În ultimii ani, domeniul învățării profunde a fost martorul unor progrese fără precedent, determinate de dorința de a emula funcționarea complicată a creierului uman. În esență, învățarea profundă urmărește să reproducă capacitatea creierului de a procesa informații din diverse surse și de a obține perspective semnificative. Această inspirație profundă a condus la dezvoltarea unor arhitecturi noi care nu numai că permit realizarea unor sarcini complexe, ci și descoperă straturi mai profunde de reprezentare a datelor. Drept urmare, arhitecturile sunt esențiale pentru noi, nu numai pentru că multe provocări se bazează pe sarcinile pe care le putem îndeplini cu ele. De fapt, designul rețelelor în sine ne indică reprezentarea pe care o căutau cercetătorii, pentru a învăța mai bine din date .
LeNet
Muncă de pionierat
Înainte de a începe, să remarcăm că nu am fi avut succes dacă am folosi pur și simplu un perceptron brut multistrat conectat la fiecare pixel al unei imagini. Pe lângă faptul că devine rapid insolubilă, această operațiune directă nu este foarte eficientă, deoarece pixelii sunt corelați spațial.
Prin urmare, mai întâi trebuie să extragem
- semnificativ și
- caracteristici de dimensiuni reduse la care putem lucra.
Și aici intră în joc rețelele neuronale convoluționale!
Pentru a rezolva această problemă, ideea lui Yann Le Cun continuă în mai mulți pași.
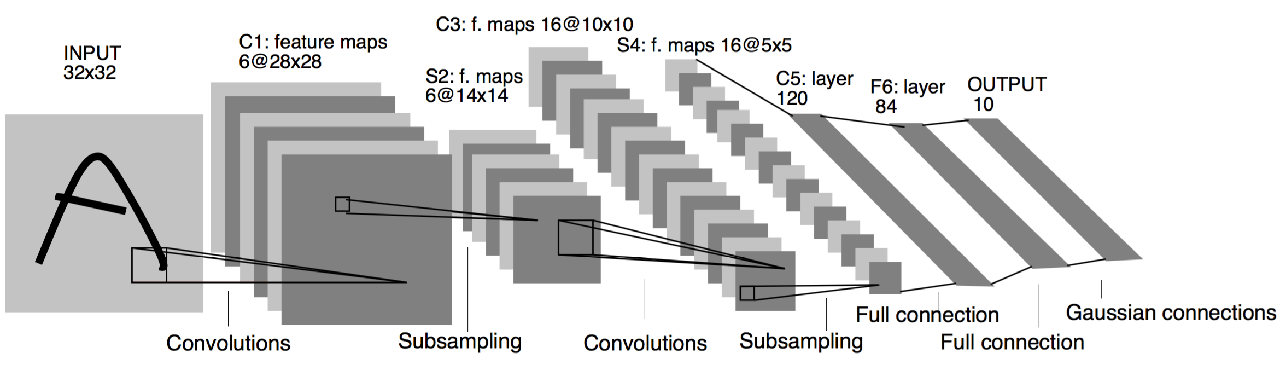
După cum sa observat, dimensiunile caracteristicilor sunt reduse progresiv în cadrul arhitecturii de rețea. În cele din urmă, aceste caracteristici rafinate de nivel înalt sunt aplatizate și canalizate în straturi complet conectate. Aceste straturi, la rândul lor, generează probabilități pentru diferite clase prin intermediul unui strat softmax.
Pe parcursul fazei de instruire, rețeaua dobândește capacitatea de a discerne trăsăturile distinctive care clasifică un anumit eșantion într-o anumită categorie. Acest proces de învățare este facilitat prin back-propagation, în care rețeaua își ajustează parametrii interni în funcție de disparitățile dintre rezultatele prezise și cele reale.
Pentru a ilustra acest concept, luați în considerare o imagine care înfățișează un cal. Inițial, filtrele rețelei s-ar putea concentra pe conturul general al animalului. Pe măsură ce rețeaua se adâncește, progresează către un nivel crescut de abstractizare, permițându-i să încapsuleze detalii mai fine, cum ar fi ochii și urechile calului.
În esență, rețelele neuronale convoluționale (ConvNets) servesc ca un mecanism pentru construirea de caracteristici care, în absența unei astfel de arhitecturi, ar necesita crearea manuală. Acest lucru subliniază potența ConvNets în automatizarea procesului de extragere a caracteristicilor, revoluționând astfel peisajul învățării profunde.
AlexNet
Convolution a ajuns la faimă
În mod firesc, s-ar putea întreba de ce rețelele neuronale convoluționale (ConvNets) nu au atins o popularitate pe scară largă înainte de 1998. Răspunsul concis la această întrebare este că capacitățile lor complete nu le-au valorificat întregul potențial înapoi.
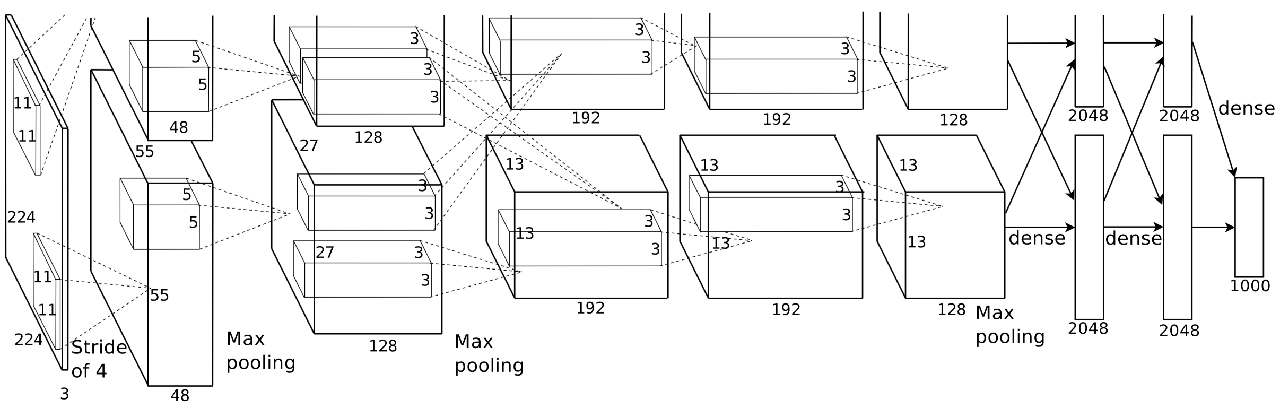
Aici, AlexNet adoptă aceeași abordare de sus în jos, în care filtrele succesive sunt concepute pentru a capta caracteristici din ce în ce mai subtile. Dar aici, munca sa a explorat câteva detalii cruciale.
- În primul rând, Krizhevsky a introdus neliniaritate mai bună în rețea cu activarea ReLU, a cărei derivată este 0 dacă caracteristica este sub 0 și 1 pentru valori pozitive. Acest lucru sa dovedit a fi eficient pentru propagarea gradientului.
- În al doilea rând, lucrarea sa a introdus conceptul de abandon ca regularizare. Din punct de vedere al reprezentării, forțezi rețeaua să uite lucrurile la întâmplare, astfel încât să poată vedea următoarele date de intrare dintr-o perspectivă mai bună.
Doar pentru a da un exemplu, după ce veți termina de citit această postare, cel mai probabil veți avea părți uitate din ea. Și totuși acest lucru este în regulă, pentru că vei fi ținut cont doar de ceea ce era esențial.
Ei bine, sperăm. Același lucru se întâmplă și în cazul rețelelor neuronale și determină modelul să fie mai robust.
3. De asemenea, a introdus augmentarea datelor. Când sunt alimentate în rețea, imaginile sunt afișate cu translație aleatorie, rotație, decupare. În acest fel, forțează rețeaua să fie mai conștientă de atributele imaginilor, mai degrabă decât de imaginile în sine.
În cele din urmă, un alt truc folosit de AlexNet este să fie mai profund. Puteți vedea aici că au stivuit mai multe straturi convoluționale înainte de operațiunile de grupare. Prin urmare, reprezentarea surprinde trăsături mai fine care se dezvăluie a fi utile pentru clasificare.
Această rețea a depășit cu mult ceea ce era de ultimă generație în 2012, cu o eroare de top 5 de 15,4% pe setul de date ImageNet.
VGGNet
Mai adânc este mai bine
Următoarea etapă importantă a clasificării imaginilor a explorat în continuare ultimul punct pe care l-am menționat: a merge mai adânc.
Și funcționează. Acest lucru sugerează că astfel de rețele pot realiza o reprezentare ierarhică mai bună a datelor vizuale cu mai multe straturi.
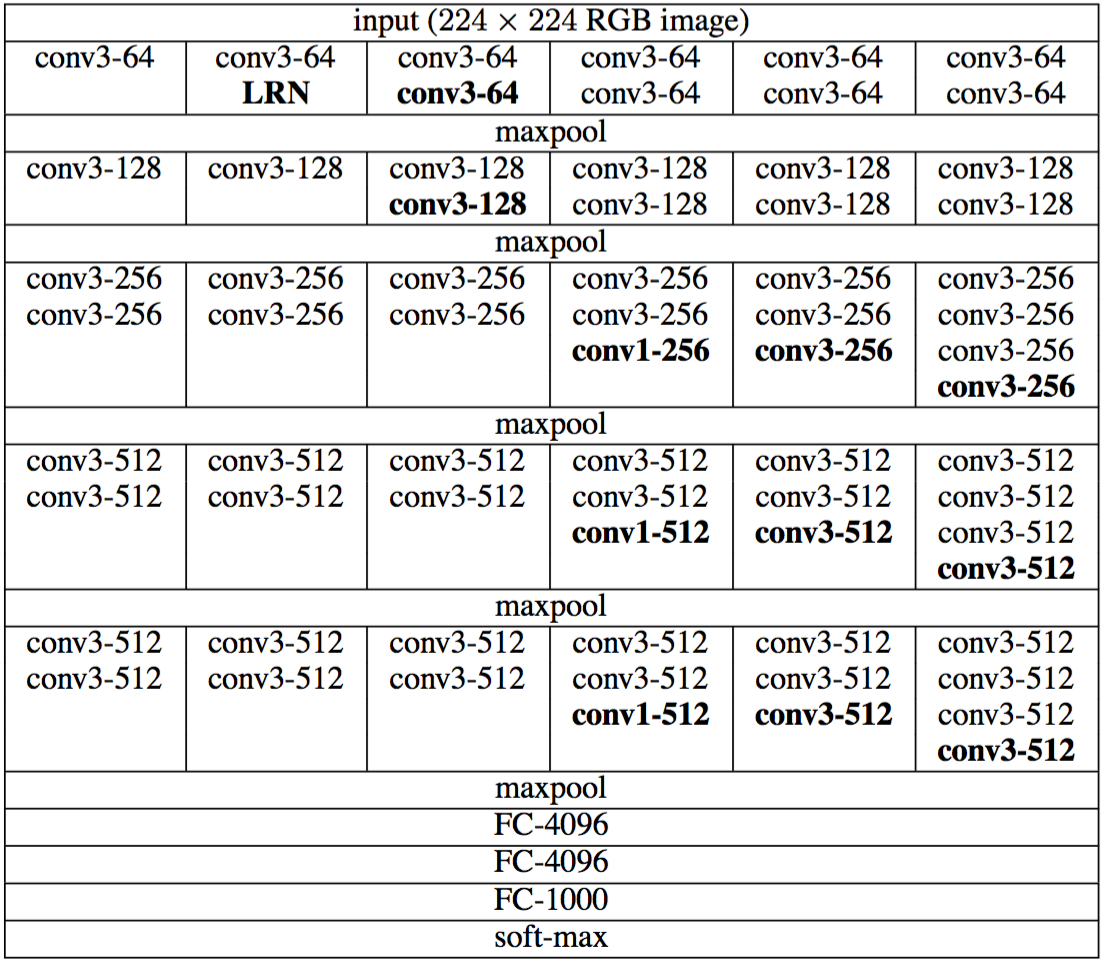
După cum puteți vedea, altceva este foarte special pe această rețea. Conține aproape exclusiv 3 cu 3 circumvoluții. Asta e curios, nu?
De fapt, autorii au fost motivați de trei motive principale pentru a face acest lucru:
- În primul rând, utilizarea filtrelor mici induce mai multă neliniaritate, ceea ce înseamnă mai multe grade de libertate pentru rețea.
- În al doilea rând, faptul de a stivui aceste straturi împreună permite rețelei să vadă mai multe lucruri decât arată. De exemplu, cu două dintre acestea, rețeaua vede un câmp receptiv 5x5. Și când stivuiți 3 dintre aceste filtre, aveți de fapt un câmp receptiv 7x7! Prin urmare, aceleași capacități de extragere a caracteristicilor ca în exemplele anterioare pot fi realizate și pe această arhitectură.
- În al treilea rând, utilizarea numai a filtrelor mici limitează și numărul de parametri, ceea ce este bine atunci când doriți să mergeți atât de adânc.
Cantitativ vorbind, această arhitectură a obținut o eroare top-5 de 7,3% pe ImageNet.
GoogleNet
Timpul pentru început
Apoi, GoogLeNet a intrat în joc. Își bazează succesul pe modulele de inițiere.
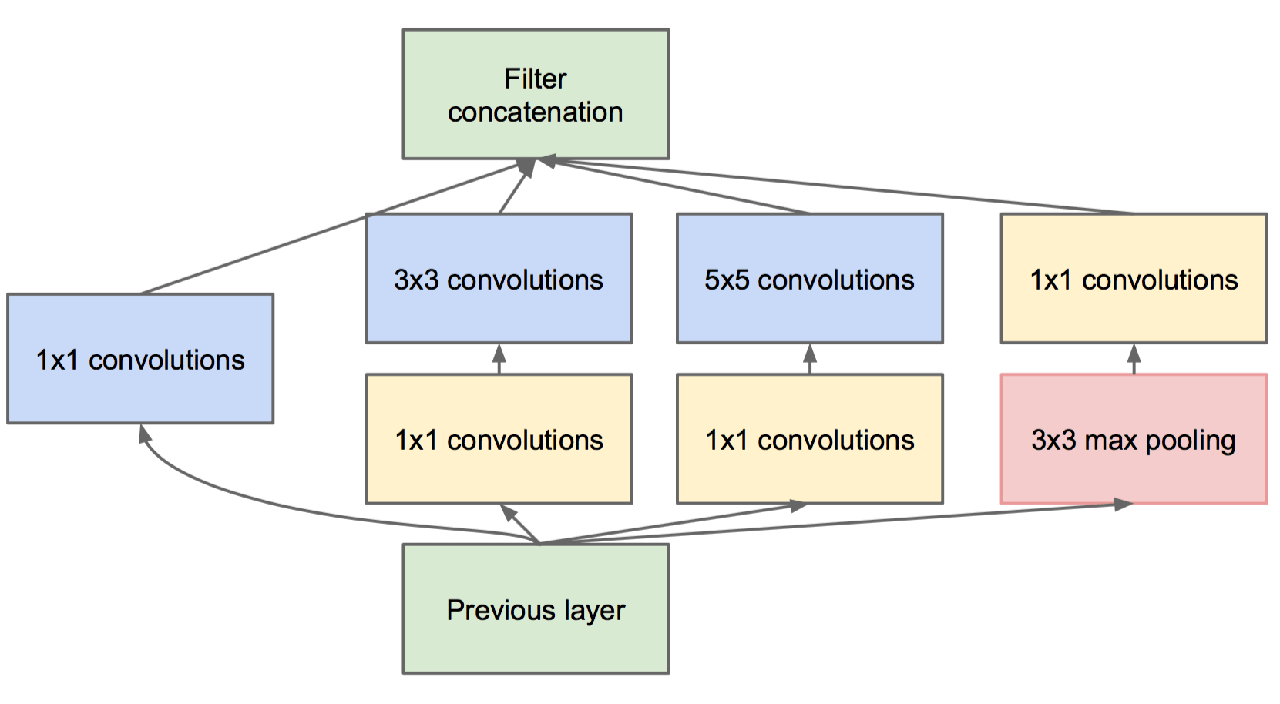
După cum puteți vedea, convoluțiile cu dimensiuni diferite de filtru sunt procesate pe aceeași intrare și apoi concatenate împreună.
Din punct de vedere al reprezentării, acest lucru permite modelului să profite de extracția caracteristicilor pe mai multe niveluri la fiecare pas. De exemplu, caracteristicile generale pot fi extrase de filtrele 5x5 în același timp în care mai multe caracteristici locale sunt capturate de convoluțiile 3x3.
Dar atunci, ai putea să-mi spui. Ei bine, asta e grozav. Dar nu este atât de scump de calculat?
Si as spune: foarte buna observatie! De fapt, echipa Google a avut o soluție genială pentru aceasta: convoluții 1x1.
- Pe de o parte, reduce dimensionalitatea caracteristicilor tale.
- Pe de altă parte, combină hărțile caracteristicilor într-un mod care poate fi benefic din perspectiva reprezentării.
Atunci te-ai putea întreba, de ce se numește început? Ei bine, puteți vedea toate aceste module ca fiind rețele stivuite una peste alta în interiorul unei rețele mai mari.
Și pentru înregistrare, cel mai bun ansamblu GoogLeNet a obținut o eroare de 6,7% pe ImageNet.
ResNet
Conectați straturile
Așa că toate aceste rețele despre care am vorbit mai devreme au urmat aceeași tendință: mergi mai adânc. Dar la un moment dat ne dăm seama că stivuirea mai multor straturi nu duce la performanță mai bună. De fapt, se întâmplă exact opusul. Dar de ce este asta?
Într-un cuvânt: gradientul, doamnelor și domnilor.
Dar nu vă faceți griji, cercetătorii au găsit un truc pentru a contracara acest efect. Aici, conceptul cheie dezvoltat de ResNet este învățarea reziduală.
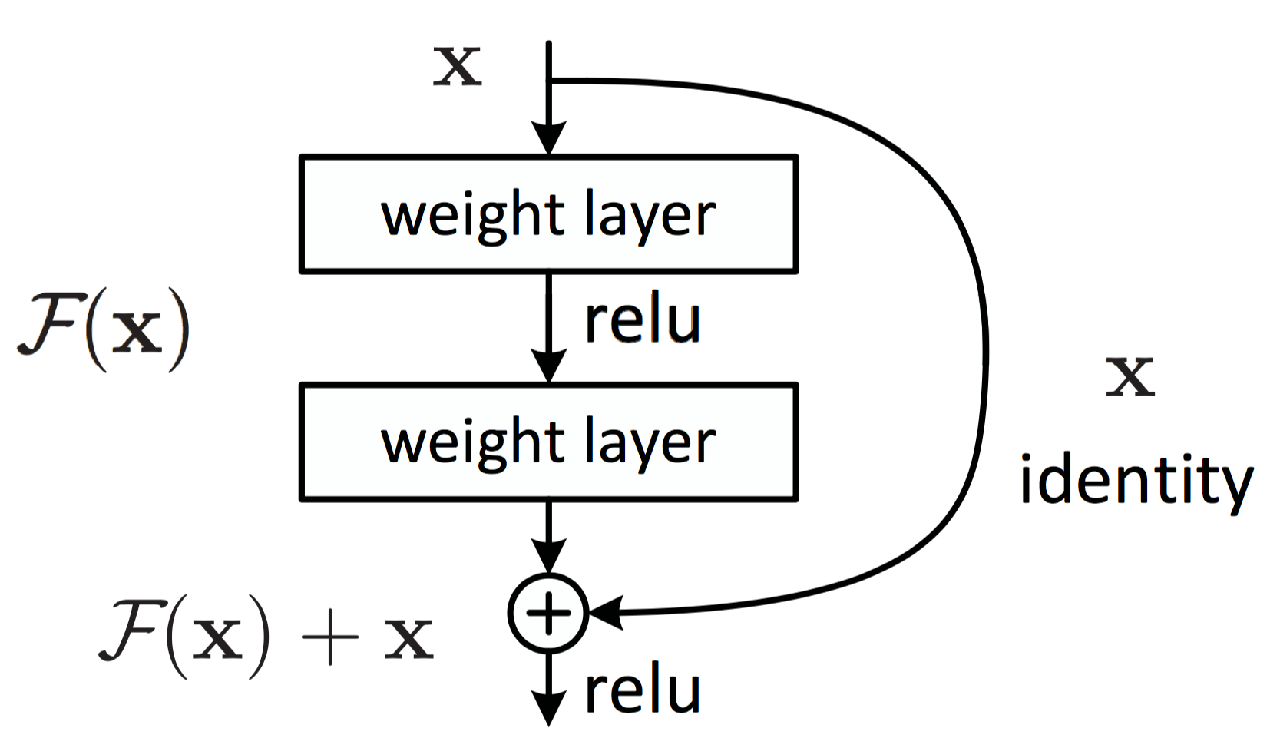
După cum puteți vedea, la fiecare două straturi, există o mapare a identității printr-o adăugare în funcție de elemente. Acest lucru sa dovedit a fi foarte util pentru propagarea gradientului, deoarece eroarea poate fi propagată invers prin căi multiple.
De asemenea, din punct de vedere al reprezentării, acest lucru ajută la combinarea diferitelor niveluri de caracteristici la fiecare pas al rețelei, așa cum am văzut cu modulele inițiale.
Până în prezent, este una dintre cele mai performante rețele de pe ImageNet, cu o rată de eroare de 3,6% în top-5.
DenseNet
Conectați-vă mai mult!
O extindere a acestui raționament a fost propusă ulterior. DenseNet propune blocuri întregi de straturi conectate între ele.
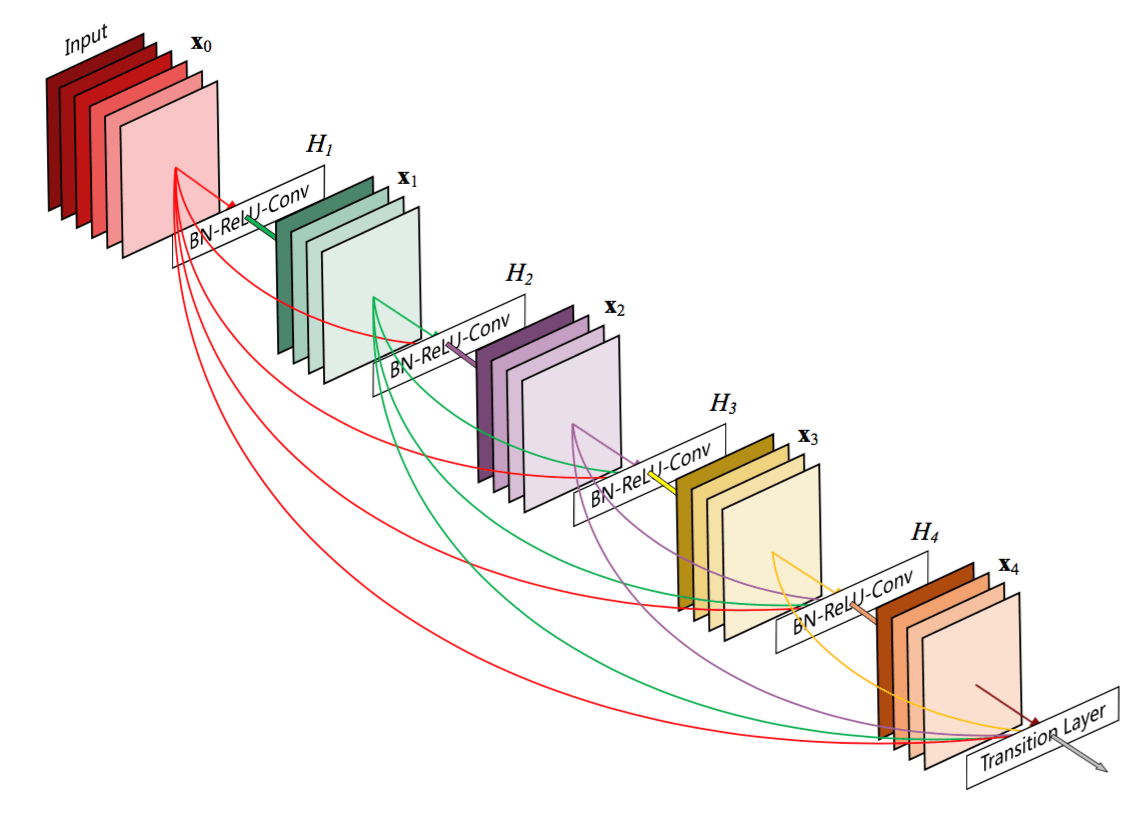
Acest lucru contribuie la diversificarea mult mai mult a funcțiilor din acele blocuri.
Concluzie
O tendință globală predominantă este progresia continuă către arhitecturi de rețea din ce în ce mai profunde. Această traiectorie a fost completată de încorporarea de îmbunătățiri computaționale, cum ar fi Rectified Linear Units (ReLU), abandon și normalizarea lotului. Aceste strategii au jucat în mod colectiv un rol esențial în creșterea performanței generale a acestor rețele.
Simultan, au apărut module noi care se mândresc cu capacitatea de a extrage caracteristici complexe în fiecare etapă a ierarhiei rețelei. Această inovație nu numai că a îmbogățit capabilitățile de reprezentare ale modelelor, dar a deschis și calea pentru perspective mai nuanțate.
O dezvoltare suplimentară demnă de remarcat este accentul tot mai mare pus pe interconexiunile dintre diferitele straturi din cadrul rețelei. Aceste conexiuni joacă un rol dublu: în primul rând, facilitează generarea de caracteristici diverse; în al doilea rând, ele se dovedesc esențiale în propagarea fără întreruperi a gradienților prin arhitectura de rețea, un factor crucial pentru un antrenament eficient.
În esență, traiectoria globală în învățarea profundă a fost caracterizată de motoarele gemene de profunzime arhitecturală și rafinament computațional, cuplate cu mecanisme inventive de extracție a caracteristicilor și interconexiuni complexe ale straturilor. Această abordare cu mai multe fațete a condus la progrese semnificative în domeniu, propulsându-l la noi culmi de performanță și înțelegere.
În limba engleză simplă
Vă mulțumim că faci parte din comunitatea noastră! Înainte de a pleca:
- Asigură-te că îl apuci și urmărește scriitorul! 👏
- Puteți găsi și mai mult conținut la PlainEnglish.io 🚀
- Înscrieți-vă pentru „buletinul nostru informativ săptămânal gratuit”. 🗞️
- Urmărește-ne pe Twitter, LinkedIn, «YouTube >> și „Discord”.