Часть III: Пагинация

Введение:
Добро пожаловать в третью и последнюю часть руководства по парсингу yahoo finance / scrapy. Если вы не читали предыдущие части, я рекомендую вам сделать это, щелкнув здесь (часть-I, часть-II), поскольку следующий учебник основан на них.
На данный момент мы загрузили самую активную страницу акций на Yahoo Finance (URL- https://finance.yahoo.com/most-active/) и удалили все акции, которые появляются на странице 1 в файле .csv. В этом руководстве мы расскажем, как перемещаться по страницам (нажимая кнопку Далее в нижней части страницы наиболее активных акций) и собирать данные по всем акциям на всех страницах. Это также можно назвать очисткой страницы.
Что такое разбиение на страницы? Это последовательность страниц, которые связаны и имеют похожее содержание.
Обзор: в части 3 мы хотим, чтобы наш паук выполнял следующие действия:
- Загрузите страницу самых активных акций Yahoo
- Получите URL-адреса для каждой страницы пагинации акций.
- Загрузите каждую страницу пагинации.
- Получите список URL-адресов с описанием акций на каждой странице.
- Загрузите URL-адрес каждой детали акции и запустите код, чтобы очистить детали акции (написанные в части I и части II) для каждой акции.
Из вышеперечисленных пунктов мы уже выполнили шаги 1, 4 и 5. Мы добавим шаги 2 и 3 и свяжем их между точками 1 и 4 и повторим код, уже написанный для каждой акции.

Для нашего урока следующий гиф даст нам контекст нумерации страниц. Также обратите внимание на URL-адрес, когда мы нажимаем следующие кнопки:

Мы наблюдаем, что на каждой странице отображается 25 акций, и общее количество наиболее активных акций будет меняться каждый день. Кроме того, URL-адрес изменяется каждый раз, когда мы нажимаем «Далее». Мы захотим обработать это изменение в URL без жесткого кодирования его при парсинге, чтобы наш паук мог обрабатывать динамическое количество акций. Чтобы понять изменение, давайте исследуем URL-адреса для каждой страницы:
https://finance.yahoo.com/most-active/?count=25&offset=0 #Page 1 https://finance.yahoo.com/most-active/?count=25&offset=25 #Page 2 https://finance.yahoo.com/most-active/?count=25&offset=50 #Page 3 https://finance.yahoo.com/most-active/?count=25&offset=75 #Page 4
Мы видим, что значение смещения изменяется на 25 для каждой новой страницы. Это будет продолжаться до тех пор, пока не будут показаны все акции. На последней странице будет отображаться остаток акций. Чтобы загрузить все URL-адреса, нам нужно знать, сколько страниц присутствует, и создать список со значениями смещения, кратными 25, например [0,25,50….]. Чтобы узнать, сколько нам нужно кратных 25, нам нужно будет извлечь общее количество акций на странице.
Итак, наш алгоритм выглядит следующим образом:
- Извлеките общее количество акций с помощью селекторов Xpath и CSS.
- Разделите общее количество на 25 и прибавьте 1, чтобы получить общее количество страниц.
- Создайте список из n кратных 25, где n - общее количество страниц.
- Переберите число, кратное 25, и замените значение смещения в URL-адресе, чтобы загрузить страницу, как показано ниже, и выполните обратный вызов функции get_stocks (), определенной в части II учебника.
url=f'https://finance.yahoo.com/most-active?count=25&offset={offset}'
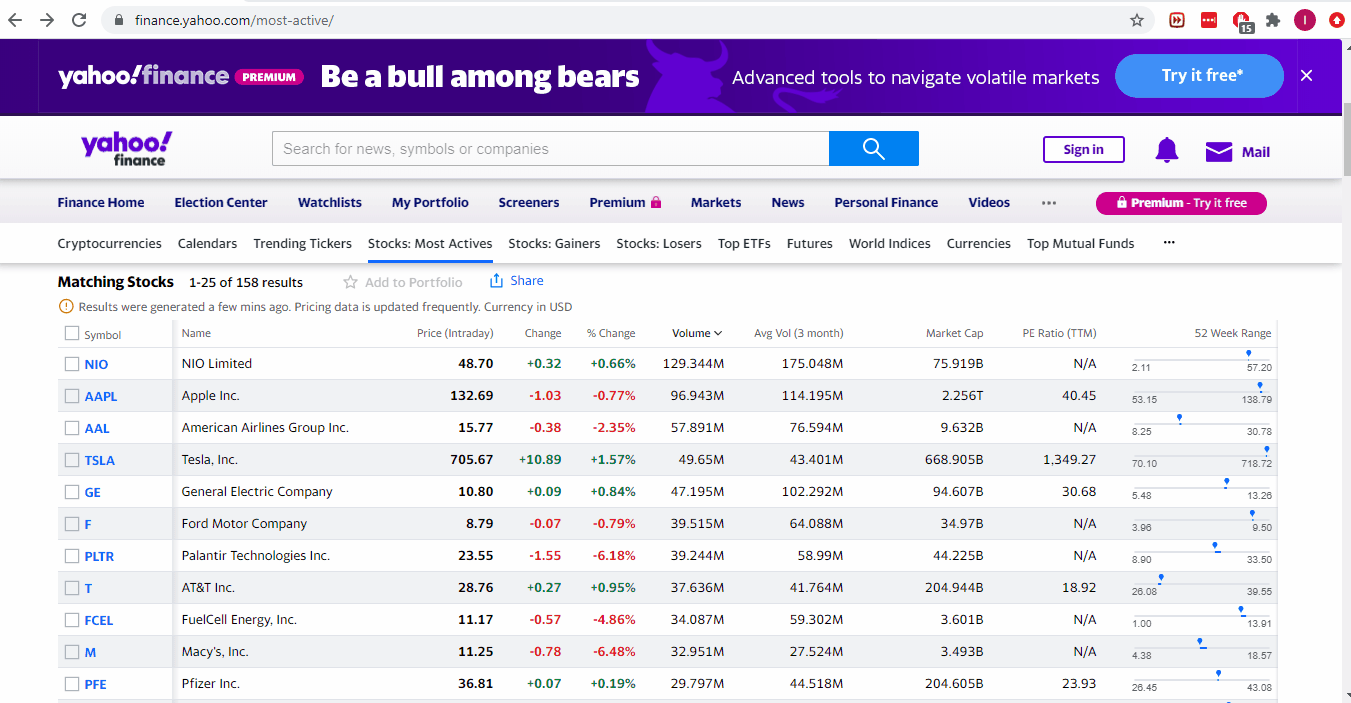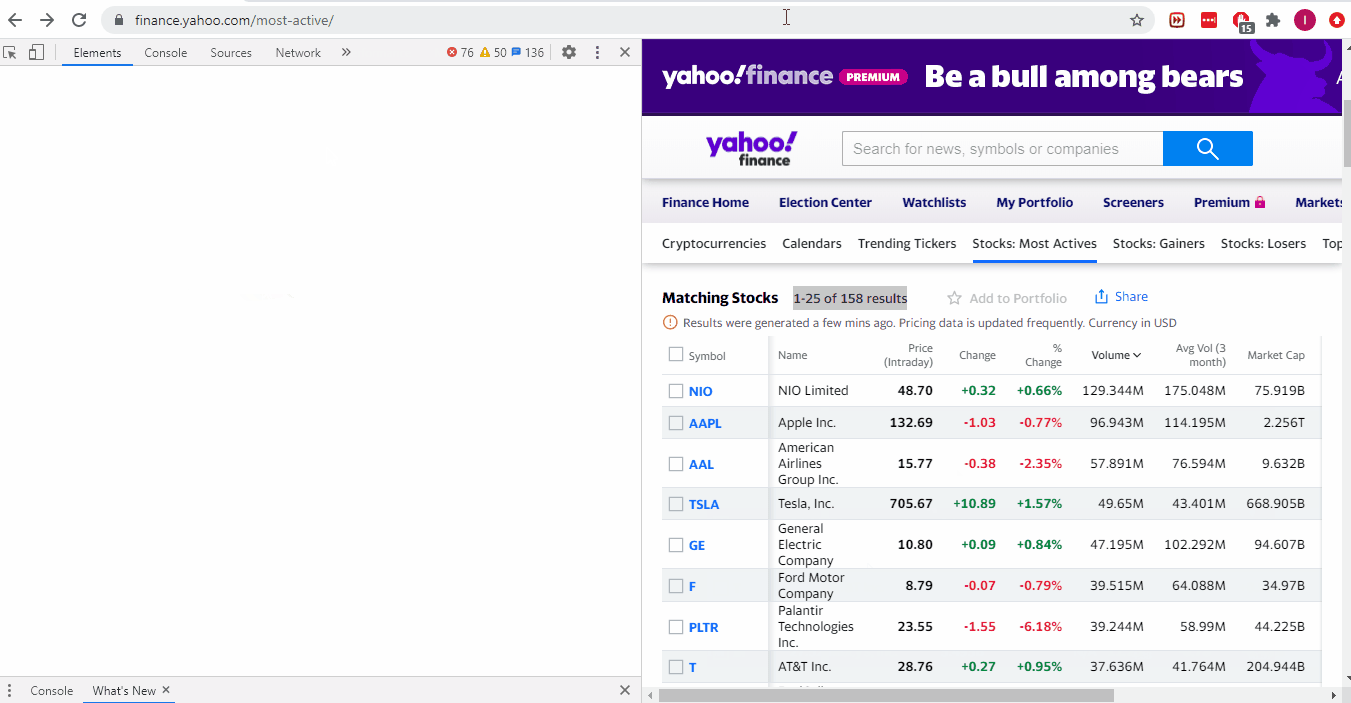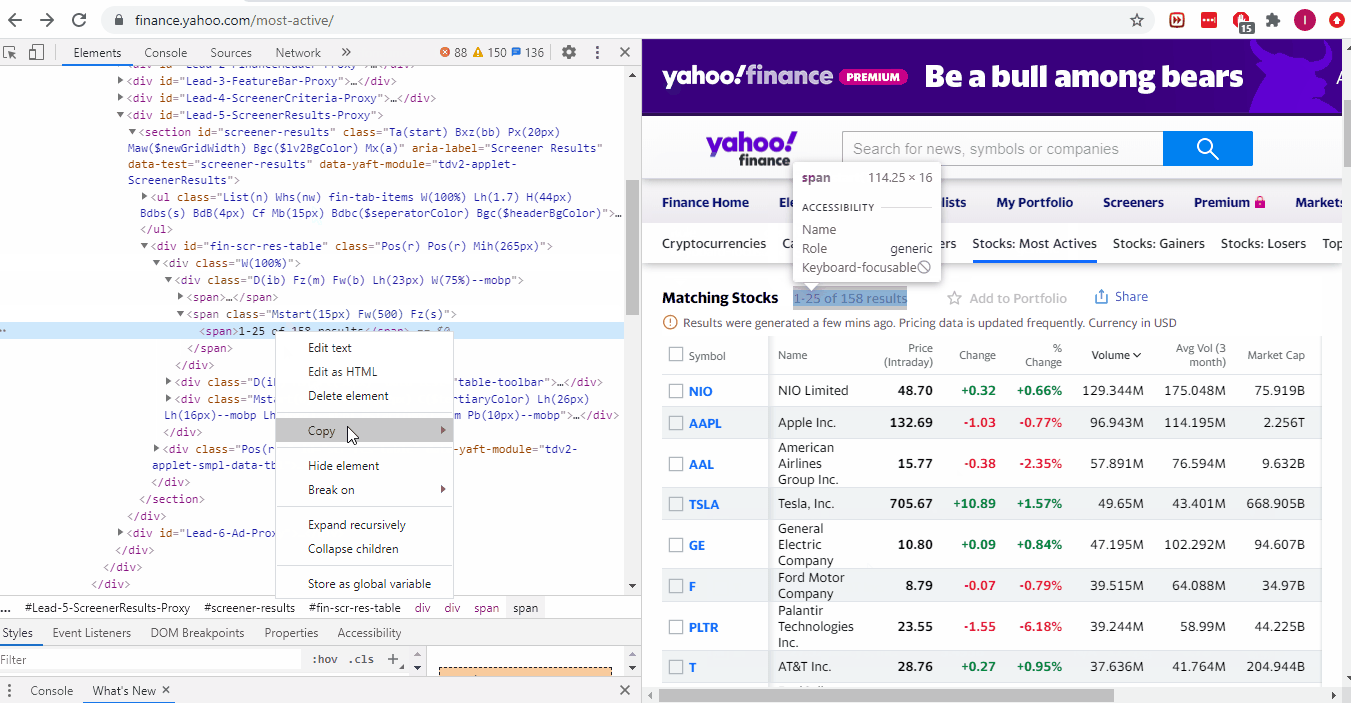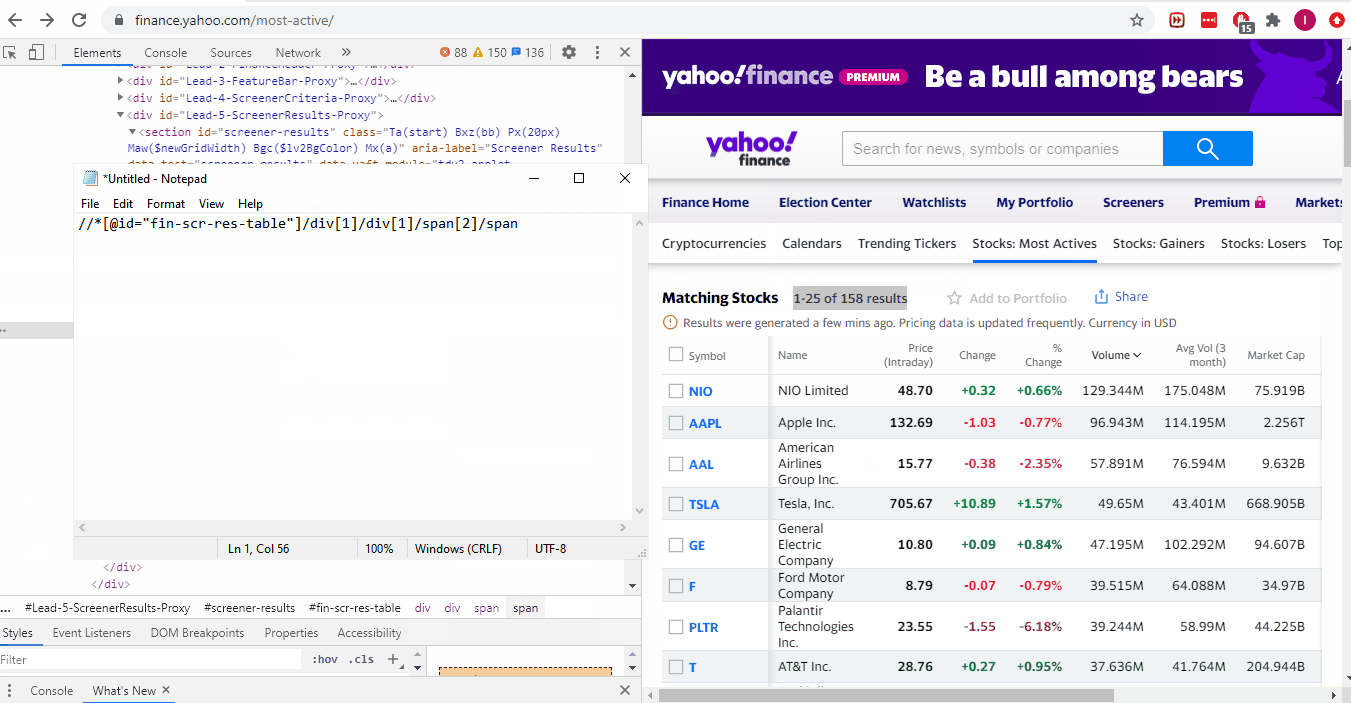
Мы извлекаем общее количество страниц так же, как извлекали любые данные из HTML-страниц в предыдущих руководствах.
Приведенный ниже код выполнит наш алгоритм нумерации страниц:

Таким образом, полный код паука будет:
import scrapy
# Import the ItemObjects
from ..items import YahooscrapingItem
class MostactiveSpider(scrapy.Spider):
name = 'mostactive'
def start_requests(self):
urls = ['https://finance.yahoo.com/most-active/'] # Most active start URL
for url in urls:
yield scrapy.Request(url=url, callback=self.get_pages)
def get_pages(self, response):
count = str(response.xpath('// *[ @ id = "fin-scr-res-table"] / div[1] / div[1] / span[2] / span').css(
'::text').extract())
total_results = int(count.split()[-2])
total_offsets = total_results // 25 + 1
offset_list = [i * 25 for i in range(total_offsets)]
for offset in offset_list:
yield scrapy.Request(url=f'https://finance.yahoo.com/most-active?count=25&offset={offset}', callback=self.get_stocks)
def get_stocks(self, response):
# Get all the stock symbols
stocks = response.xpath('//*[@id="scr-res-table"]/div[1]/table/tbody//tr/td[1]/a').css('::text').extract()
for stock in stocks:
# Follow the link to the stock details page.
yield scrapy.Request(url=f'https://finance.yahoo.com/quote/{stock}?p={stock}', callback=self.parse)
def parse(self, response):
#Declare the item objects
items = YahooscrapingItem()
#Save the extracted data in the item objects
items['stock_name'] = response.xpath('//*[@id="quote-header-info"]/div[2]/div[1]/div[1]/h1').css('::text').extract()
items['intraday_price'] = response.xpath('//*[@id="quote-header-info"]/div[3]/div[1]/div/span[1]').css('::text').extract()
items['price_change'] = response.xpath('//*[@id="quote-header-info"]/div[3]/div[1]/div/span[2]').css('::text').extract()
yield items
Настал критический момент. Это сработает? Достаточно ли 36 строк кода, чтобы очистить данные более 200 (теоретически тысяч) акций? Только один способ узнать. Открываем терминал и выполняем следующее:


Поздравляю! 239 штоков (на момент написания) были очищены. Теперь вы узнали, как очищать страницу, переходить по ссылкам и перемещаться по страницам.
Заключение:
На этом мы завершаем серию из трех частей, посвященных парсингу Scrapy. Надеюсь, вы получили пользу от этих статей. Если у вас есть отзывы, комментарии или идеи, пожалуйста, оставьте их в разделе комментариев.
Спасибо, что нашли время прочитать мою статью.
Если вы хотите увидеть код, использованный в этой статье или в предыдущих частях серии, перейдите по ссылкам ниже:
GitHub: https://rb.gy/yrgaa5
Часть I: https://rb.gy/sc1udy
Часть II: https://rb.gy/ka3zhu
Отказ от ответственности: есть много тем, которые я пропустил, поскольку основное внимание в этом руководстве уделяется тому, чтобы код работал по принципу «сверху вниз». Я рекомендую вам прочитать документацию по scrapy, чтобы получить больше знаний.
Ваше здоровье!