețeaua să învețe detectările incorecte (Liu, et al., 2016).
Tehnicile de creștere a datelor sunt, de asemenea, aplicate, cum ar fi inversarea și corecția, ca în multe alte aplicații de rețea neuronală. Liu și colab. utilizați răsturnarea orizontală cu o probabilitate de 0,5 pentru a vă asigura că obiectele potențiale apar atât în stânga, cât și în dreapta cu o probabilitate similară.
Funcția de pierdere pentru modelul SSD este o sumă ponderată a pierderii de localizare (loc) și a pierderii de încredere (conf), așa cum este descris în ecuația 4:

unde x este indicatorul pentru potrivirea casetei implicite cu adevărul de bază; l este caseta prezisă, iar N este numărul de casete implicite potrivite cu adevărul de bază. Pierderea încrederii este rezultatul SoftMax pe mai multe confidențe de clasă ©, în timp ce pierderea de localizare este pierderea Smooth L1 între caseta prezisă și adevărul de la sol (Liu, et al., 2016).
RetinaNet
Pierderea focală pentru detectarea obiectelor dense, cunoscută și sub numele de RetinaNet, a fost propusă în 2018 de Lin și colab. Potrivit Lin și colab., motivul din spatele preciziei mai scăzute a detectorilor cu o etapă este dezechilibrul extrem de clasă din prim-plan-fond. Dezechilibrul de clasă este abordat în familia R-CNN și în celelalte detectoare cu două trepte. Starea propunerii, cum ar fi propunerile de căutare selectivă sau RPN, este responsabilă pentru filtrarea majorității eșantioanelor de fundal prin restrângerea numărului de locații de obiect candidat la un număr mic (1–2k), în timp ce detectoarele cu o singură etapă trebuie să proceseze ~100k. În a doua etapă, euristicile de eșantionare, cum ar fi raportul fix prim-plan-fond (1:3) sau extragerea de exemple concrete online ajută la echilibrarea prim-planului și fundalului. Deși detectoarele cu o singură etapă aplică bootstrapping sau exemplu greu de minerit, Liu și colab. susțin că aceste tehnici sunt insuficiente pentru a face față acesteia. Prin urmare, Lin și colab. propune pierderea de entropie încrucișată remodelată astfel încât să reducă pierderea pentru a obține o pierdere bine clasificată (Lin, et al., 2018).

RetinaNet folosește ResNet + Feature Pyramid Network (FPN) ca coloană vertebrală, care este responsabilă pentru extragerea hărților de caracteristici bogate și multi-scală din întreaga imagine. RetinaNet se bazează apoi pe o subrețea pentru predicția clasei și pe alta pentru predicția cutiei de delimitare. După cum se vede în Tabelul 2, RetinaNet este primul detector cu o etapă care bate detectorii cu două trepte nu numai în timp de inferență (FPS), ci și în acuratețe la momentul său.

Pierderea focală a fost propusă pentru a rezolva dezechilibrul dintre clasele din prim-plan și din fundal. După cum au afirmat Lin și colab., factorul de cântărire este o metodă comună pentru modificarea entropiei încrucișate (Lin, et al., 2018). Prin urmare, adaugă un factor de modulare (1-pt)y, unde este parametrul de focalizare:


Te uiți doar o dată (YOLO) Familie
YOLO, V1
Algoritmul YOLO a fost propus pentru prima dată în 2015 de către Redmon și colab. Adoptă o abordare diferită față de alți algoritmi de detectare a obiectelor din acel moment. Acesta încadrează detectarea obiectelor ca o problemă de regresie, în timp ce altele folosesc o abordare de clasificare. Redmon și colab. argumentează că, deoarece o singură rețea prezice atât caseta de delimitare, cât și probabilitățile de clasă într-o singură trecere, ea poate fi optimizată de la capăt la capăt (Redmon, et al., 2015).
YOLO (v1) poate procesa imagini la 45 FPS, iar o versiune mai mică a lui YOLO poate procesa imagini la 155 FPS, obținând totuși dublul mAP față de alte detectoare de obiecte în timp real (Redmon, et al., 2015).
Ideea din spatele algoritmului YOLO este de a lua o imagine ca intrare și de a o împărți în celule care pot fi imaginate suprapuse unei grile (S x S); dacă centrul unui obiect cade într-o celulă grilă, acea celulă grilă este responsabilă pentru predicții.

Fiecare celulă de grilă generează casete de delimitare B și un scor de încredere pentru acele casete, reflectând încrederea modelului în legătură cu caseta, dacă conține sau nu un obiect. Redmon și colab. formulați încrederea ca în Formula 6 (Redmon, et al., 2016):
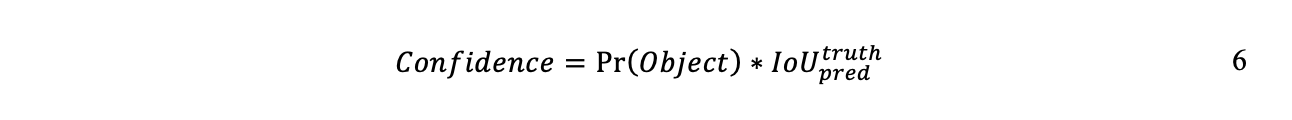
Conform acestei formule, dacă nu este prezent niciun obiect în celulă, atunci scorul de încredere ar trebui să fie zero. Dacă un obiect este prezent în celulă, atunci probabilitatea este 1, iar încrederea este egală cu IoU dintre caseta de delimitare prezisă și adevărul de bază.
După cum sa menționat mai sus, fiecare celulă prezice caseta de delimitare B și există 5 valori pentru fiecare casetă de delimitare. Acestea sunt x, y, w și h ale casetei de delimitare, precum și scorul de încredere. (x, y) este centrul casetei de delimitare, în timp ce w și h sunt lățimea și înălțimea casetei de delimitare în raport cu întreaga imagine. Împreună cu caseta de delimitare, fiecare celulă de grilă prezice și probabilitățile de clasă dacă există un obiect - cu alte cuvinte, probabilitățile de clasă C-condițională Pr(Classi | Object) - astfel încât formula este redată după cum urmează (Redmon, et al. , 2015):
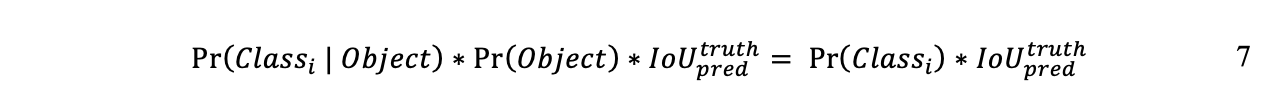
Predicțiile totale pentru o imagine sunt egale cu S x S x (B * 5 + C). În lucrarea lor, Redmon et al. afirmă că au folosit S=7 și B=2 pe setul de date PASCAL VOC, care are 20 de clase; astfel, predicția finală este un tensor 7 x 7 x 30. În etapa finală, YOLO aplică suprimarea non-max pentru a elimina duplicatele (Redmon, et al., 2016).

YOLO v1 are 24 de straturi convoluționale și 2 straturi complet conectate, așa cum este inspirat de GoogLeNet. Cu toate acestea, în loc de module de inițiere, YOLO utilizează un strat de reducere 1x1 urmat de straturi convoluționale 3x3. Straturile convoluționale sunt preantrenate pe ImageNet la jumătate de rezoluție (224 x 224) și apoi dublează rezoluția pentru detectare.
YOLO v1 are limitări cunoscute la momentul său. Deoarece fiecare celulă de grilă prezice doar două casete de delimitare și o clasă, este dificil să detectați obiecte apropiate. De asemenea, este dificil pentru YOLO v1 să detecteze obiecte mici. Funcția de pierdere creează un risc de erori duplicate atât pentru obiectele mari, cât și pentru cele mici. Micile erori asupra obiectelor mici au un efect mai mare.
YOLO utilizează funcția de pierdere în mai multe părți, care este suma pierderii de localizare, pierderea încrederii și pierderea de clasificare. Pierderea de localizare măsoară erorile în locațiile și dimensiunile casetelor de delimitare prezise;
pune mai mult accent pe precizia casetei de delimitare. În plus, măsoară pierderea încrederii dacă există un obiect în celulă; aceasta este denumită obiectitate. Dacă este detectat un obiect, pierderea de clasificare prezice clasa obiectului din fiecare celulă prin calcularea erorii pătrate a probabilităților condiționate de clasă pentru fiecare clasă.

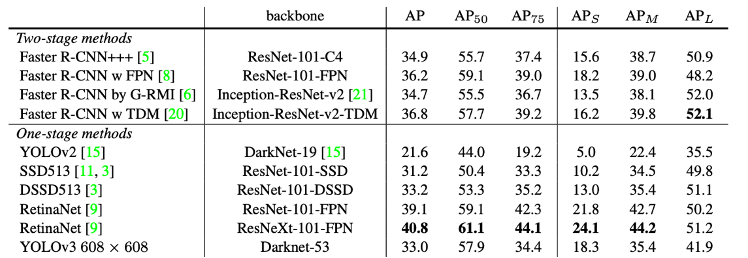
La momentul în care a fost propus YOLO, a depășit detectoarele în două etape atât în mAP, cât și în FPS, așa cum se vede în tabelul 3.

YOLO v2 (YOLO 9000)
SSD a fost un concurent puternic atunci când a fost propus. YOLO a avut erori de localizare mai mari, în timp ce reamintirea – care măsoară cât de bine localizează toate obiectele – a fost mai mică. Astfel, YOLO v2 are ca scop îmbunătățirea reamintirii și a localizării, menținând în același timp acuratețea clasificării (Redmon & Farhadi, 2016).
Redmon și Farhadi folosesc mai multe tehnici pentru a îmbunătăți YOLO v2, descriind în lucrarea lor calea de la YOLO la YOLO v2. Prima dintre aceste tehnici este normalizarea loturilor, care aduce o îmbunătățire semnificativă a convergenței și elimină alte metode de normalizare. Prin aplicarea normalizării loturilor, Redmon și Farhadi au obținut o îmbunătățire cu 2% a mAP și au eliminat abandonul; normalizarea lotului a îmbunătățit, de asemenea, regularizarea și a prevenit supraadaptarea. A doua tehnică este utilizarea unui clasificator de rezoluție mai mare. Toate detectoarele de obiecte de ultimă generație folosesc clasificatoare pre-antrenate pe ImageNet. În YOLO v1, acesta este 224 x 224; dar în YOLO v2, rețeaua de clasificare este antrenată pe ImageNet cu imagini de intrare la rezoluție 448 x 448 pentru 10 epoci. O rezoluție mai mare produce o creștere suplimentară de 4% a mAP. A treia tehnică este convoluția cu cutii de ancorare, ca în Faster R-CNN: rețeaua prezice doar compensații pentru cutiile de ancorare date manual (precedente). Prin urmare, Redmon și Farhadi elimină straturile complet conectate și folosesc cutii de ancorare pentru a prezice casetele de delimitare. Un strat de grupare este eliminat pentru a crește rezoluția, iar imaginea este redusă la 416 x 416 în loc de 448 x 448. Motivația acestui proces de micșorare este utilizarea unui număr impar de locații din grilă pentru a garanta o singură celulă centrală. YOLO eșantionează imaginea cu un factor de 32; prin urmare, 448 se termină cu 14, în timp ce 416 se termină cu 13. În cele din urmă, Redmon și Farhadi susțin că ar putea obține rezultate mai bune, începând cu cutii de ancorare mai bune. Prin urmare, folosesc gruparea k-means pe setul de date pentru a găsi casetele de ancorare.

În loc să prezică decalajul în funcție de casetele de ancorare, Redmon și Farhadi folosesc predicția directă a locației, care este decalată față de grilă. Acest lucru ajută la rezolvarea instabilității modelului în timpul iterațiilor timpurii. Pentru fiecare casetă de delimitare, 5 coordonate (tx, ty, tw, th și to) sunt prezise de rețea. Dacă celula este compensată cu (cx, cy) din colțul din stânga sus și dacă lățimea casetei de ancorare (pw) și înălțimea (ph), atunci predicțiile pentru caseta de delimitare și obiect sunt următoarele:

Redmon și Farhadi folosesc, de asemenea, caracteristici cu granulație fină, care sunt caracteristicile din straturile anterioare. Alți detectoare de obiecte folosesc scale diferite care contribuie la predicții. Prin urmare, Redmon și Farhadi aplică, de asemenea, o abordare similară utilizând caracteristici din straturi anterioare la 26x26; ele stivuiesc caracteristicile de la rezoluție înaltă și rezoluție joasă, cum ar fi mapările de identificare, ca în ResNet. Ei folosesc, de asemenea, antrenament pe mai multe scari, care presupune modificarea dimensiunii intrării în timpul antrenamentului. Ei raportează că folosesc un set de multipli de 32 ({320, 352, …, 608}) și că acest regim obligă rețeaua să învețe să prezică mai eficient în diferite dimensiuni de intrare (Redmon și Farhadi, 2016).

Redmon și Farhadi folosesc, de asemenea, un extractor de caracteristici de bază personalizate, altul decât VGG-16. În timp ce VGG-16 este puternic și precis, este și complex - are 30,69 miliarde FLOP-uri pentru o singură trecere, în timp ce rețeaua personalizată proiectată pentru YOLO v2 are 8,52 miliarde FLOP-uri. Precizia rețelei personalizate este puțin mai slabă decât cea a VGG-16: în timp ce VGG-16 are o precizie de 90% pe ImageNet, rețeaua personalizată are o precizie de 88% (Redmon & Farhadi, 2016). Modelul final se numește Darknet-19, cu 19 straturi convoluționale și 5 straturi max-pooling.
Redmon și Farhadi folosesc, de asemenea, clasificarea ierarhică, care permite îmbinarea seturilor de date de clasificare și a seturilor de date de detectare, făcând etichete de imagini utilizabile. Clasificarea ierarhică și seturile de date combinate permit detectarea în timp real a obiectelor în peste 9000 de categorii de obiecte.
YOLO v3
În 2018, Redmon și Farhadi au propus mai multe actualizări ale algoritmului YOLO. YOLO v3 are o nouă arhitectură de rețea de extracție de caracteristici numită Darknet-53, care este o variantă a Darknet cu 53 de straturi antrenate pe ImageNet. Pentru detectarea sarcinilor, 53 de straturi suplimentare sunt stivuite pe acesta. Are 106 straturi complet convoluționale. Datorită acestei arhitecturi grele, nu este mai rapid decât YOLO-v2, deși este mai precis (Redmon & Farhadi, 2018). Redmon și Farhadi susțin că Darknet-53 este mai bun decât RestNet-101 și de 1,5 ori mai rapid, cu performanțe similare cu ResNet-152, deși de 2 ori mai rapid.

Cu noua sa arhitectură, YOLO v3 cu Darknet53 este mai bun decât SSD și aproape de RetinaNet de ultimă generație la AP50, deși de 3 ori mai rapid.
Din motive de performanță, Redmon și Farhadi actualizează predicția de clasă folosită în clasificatorii logistici independenți, în loc să utilizeze SoftMax. Cu această abordare, ei pot utiliza clasificarea cu mai multe etichete și pot rezolva problema etichetelor suprapuse (de exemplu, „femeie” și „persoană”). Ei propun, de asemenea, predicții pe scară în lucrarea lor. YOLO v3 generează predicții de delimitare la 3 scale diferite. Astfel, tensorul este S x S x [ 3 * (4+1 + 80)] pentru setul de date COCO pentru fiecare scară (Redmon & Farhadi, 2018). După cum se vede în Figura 14, predicția multi-scale ajută la detectarea obiectelor de la diferite scale. Ei folosesc gruparea k-means pe setul de date COCO pentru a găsi casetele de ancorare pentru fiecare scară, care sunt următoarele 9 casete de ancorare (3 pentru fiecare scară): (10×13), (16×30), (33×23) , (30×61), (62×45), (59×119), (116 × 90), (156 × 198) și (373 × 326) (Redmon & Farhadi, 2018).

De altfel, după ce a dezvoltat YOLO v3, Redmon a decis în 2020 să oprească cercetările privind viziunea computerizată din cauza aplicațiilor sale militare și a preocupărilor legate de confidențialitate.

YOLO v4
Bochkovskiy și colab. a continuat cercetarea algoritmului YOLO și a propus YOLO v4 în 2020. Contribuția lor a YOLO v4 constă în primul rând în dezvoltarea unui model eficient și puternic de detectare a obiectelor, verificarea metodelor de tip „bag-of-freebies” și „bag-of-specials” și modificarea stării -metode artistice pentru a rula pe un singur GPU pentru accesul tuturor. Ei au obținut rezultate excelente, cu 43,5% AP (65,7% AP50) pentru setul de date MS COCO la o viteză în timp real de 65 FPS (Bochkovskiy, et al., 2020), prin combinarea unora dintre următoarele tehnici: Conexiuni reziduale ponderate ( WRC), Cross-Stage Partial Connections (CSP), Cross-Mini-Batch Normalization (CmBN), Self-Adversarial Training (SAT), Mish Activation, Mosaic Data Augmentation și Drop Block regularizare.
Rețelele lor neuronale convoluționale au fost antrenate offline, cercetătorii dezvoltând modele și folosind tehnici pentru a ajuta la îmbunătățirea acurateței modelului la momentul inferenței, fără a afecta costul de inferență. Prin urmare, această abordare se numește pungă de cadouri.
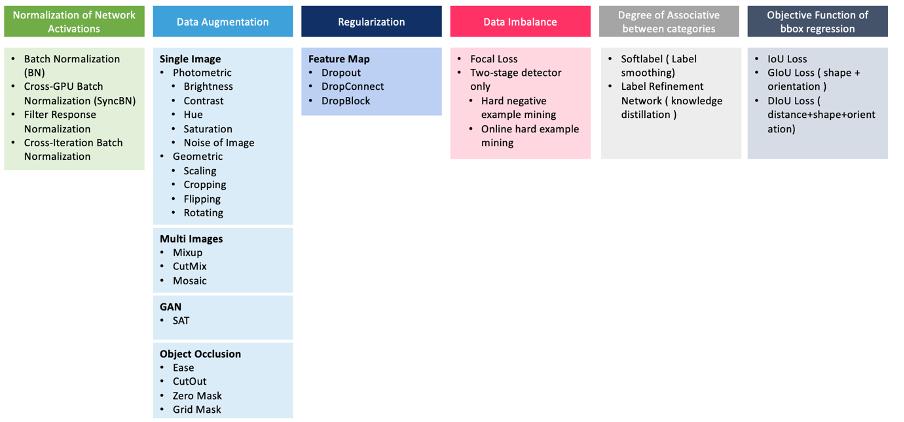
Mărirea datelor ajută la formarea unui model cu privire la variabilitatea imaginilor de intrare pentru a crește robustețea. Această abordare se bazează în principal pe distorsiuni fotometrice (cum ar fi modificarea luminozității, contrastului, nuanței, saturației și zgomotului unei imagini) și distorsiunilor geometrice (cum ar fi rotația, răsturnarea, decuparea și scalarea aleatorie); aceasta este una dintre tehnicile din categoria bag-of-freebies (Bochkovskiy, et al., 2020). Pe lângă mărirea pixelilor, unii cercetători propun procesarea mai multor imagini simultan prin aplicarea MixUp - care folosește două imagini pentru a se multiplica și suprapune la rapoarte diferite - sau CutMix, care acoperă unele părți ale imaginilor cu alte imagini și Mosaic care amestecă 4 imagini diferite. imagini de antrenament. După cum sa menționat mai devreme în ceea ce privește RetinaNet, seturile de date dezechilibrate/părtinitoare duc la modele cu performanțe scăzute; astfel, au o precizie scăzută. Pe de altă parte, datele etichetate pot fi greșite. Dacă un set de date este mic, atunci verificarea manuală poate fi o opțiune; dar pentru seturi de date mai mari, netezirea etichetei este o modalitate matematică de a îmbunătăți învățarea din eșantioane etichetate greșit dintr-un set de date (Szegedy, et al., 2015). Deși eroarea pătratică medie este utilizată în primul rând ca funcție de pierdere pentru problemele de regresie, Bochkovskiy și colab. de asemenea, menționați că coordonatele casetei de delimitare a firelor ca variabile independente ratează integritatea obiectului (Bochkovskiy, et al., 2020).
Bochkovskiy și colab. propune, de asemenea, o pungă de specialități, care crește marginal costurile de inferență, dar îmbunătățește semnificativ acuratețea detectării obiectelor.
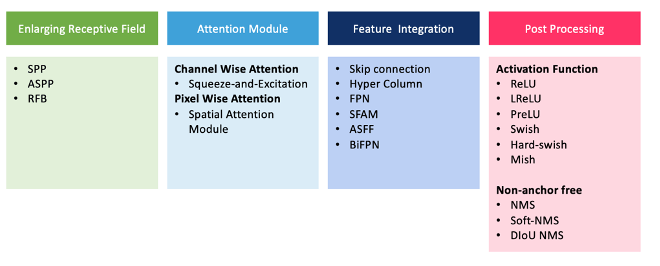
Câmpurile receptive care se extind sunt SSP (Spatial Pyramid Pooling), care a fost propus de He et al. pentru a elimina limitarea de intrare a rețelei de dimensiune fixă prin generarea de reprezentări cu lungime fixă ale imaginilor (He, et al., 2015), precum și ASPP (Atrous Spatial Pyramid Pooling) - care a fost propus de Chen et al. (Chen, et al., 2017) pentru a ajuta la lărgirea eficientă a câmpului vizual al filtrelor pentru a încorpora un context mai larg, fără a crește semnificativ numărul de parametri sau cantitatea de calcul - și RFB(Receptive Field Block) , care a fost propus de Liu et al. și a fost inspirat din sistemele vizuale umane. RFB ia în considerare relația dintre dimensiunea și excentricitatea câmpurilor receptive pentru a spori discriminabilitatea și robustețea caracteristicilor (Liu, et al., 2018).
Modulele de atenție - în primul rând modulul de atenție în funcție de canal și modulul de atenție în funcție de pixeli - sunt de asemenea utilizate în detectarea obiectelor. Squeeze-and-Excitation, reprezentantul atenției canalului, a fost propus de Hu și colab. pentru a permite modelelor/rețelelor să construiască caracteristici informative prin aducerea de informații spațiale și de canal în câmpurile receptive locale la fiecare strat (Hu, et al., 2019). După cum Bochkovskiy și colab. raportul, modulul SE este costisitor pentru GPU (+10% cost), deși poate fi utilizat pentru CPU/dispozitive mobile (+2% cost) (Bochkovskiy, et al., 2020). SAM(Modulul de atenție spațială), care este reprezentantul atenției în funcție de pixeli, a fost propus de Woo și colab. ca element de bază pentru Modulul de atenție a blocului convoluțional (Woo, et al., 2018). SAM generează o mască care îmbunătățește caracteristicile importante care definesc obiectul și rafinează hărțile caracteristicilor.
Integrarea caracteristicilor, cum ar fi ignorarea conexiunilor și FPN, ajută la integrarea funcțiilor de nivel scăzut cu funcțiile de nivel înalt. Funcțiile de activare oferă neliniaritate, iar scopul selectării unei activări este de a determina propagarea inversă eficientă a gradientului. Un alt proces de post-procesare este NMS (Non-Max Suppression), care este procesul de eliminare a cutiilor de delimitare cu scoruri mici.
Astfel, arhitectura YOLO v4 este următoarea: coloana vertebrală este CPDarknet53, gâtul este SPP și PAN, iar capul este același ca în YOLOv3. Abordările „bag-of-freebies” pentru backbone sunt CutMix, Mosaic Data Augmentation, regularizarea DropBlock și Label Smoothing. Tehnicile speciale pentru backbone sunt activarea Mish, conexiunile parțiale încrucișate (CSP) și conexiunile reziduale ponderate cu mai multe intrări (MiWRC). Tehnicile de tip „bag-of-freebies” pentru detector sunt CIoU-loss, CmBN, regularizarea DropBlock, creșterea datelor mozaice, Self-Adversarial Training, eliminarea sensibilității grilei, utilizarea mai multor ancore pentru un singur adevăr la sol, hiperparametri optimi pentru planificatorul de recoacere cosinus și forme aleatorii de antrenament. Tehnicile speciale pentru detector sunt activarea Mish, blocul SPP, blocul SAM, blocul de agregare a căii PAN și DIoU-NMS (Bochkovskiy, et al., 2020).
Într-o discuție pe Github.com, Bochkovskiy a precizat contribuția mAP a tehnicilor bag-of-freebies și bag-of-specials, cum ar fi SPP (+3%), CSP+PAN (+2%), SAM (+0,3%) , CIoU+S (+1,5%), Mozaic și reglaj hiperparametru (+2%), Ancore scalate (+1%), însumând aproximativ +10% în total (Bochkovskiy, 2020). Astfel, 5% din îmbunătățirea totală provine din arhitectură, cu încă 5% din pachetele gratuite (Bochkovskiy, 2020).
YOLO v5
YOLO v4 a constituit un salt major înainte față de YOLO v3. Doar câteva luni mai târziu, pe 9 iunie 2020, Glenn Jocher — care a fost menționat în lucrarea YOLO v4 pentru creșterea datelor Mosaic de către Bochkovskiy și colab. și care a contribuit în mod semnificativ la arhitectura YOLOv3 (peste 2000 de comite și aducerea mAP din 33). la 45.6.) — a lansat YOLO v5 fără o hârtie oficială. Pur și simplu a deschis YOLO v5 pe Github.com (Jocher, 2020).

YOLOv5 nu este bazat pe Darknet, dar este implementat în întregime în PyTorch. Conform rezultatelor mAP afișate pentru YOLO v4 pe setul de date MS COCO, valorile mAP YOLO v5 sunt aproape la fel de mari. Cel mai mare model, YOLO v5x, are o valoare a mAP puțin mai mare (Kin-Yiu, 2020).

Jocher a discutat, de asemenea, performanța antrenamentului pe Github.com Repo/Issues, afirmând că „cel mai mic YOLOv5 al nostru se antrenează pe COCO în doar 3 zile pe un 2080Ti și rulează inferența mai rapid și mai precis decât EfficientDet D0, care a fost antrenat pe 32 de nuclee TPUv3 de către Echipa Google Brain. Prin extensie, ne propunem să depășim în mod comparabil D1, D2 etc. cu restul familiei YOLOv5” (Jocher, 2020)
În următorul articol, voi trece în revistă performanțe de instruire și inferență pe diferite platforme hardware.
Rămâneţi aproape!
Referințe
Ahmad, R., 2020. Totul despre YOLO — Partea 4 — YOLOv3, o îmbunătățire incrementală. [Online]
Disponibil la: https://medium.com/analytics-vidhya/all-about-yolos-part4-yolov3-an-incremental-improvement-36b1eee463a2
Bochkovskiy, A., 2020. Github.com , YOLOv5 Despre rezultatele reproduse Discuție. [Online]
Disponibil la: https://github.com/ultralytics/yolov5/issues/6#issuecomment-643644347
Bochkovskiy, A., Wang, C.-Y. & Liao, H.-Y. M., 2020. YOLOv4: Viteza optimă și acuratețea detectării obiectelor. arXiv,Volum arXiv:2004.10934v1.
Chen, L.-C., Papandreou, G., Murphy, K. și Yuille, A. L., 2017. DeepLab: Segmentarea semantică a imaginii cu rețele de convoluție adâncă, convoluție atroasă și CRF-uri complet conectate. arXiv,Volum arXiv:1606.00915v2.
Girshick, R., 2015. Fast R-CNN. arXiv,Numărul 1504.08083v2.
Girshick, R., Donahue, J., Darrell, T. & Malik, J., 2013. Ierarhii bogate de caracteristici pentru detectarea precisă a obiectelor și segmentarea semantică. [Online]
Disponibil la: https://arxiv.org/pdf/1311.2524.pdf
Grel, T., 2017. Regiunea de pooling de interese explicată. [Online]
Disponibil la: https://deepsense.ai/region-of-interest-pooling-explained/
He, K., Gkioxari, G., Dollar, P. & Girshick, R., 2017. Masca R-CNN. arXiv,Volum arXiv:1703.06870v3.
He, K., Zhang, X., Ren, S. & Sun, J., 2015. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition.
Hu, J. și colab., 2019. Squeeze-and-Excitation Networks. arXiv,Volum arXiv:1709.01507v4.
Jocher, G., 2020. Github.com, Issues. [Online]
Disponibil la: https://github.com/ultralytics/yolov5/issues/2#issuecomment-642425558
Jocher, G., 2020. YOLOv5. [Online]
Disponibil la: https://github.com/ultralytics/yolov5
Kin-Yiu, W., 2020. Github.com. [Online]
Disponibil la: https://github.com/ultralytics/yolov5/issues/6#issuecomment-647069454
Lin, T.-Y.et al., 2018. Focal Loss for Dense Object Detection. arXiv,Volum arXiv:1708.02002v2.
Liu, S., Huang, D. & Wang, Y., 2018. Receptive Field Block Net for Accurate and Fast Object Detection. arXiv,Volum arXiv:1711.07767v3 .
Liu, W. et al., 2016. SSD: Detector MultiBox Single Shot.
Redmon, J., Divvala, S., Girshick, R. & Farhadi, A., 2015. You Only Look Once: Unified, Real-Time Object Detection. arXiv,Problema arXiv:1506.02640v5.
Redmon, J., Divvala, S., Girshick, R. & Farhadi, A., 2016. You Only Look Once: Unified, Real-Time Object Detection.
Redmon, J. & Farhadi, A., 2016. YOLO9000: Better, Faster, Stronger. arXiv,Problema arXiv:1612.08242v1.
Redmon, J. & Farhadi, A., 2018. YOLOv3: O îmbunătățire incrementală. arXiv,Volum arXiv:1804.02767v1.
Ren, S., He, K., Girshick, R. & Sun, J., 2015. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv,Volum 1506.01497v3.
Szegedy, C., Vanhoucke, V., Ioffe, S. & Shlens, J., 2015. Regândirea arhitecturii inițiale pentru viziunea computerizată. arXiv,Volum arXiv:1512.00567v3 .
Twitter, 2020. Twitter. [Online]
Disponibil la: https://twitter.com/pjreddie/status/1230524770350817280?s=20
Woo, S., Park, J., Lee, J.-Y. & Kweon, I. S., 2018. CBAM: Convolutional Block Attention Module. arXiv,Volum arXiv:1807.06521v2.
Zhao, Z.-Q., Zheng, P., Xu, S.-t. & Wu, X., 2019. Object Detection with Deep Learning: A Review. arXiv,Volum arXiv:1807.05511v2.