
Introducere
Dacă sunteți unul dintre mulți utilizatori R care fac trecerea la python, s-ar putea să vă aflați în funcție de comoditatea unora dintre cele mai îndrăgite biblioteci ale lui R. La suprafață, saltul de la comoditatea și simplitatea lui R poate părea puțin descurajantă, deoarece peisajul python, deși amplu, poate produce adesea ceea ce par prea multe traduceri pentru o anumită piesă de funcționalitate. Nu este întotdeauna ușor să găsești traduceri directe.
Scopul acestui lucru este de a împărtăși o perspectivă informată despre metodele pe care să vă bazați pe măsură ce vă mutați fluxul de lucru la python.
Pentru acest articol, vom explora alternative la metodele convenabile ale dplyr pentru a efectua tot felul de îmbinări.
Rămâneți pe fază pentru alte articole care abordează unele dintre aceste întrebări cheie.
Ce vei învăța
Pentru acest articol, vom descompune traducerile primare pentru funcțiile de unire ale lui R din biblioteca dplyr.
Citind acest articol, vă puteți aștepta să învățați traduceri principale python pentru următoarele funcții:
- left_join
- right_join
- inner_join
- outer_join
- anti_join
- semi_join
Privire de ansamblu
Funcțiile de îmbinare sunt folosite pentru a combina două sau mai multe cadre de date pe baza unei coloane comune.
Mai jos este o trecere în revistă rapidă a diferitelor definiții
- left_join: returnează toate rândurile din tabelul din stânga și orice rânduri care se potrivesc din tabelul din dreapta
- right_join: returnează toate rândurile din tabelul din dreapta și orice rânduri care se potrivesc din tabelul din stânga
- inner_join: returnează numai înregistrările care apar în ambele tabele
- outer_join: Această funcție returnează toate rândurile din ambele tabele și completează toate valorile lipsă cu NA
- anti_join: Această funcție returnează toate rândurile din tabelul din stânga care nu au o potrivire în tabelul din dreapta.
- semi_join: Această funcție returnează toate rândurile din tabelul din stânga care au o potrivire în tabelul din dreapta.
Timp de comparație
Înainte de a interveni, vom folosi două exemple de cadre de date. Voi include codul pentru a genera aceste două exemple de cadre de date, astfel încât să puteți urmări:
# libraries
import pandas as pd
# sample df1
df1 = pd.DataFrame({
'join_column': ['A', 'B', 'C', 'D'],
'col1': [10, 20, 30, 40],
'col2': [100, 200, 300, 400]
})
# sample df2
df2 = pd.DataFrame({
'join_column': ['B', 'D', 'E', 'F'],
'col3': ['X', 'Y', 'Z', 'W'],
'col4': ['P', 'Q', 'R', 'S']
})
Cu asta în afara drumului, să ne scufundăm
Left Join
R
În r vă puteți bucura de simplitatea și fluxul dplyr, specificați cadrul de date de interes, df1 în acest caz, și vă alăturați lui df2 pe câmpul comun
df3 <- df1 %>%
left_join(df2, by = "join_column")
Piton
Din fericire, în python lucrurile nu sunt deloc diferite. Principala diferență este sintactică, merge versus left_join, on mai degrabă decât de și așa mai departe.
O altă diferență este că putem folosi .merge ca metodă în cadrul de date din stânga. Unul dintre aspectele interesante și mai convenabile ale îmbinării este parametrul how. Acest lucru ne permite să stabilim tipul de alăturare care ne interesează. Nu că ar fi atât de greu să ne amintim left_join, right_join, inner_join, dar hei... uneori trebuie să te bucuri de lucrurile simple.
df3 = df1.merge(df2, on = "join_column", how = "left")
O altă notă este că puteți apela și merge ca funcție, caz în care comanda ar arăta astfel:
df3 = pd.merge(df1, df2, on = "join_column", how = "left")
Nu foarte diferit, dar util să fii conștient de faptul că atât funcția, cât și metoda sunt de la panda și ambele sunt disponibile.
Rezultatul:

Alăturați-vă dreapta
Aproape de la sine explicabil, singurul lucru care se schimbă aici este că efectuăm o îmbinare corectă, de asemenea, același lucru cu schimbarea cadru de date pe care îl numim primul.
Vom parcurge exemplele aici.
R
Singurul lucru care se schimbă aici este funcția
df3 <- df1 %>%
right_join(df2, by = "join_column")
Piton
df3 = df1.merge(df2, on = "join_column", how = "right")
Rezultatul:
Inner Join
Similar cu right join, următoarele câteva funcții sunt super simple, așa că vom trece rapid.
R
df3 <- df1 %>%
inner_join(df2, by = "join_column")
Piton
df3 = df1.merge(df2, on = "join_column", how = "inner")
Rezultatul:
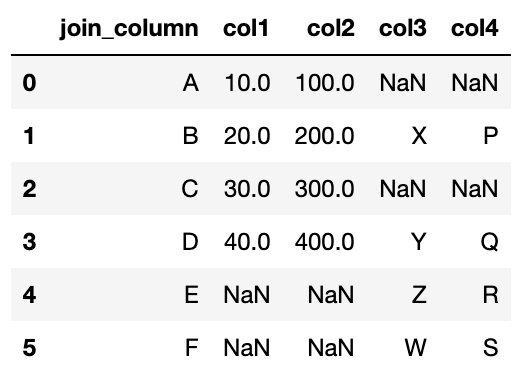
Unire exterioară
R
df3 <- df1 %>%
outer_join(df2, by = "join_column")
Piton
df3 = df1.merge(df2, on = "join_column", how = "outer")
Anti Join
Aici este locul în care Python se implică puțin mai mult, dar în apărarea sa, anti join nu sunt cele mai comune.
R
df3 <- df1 %>%
anti_join(df2, by = "join_column")
Piton
df3 = df1.merge(df2["join_column"], on = "join_column", how = "left", indicator=True)
.query('_merge == "left_only"')
.drop('_merge', 1)
Există câteva piese diferite de explicat aici.
Când populăm parametrul indicator la True, se adaugă o nouă coloană numită „_merge”, care, în cazul unei îmbinări la stânga, spune „left_only” sau „both”. După cum ați putea ghici, „left_only” înseamnă că nu a existat o potrivire în cadrul de date corect și, în cazul „ambele”, a existat o potrivire.
Indicăm True, astfel încât să putem folosi apoi .query pentru a specifica că vrem doar înregistrări care nu au fost găsite în cadrul de date corect.
Și, în sfârșit, ca un pic de curățare, aruncăm coloana „_merge”.
Și ultima piesă pe care o voi menționa, trebuie, de asemenea, să subsetăm cadrul de date corect doar în coloana de unire. În caz contrar, vom fi adăugat toate coloanele nule din cadrul de date din dreapta. Ceea ce ar fi inutil și împotriva utilizării tradiționale a anti_join.
După cum am spus, mult mai implicat, dar încă destul de simplu din punct de vedere conceptual.
Rezultatele:
Semi alăturați
Ca o reamintire, semi-uniunile sunt opusul anti_join. Vom returna doar înregistrări din cadrul de date din stânga în care există potriviri cu cadrul de date din dreapta.
De fapt, nimic nu se schimbă în R.
R
df3 <- df1 %>%
anti_join(df2, by = "join_column")
Piton
Similar cu ceea ce am văzut mai sus cu anti join; totuși, în acest caz, interogăm unde _merge este egal cu „ambele”, ceea ce presupune că a existat o potrivire.
pd.merge(df1, df2['join_column'], on = "column_name", how = "left", indicator=True)\
.query('_merge == "both"')\
.drop('_merge', 1)

Concluzie:
Am parcurs o mulțime de teren rapid. Când vine vorba de alăturarea pașilor panda în mod similar cu dplyr în R. Am explorat traduceri simple și eficiente python pentru funcționalitatea de unire cheie în R, în special, dplyr.
Mai exact, am explorat următoarele tipuri de îmbinări:
- left_join
- right_join
- inner_join
- outer_join
- anti_join
- semi_join
Sperăm că acest articol se dovedește util. Spuneți-ne ce metode alternative utilizați în Python, mai degrabă decât funcționalitatea merge a panda.