Folosind DeepShap pentru a înțelege și îmbunătăți modelul care alimentează o mașină autonomă

Mașinile autonome mă îngrozesc. Bucăți mari de metal zboară fără oameni care să-i oprească dacă ceva nu merge bine. Pentru a reduce acest risc nu este suficient să evaluăm modelele care alimentează aceste fiare. De asemenea, trebuie să înțelegem cum fac ei predicții. Acest lucru este pentru a evita orice cazuri marginale care ar provoca accidente neprevăzute.
Bine, deci cererea noastră nu este atât de importantă. Vom depana modelul folosit pentru a alimenta o mașină mini-automatizată (cel mai rău la care te-ai putea aștepta este o gleznă învinețită). Totuși, metodele IML pot fi utile. Vom vedea cum pot chiar să îmbunătățească performanța modelului.
Mai exact, vom:
- Ajustați ResNet-18 folosind PyTorch cu date de imagine și o variabilă țintă continuă
- Evaluați modelul folosind MSE și diagrame de dispersie
- Interpretați modelul folosind DeepSHAP
- Corectați modelul printr-o mai bună colectare a datelor
- Discutați cum mărirea imaginii ar putea îmbunătăți și mai mult modelul
Pe parcurs, vom discuta câteva părți cheie ale codului Python. De asemenea, puteți găsi întregul proiect pe GitHub.
Dacă sunteți nou la SHAP, vedeți videoclipulde mai jos. Dacă doriți mai multe, consultați cursul SHAP meu. Puteți obține acces gratuit dacă vă înscrieți la Buletinul meu informativ :)
Pachete Python
# Imports import numpy as np import pandas as pd import matplotlib.pyplot as plt import glob import random from PIL import Image import cv2 import torch import torchvision from torchvision import transforms from torch.utils.data import DataLoader import shap from sklearn.metrics import mean_squared_error
Setul de date
Începem proiectul prin colectarea datelor într-o singură cameră (aceasta va reveni să ne bântuie). După cum am menționat, folosim imagini pentru a alimenta o mașină automată. Puteți găsi exemple de acestea pe Kaggle. Aceste imagini au toate 224 x 224 pixeli.
Afișăm unul dintre ele cu codul de mai jos. Luați notă de numele imaginii (linia 2). Primele două numere sunt coordonate x și y în cadrul 224 x 224. În Figura 1, puteți vedea că am afișat aceste coordonate folosind un cerc verde (linia 8).
#Load example image
name = "32_50_c78164b4-40d2-11ed-a47b-a46bb6070c92.jpg"
x = int(name.split("_")[0])
y = int(name.split("_")[1])
img = Image.open("../data/room_1/" + name)
img = np.array(img)
cv2.circle(img, (x, y), 8, (0, 255, 0), 3)
plt.imshow(img)

Aceste coordonate sunt variabila țintă. Modelul le prezice folosind imaginea ca intrare. Această predicție este apoi folosită pentru a direcționa mașina. În acest caz, puteți vedea că mașina se apropie de o viraj la stânga. Direcția ideală este să mergi spre coordonatele date de cercul verde.
Antrenarea modelului PyTorch
Vreau să mă concentrez pe SHAP, astfel încât să nu intrăm în prea multă profunzime asupra codului de modelare. Dacă aveți întrebări, nu ezitați să le întrebați în comentarii.
Începem prin a crea clasa ImageDataset. Acesta este folosit pentru a încărca datele noastre de imagine și variabilele țintă. Face acest lucru folosind căile către imaginile noastre. Un lucru de subliniat este modul în care variabilele țintă sunt scalate - atât x, cât și y vor fi între -1 și1.
class ImageDataset(torch.utils.data.Dataset):
def __init__(self, paths, transform):
self.transform = transform
self.paths = paths
def __getitem__(self, idx):
"""Get image and target (x, y) coordinates"""
# Read image
path = self.paths[idx]
image = cv2.imread(path, cv2.IMREAD_COLOR)
image = Image.fromarray(image)
# Transform image
image = self.transform(image)
# Get target
target = self.get_target(path)
target = torch.Tensor(target)
return image, target
def get_target(self,path):
"""Get the target (x, y) coordinates from path"""
name = os.path.basename(path)
items = name.split('_')
x = items[0]
y = items[1]
# Scale between -1 and 1
x = 2.0 * (int(x)/ 224 - 0.5) # -1 left, +1 right
y = 2.0 * (int(y) / 244 -0.5)# -1 top, +1 bottom
return [x, y]
def __len__(self):
return len(self.paths)
De fapt, atunci când modelul este implementat, doar predicțiile x sunt folosite pentru a direcționa mașina. Din cauza scalarii, semnul predicției x va determina direcția mașinii. Când x ‹ 0, mașina ar trebui să vire la stânga. În mod similar, când x › 0 mașina ar trebui să vire la dreapta. Cu cât valoarea x este mai mare, cu atât virajul este mai clar.
Folosim clasa ImageDataset pentru a crea încărcătoare de date de instruire și validare. Acest lucru se realizează făcând o împărțire aleatorie 80/20 a tuturor căilor de imagine din camera 1. În cele din urmă, avem 1.217și 305 imagini din setul de instruire și respectiv de validare.
TRANSFORMS = transforms.Compose([
transforms.ColorJitter(0.2, 0.2, 0.2, 0.2),
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
paths = glob.glob('../data/room_1/*')
# Shuffle the paths
random.shuffle(paths)
# Create a datasets for training and validation
split = int(0.8 * len(paths))
train_data = ImageDataset(paths[:split], TRANSFORMS)
valid_data = ImageDataset(paths[split:], TRANSFORMS)
# Prepare data for Pytorch model
train_loader = DataLoader(train_data, batch_size=32, shuffle=True)
valid_loader = DataLoader(valid_data, batch_size=valid_data.__len__())
Observați batch_size a valid_loader. Utilizăm lungimea setului de date de validare (adică 305). Acest lucru ne permite să încărcăm toate datele de validare într-o singură iterație. Dacă lucrați cu seturi de date mai mari, poate fi necesar să utilizați un lot mai mic.
Încărcăm un model ResNet18 preantrenat (linia 5). Setând model.fc, actualizăm stratul final (linia 6). Este un strat complet conectat de la 512 noduri la cele 2 noduri variabile țintă. Vom folosi optimizatorul Adam pentru a regla acest model (linia 9).
output_dim = 2 # x, y
device = torch.device('mps') # or 'cuda' if you have a GPU
# RESNET 18
model = torchvision.models.resnet18(pretrained=True)
model.fc = torch.nn.Linear(512, output_dim)
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters())
Am antrenat modelul folosind un GPU (linia 2). Veți putea în continuare să rulați codul pe un procesor. Reglarea fină nu este la fel de costisitoare din punct de vedere computațional ca antrenamentul de la zero!
În cele din urmă, avem codul nostru de antrenament al modelului. Ne antrenăm pentru 10 epoci folosind MSE ca funcție de pierdere. Modelul nostru final este cel care are cel mai mic MSE din setul de validare.
name = "direction_model_1" # Change this to save a new model
# Train the model
min_loss = np.inf
for epoch in range(10):
model = model.train()
for images, target in iter(train_loader):
images = images.to(device)
target = target.to(device)
# Zero gradients of parameters
optimizer.zero_grad()
# Execute model to get outputs
output = model(images)
# Calculate loss
loss = torch.nn.functional.mse_loss(output, target)
# Run backpropogation to accumulate gradients
loss.backward()
# Update model parameters
optimizer.step()
# Calculate validation loss
model = model.eval()
images, target = next(iter(valid_loader))
images = images.to(device)
target = target.to(device)
output = model(images)
valid_loss = torch.nn.functional.mse_loss(output, target)
print("Epoch: {}, Validation Loss: {}".format(epoch, valid_loss.item()))
if valid_loss < min_loss:
print("Saving model")
torch.save(model, '../models/{}.pth'.format(name))
min_loss = valid_loss
Măsuri de evaluare
În acest moment, vrem să înțelegem cum merge modelul nostru. Ne uităm la MSE și diagrame de împrăștiere ale valorilor x reale vs prezise. Ignorăm y pentru moment, deoarece nu afectează direcția mașinii.
Set de instruire și validare
Figura 2 oferă aceste valori pentru setul de instruire și validare. Linia roșie diagonală oferă predicții perfecte. Există o variație similară în jurul acestei linii pentru x ‹ 0 și x › 0. Cu alte cuvinte, modelul este capabil să prezică virajele la stânga și la dreapta cu o precizie similară. Performanțe similare pe setul de instruire și validare indică, de asemenea, că modelul nu este supraadaptat.
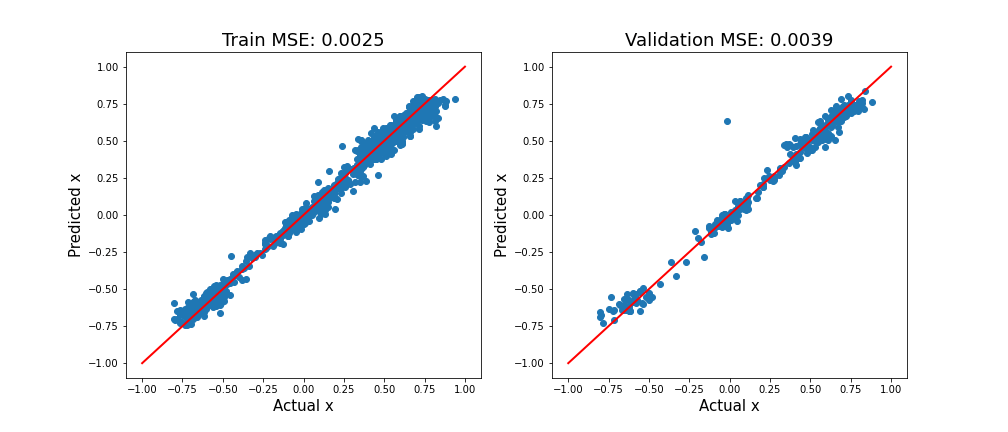
Pentru a crea graficul de mai sus, folosim funcția model_evaluation. Rețineți că încărcătorul de date ar trebui să fie creat astfel încât să încarce toate datele în prima iterație.
def model_evaluation(loaders,labels,save_path = None):
"""Evaluate direction models with mse and scatter plots
loaders: list of data loaders
labels: list of labels for plot title"""
n = len(loaders)
fig, axs = plt.subplots(1, n, figsize=(7*n, 6))
# Evalution metrics
for i, loader in enumerate(loaders):
# Load all data
images, target = next(iter(loader))
images = images.to(device)
target = target.to(device)
output=model(images)
# Get x predictions
x_pred=output.detach().cpu().numpy()[:,0]
x_target=target.cpu().numpy()[:,0]
# Calculate MSE
mse = mean_squared_error(x_target, x_pred)
# Plot predcitons
axs[i].scatter(x_target,x_pred)
axs[i].plot([-1, 1],
[-1, 1],
color='r',
linestyle='-',
linewidth=2)
axs[i].set_ylabel('Predicted x', size =15)
axs[i].set_xlabel('Actual x', size =15)
axs[i].set_title("{0} MSE: {1:.4f}".format(labels[i], mse),size = 18)
if save_path != None:
fig.savefig(save_path)
Puteți vedea la ce ne referim când folosim funcția de mai jos. Am creat un nou train_loader, setând dimensiunea lotului la lungimea setului de date de antrenament. De asemenea, este important să încărcați modelul salvat (linia 2). În caz contrar, vei ajunge să folosești modelul antrenat în ultima epocă.
# Load saved model
model = torch.load('../models/direction_model_1.pth')
model.eval()
model.to(device)
# Create new loader for all data
train_loader = DataLoader(train_data, batch_size=train_data.__len__())
# Evaluate model on training and validation set
loaders = [train_loader,valid_loader]
labels = ["Train","Validation"]
# Evaluate on training and validation set
model_evaluation(loaders,labels)
Mutarea într-o locație nouă
Rezultatele arată bine! Ne-am aștepta ca mașina să funcționeze bine și a făcut-o. Asta până când l-am mutat într-o locație nouă:

Colectăm câteva date din locații noi (camera 2 și camera 3). Evaluând aceste imagini, puteți observa că modelul nostru nu funcționează la fel de bine. Este ciudat! Mașina este pe aceeași cale, așa că de ce contează camera?
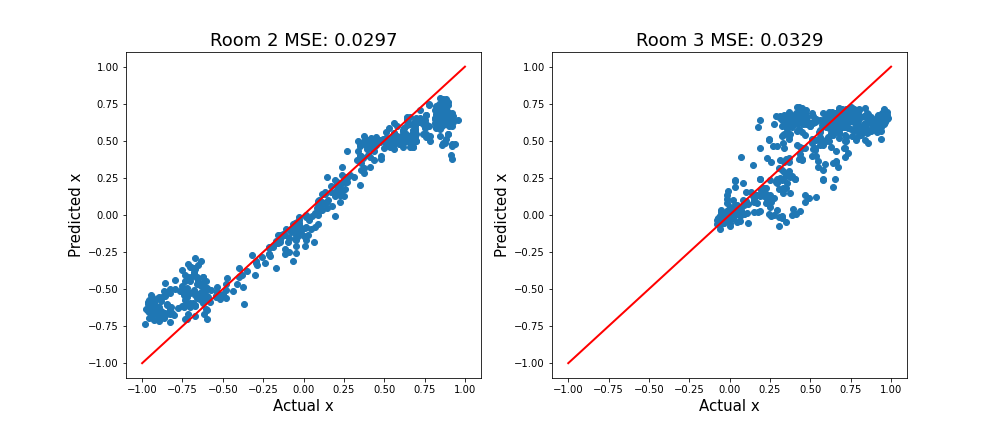
Depanarea modelului folosind SHAP
Așteptăm răspunsul la SHAP. Poate fi folosit pentru a înțelege ce pixeli sunt importanți pentru o anumită predicție. Începem prin a încărca modelul nostru salvat (linia 2). SHAP nu a fost implementat pentru GPU, așa că am setat dispozitivul la CPU (liniile 5-6).
# Load saved model
model = torch.load('../models/direction_model_1.pth')
# Use CPU
device = torch.device('cpu')
model = model.to(device)
Pentru a calcula valorile SHAP, trebuie să obținem câteva imagini de fundal. SHAP se va integra peste aceste imagini la calcularea valorilor. Folosim un batch_size de 100 de imagini. Acest lucru ar trebui să ne ofere aproximări rezonabile. Creșterea numărului de imagini va îmbunătăți aproximarea, dar va crește și timpul de calcul.
#Load 100 images for background shap_loader = DataLoader(train_data, batch_size=100, shuffle=True) background, _ = next(iter(shap_loader)) background = background.to(device)
Creăm un obiect explicativ prin trecerea modelului și a imaginilor de fundal în funcția DeepExplainer. Această funcție aproximează eficient valorile SHAP pentru rețelele neuronale. Ca alternativă, îl puteți înlocui cu funcția GradientExplainer.
#Create SHAP explainer explainer = shap.DeepExplainer(model, background)
Încărcăm 2 exemple de imagini — o viraj la dreapta și la stânga (linia 2) și le transformăm (linia 6). Acest lucru este important deoarece imaginile ar trebui să fie în același format cu cel folosit pentru antrenamentul modelului. Apoi calculăm valorile SHAP pentru predicțiile făcute folosind aceste imagini (linia 10).
# Load test images of right and left turn
paths = glob.glob('../data/room_1/*')
test_images = [Image.open(paths[0]), Image.open(paths[3])]
test_images = np.array(test_images)
test_input = [TRANSFORMS(img) for img in test_images]
test_input = torch.stack(test_input).to(device)
# Get SHAP values
shap_values = explainer.shap_values(test_input)
În cele din urmă, putem afișa valorile SHAP utilizând funcția image_plot. Dar mai întâi trebuie să le restructurăm. Valorile SHAP sunt returnate cu dimensiuni:
( #ținte, #imagini, #canale, #lățime, #înălțime)
Folosim funcția de transpunere astfel încât să avem dimensiuni:
( #ținte, #imagini, #lățime, #înălțime, #canale)
Rețineți că am trecut și imaginile originale în funcția image_plot. Imaginile test_input ar părea ciudat din cauza transformărilor.
# Reshape shap values and images for plotting shap_numpy = list(np.array(shap_values).transpose(0,1,3,4,2)) test_numpy = np.array([np.array(img) for img in test_images]) shap.image_plot(shap_numpy, test_numpy,show=False)
Puteți vedea rezultatul în Figura 4. Prima coloană oferă imaginile originale. A doua și a treia coloană sunt valorile SHAP pentru predicția x și respectiv y. Pixelii albaștri au scăzut predicția. În comparație, pixelii roșii au crescut predicția. Cu alte cuvinte, pentru predicția x, pixelii roșii au dus la o viraj mai ascuțit la dreapta.

Acum ajungem undeva. Rezultatul important este că modelul folosește pixeli de fundal. Puteți vedea acest lucru în Figura 5, unde mărim predicția x pentru virajul la dreapta. Cu alte cuvinte, fundalul este important pentru predicție. Asta explică performanța slabă! Când ne-am mutat într-o cameră nouă, fundalul s-a schimbat și previziunile noastre au devenit nesigure.

Modelul este supraadaptat la datele din camera 1. Aceleași obiecte și fundal sunt prezente în fiecare imagine. Drept urmare, modelul le asociază cu virajele la stânga și la dreapta. Nu am putut identifica acest lucru în evaluarea noastră, deoarece avem același fundal atât în imaginile de instruire, cât și în cele de validare.

Îmbunătățirea modelului
Ne dorim ca modelul nostru să funcționeze bine în toate condițiile. Pentru a realiza acest lucru, ne-am aștepta să folosească doar pixeli din pistă. Deci, să discutăm câteva modalități de a face modelul mai robust.
Colectarea de date noi
Cea mai bună soluție este pur și simplu să colectați mai multe date. Avem deja câteva din camera 2 și 3. Urmând același proces, antrenăm un nou model folosind date din toate cele 3 camere. Privind la Figura 7, acum are o performanță mai bună la imaginile din noile camere.

Speranța este că prin antrenamentul pe date din mai multe camere să rupem asocierile dintre viraj și fundal. Diferite obiecte sunt acum prezente la viraje la stânga și la dreapta, dar traseul rămâne același. Modelul ar trebui să învețe că pista este ceea ce este important pentru predicție.
Putem confirma acest lucru analizând valorile SHAP pentru noul model. Acestea sunt pentru aceleași viraj pe care le-am văzut în Figura 4. Acum este mai puțină greutate pe pixelii de fundal. Bine, nu este perfect, dar ajungem undeva.

Am putea continua să colectăm date. Cu cât colectăm mai multe locații de date, cu atât modelul nostru va fi mai robust. Cu toate acestea, colectarea datelor poate fi consumatoare de timp (și plictisitoare!). În schimb, ne putem uita la creșterea datelor.
Augmentări de date
Mărirea datelor este atunci când modificăm sistematic sau aleatoriu imaginile folosind cod. Acest lucru ne permite să introducem artificial zgomot și să creștem dimensiunea setului nostru de date.
De exemplu, am putea dubla dimensiunea setului nostru de date întorcând imaginilepe axa verticală. Putem face asta pentru că pista noastră este simetrică. După cum se vede în Figura 9, ștergerea ar putea fi, de asemenea, o metodă utilă. Aceasta implică includerea imaginilor în care obiectele sau întregul fundal au fost eliminate.

Atunci când construiți un model robust, ar trebui să luați în considerare și factori precum condițiile de iluminare și calitatea imaginii. Le putem simula folosind jitterul de culoare sau adăugând zgomot. Dacă doriți să aflați despre toate aceste metode, consultați articolul de mai jos.
„Mărirea imaginilor pentru învățare profundă
Folosirea Python pentru a mări datele prin răsturnarea, ajustarea luminozității, fluctuația de culoare și zgomotul aleatoriutowardsdatascience.com”
În articolul de mai sus, discutăm și de ce este dificil de spus dacă aceste creșteri au făcut modelul mai robust. Am putea implementa modelul în multe medii, dar acest lucru necesită mult timp. Din fericire, SHAP poate fi folosit ca alternativă. Ca și în cazul colectării de date, ne poate oferi o perspectivă asupra modului în care creșterile au schimbat modul în care modelul face predicții.
Sper că v-a plăcut acest articol! Puteți să mă susțineți devenind unul dintre membrii recomandati ai mei :)
„Alăturați-vă Medium cu linkul meu de recomandare — Conor O'Sullivan
În calitate de membru Medium, o parte din taxa dvs. de abonament merge către scriitorii pe care îi citiți și aveți acces deplin la fiecare poveste…conorosullyds.medium.com»
| Twitter | YouTube | Buletin informativ — înscrieți-vă pentru acces GRATUIT la un curs Python SHAP
Setul de date
Imagini JatRacer (CC0: Domeniu Public) https://www.kaggle.com/datasets/conorsully1/jatracer-images
Referințe
SHAP, Exemplu MNIST PyTorch Deep Explainerhttps://shap.readthedocs.io/en/latest/example_notebooks/image_examples/image_classification/PyTorch%20Deep%20Explainer%20MNIST%20example.html