Токены и N-граммы с оценочными метриками были рассмотрены в Части 2 этой серии статей как введение в НЛП.

В этой статье после краткого обсуждения анализа данных вы найдете:
- Маркировка POS.
- Стемминг.
- лемматизация.
Что такое парсинг данных?
Традиционный синтаксический анализ предложений выполняется как метод понимания точного значения предложения или слова. Обычно это объясняет важность различных делений, таких как подлежащее и сказуемое. Для компьютера синтаксический анализ данных представляет собой аналогичный процесс, в котором он анализирует строку, разбивая ее на составные части, при этом каждый из полученных компонентов превращается в значимые для системы фрагменты.
Зачем нужен парсинг данных?
После предварительной обработки и очистки человеческому разуму кажется интуитивно понятным, что текст стал чистым и легко понять последовательность значимых слов. Мы понимаем части речи, мы понимаем понятия подлежащего и сказуемого. Однако для машины они все равно не в полезном виде. Текст по-прежнему избыточен и не передает машине правил грамматики.
Для человеческого разума последовательность слов — «письмо, напечатанное Рави» — имеет такой же смысл, как и «письмо, напечатанное Рави». Но для машины ни одно из утверждений не имело смысла. Он по-прежнему не понимает, что «рави» — это подлежащее, и не понимает, что «напечатал» — это прошедшее время глагола. Заставляет вас чувствовать благодарность за этот ваш ум, не так ли? Чтобы направить систему и дать ей некоторое представление о словах, мы обычно выполняем набор шагов.
Маркировка POS
Это первый шаг в объяснении грамматических правил незнакомого текста системе. Мы понимаем тот факт, что БЕЖАТЬ — это ГЛАГОЛ, потому что он подразумевает действие. Хотя машина имеет доступ к словарю, чтобы понять определение RUN, ей нужно сказать через определение, что это ГЛАГОЛ. Подобно тому, как первоклассник понимает глаголы через своего учителя, на этом этапе пометка является учителем для машины 1-го класса.
POS означает часть речи. Тегирование POS — это процесс маркировки слова в корпусе соответствующей частью речевого тега на основе его контекста и определения.
Есть много способов добиться этого:
- Методы, основанные на лексике. Назначенный тег POS является наиболее часто встречающимся со словом в обучающем корпусе.
- Методы на основе правил — присвоенный тег POS основан на правилах. Например, правило, которое гласит, что слова, оканчивающиеся на «ed» или «ing», должны быть назначены глаголу.
- Вероятностные методы. Назначенный тег POS основан на вероятности появления конкретной последовательности тегов.
- Методы глубокого обучения. Также существуют рекуррентные нейронные сети, которые можно использовать для маркировки POS.
from nltk import pos_tag
pos_tag(['the', 'cat', 'sat', 'in', 'the', 'hat'])
# Output
# [('the', 'DT'),('cat', 'NN'),('sat', 'VBD'),('in', 'IN'),
# ('the', DT'),('hat', 'NN')]
В приведенном выше результате:
- ДТ — Определитель
- NN — существительное в единственном числе или масса
- VBD — прошедшее время глагола
- IN — предлог
Стемминг и лемматизация
В некоторых случаях состояние предложения имеет значение, а в некоторых случаях оно не имеет значения. В примере мы видим, что SAT соответственно классифицируется как прошедшее время. Однако, например, когда я создаю приложение, которое обнаруживает глаголы и классифицирует предложение как предложение, указывающее на какое-то действие, время не имеет значения. Точно так же существует множество приложений, где нам просто нужно слово в его простейшем виде. Для решения проблемы у нас есть такие понятия, как стемминг и лемматизация.
Стемминг — это процесс приведения слов к их основе, основе или корневой форме. Здесь мы работаем с общими суффиксами, обозначающими времена, и вырезаем их из слова.
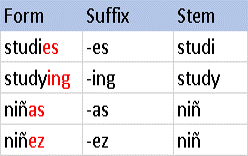
Если посмотреть на таблицу слева, то обнаруживается очевидная проблема, не так ли? Студия не является корнем какого-либо английского слова. Удаление суффиксов, таких как ed и es, — это наивный метод, позволяющий избавиться от ненужных накладных расходов. В качестве альтернативы решению этой проблемы, чтобы убедиться, что такие слова, как изученный, восходят к слову изучать, мы используем лемматизацию.
Лемматизация — это процесс группировки измененных форм слова, чтобы их можно было проанализировать как единый элемент, идентифицируемый по лемме слова или словарной форме. Требуется понятный словарь, чтобы сопоставить все варианты слова с его собственным корневым словом. В отличие от Стемминга, с помощью словаря он

гарантирует, что слова точно сопоставлены с исходным корнем.
Как видно, стемминг преобразовал обучение в обучение и обучениев обучение. Несмотря на происхождение, есть еще 2 разных слова, которые машина должна обрабатывать. Лемматизация, с другой стороны, сопоставляет слова studying и studies со словом study. Таким образом, повышается эффективность, но из-за поиска по словарю время, затрачиваемое на лемматизацию данных, намного больше, чем на сбор данных.
В следующей части серии вы найдете векторы и векторизаторы.
Всем удачного обучения! Я надеюсь, что мои статьи помогут вам узнать больше. Дайте мне знать, если есть что-то, что мне нужно улучшить! Хлопайте, подписывайтесь и делитесь!