Как программист может получить выгоду от использования R? Вот 6 основных пакетов.

R - это язык программирования, созданный Россом Ихакой и Робертом Джентльманом в 1993 году. Он был разработан для аналитики, статистики и визуализации данных. В настоящее время R может обрабатывать все, от базового программирования до машинного обучения и глубокого обучения.
R работает лучше всего, когда применяется ко всему, что связано с данными, например к статистике, науке о данных и машинному обучению.
Этот язык наиболее широко используется в академических кругах, но многие крупные компании, такие как Google, Facebook, Uber и Airbnb, используют его ежедневно.
Сегодня вы научитесь:
- Загрузить наборы данных
- Очистить веб-страницы
- Создавайте REST API
- Анализируйте данные и показывайте статистические сводки
- Визуализировать данные
- Обучите модель машинного обучения
- Разрабатывать простые веб-приложения
Загрузить наборы данных
Чтобы выполнить какой-либо анализ, вам сначала нужно загрузить данные. С R вы можете подключиться к любому источнику данных, который только можете вообразить. Простой поиск в Google даст либо готовую библиотеку, либо пример вызовов API для любого типа источника данных.
В качестве простой демонстрации мы увидим, как загружать данные CSV. Вы можете найти набор данных Iris в формате CSV по этой ссылке, поэтому, пожалуйста, загрузите его на свой компьютер. Вот как загрузить его в R:
iris <- read.csv("iris.csv")
head(iris)А вот что выводит функция head - первые шесть строк:

Знаете ли вы, что скачивать набор данных не нужно? Вы можете загрузить его из Интернета:
iris <- read.csv("https://gist.githubusercontent.com/netj/8836201/raw/6f9306ad21398ea43cba4f7d537619d0e07d5ae3/iris.csv")head(iris)
Это все замечательно, но что делать, если вы не можете найти подходящий набор данных? Вот где в игру вступает веб-скрапинг.
Веб-скрапинг
Трудно найти хороший набор данных, поэтому иногда приходится проявлять творческий подход. Веб-скрапинг считается одним из наиболее «креативных» способов сбора данных при условии, что вы не пересекаете никаких юридических границ.
В R для этой задачи используется пакет rvest. Поскольку на некоторых веб-сайтах действуют строгие правила в отношении парсинга, нам следует проявлять особую осторожность. В Интернете есть страницы, предназначенные для практического скрапинга, так что это для нас хорошие новости. Мы очистим эту страницу и найдем названия книг в одной категории:
library(rvest)
url <- "http://books.toscrape.com/catalogue/category/books/travel_2/index.html"
titles <- read_html(url) %>%
html_nodes("h3") %>%
html_nodes("a") %>%
html_text()Переменная titles содержит следующие элементы:

Да, это так просто. Просто не переходи никаких границ. Сначала проверьте, есть ли у веб-сайта общедоступный API - если да, то парсить не нужно. Если нет, проверьте их политику.
Создавайте REST API
С практическим машинным обучением возникает проблема развертывания модели. В настоящее время лучший вариант - включить функцию прогнозирования модели в REST API. Чтобы показать, как это сделать эффективно, потребуется как минимум пара статей, поэтому сегодня мы рассмотрим основы.
В R пакет plumber используется для создания REST API. Вот тот, который используется по умолчанию при создании plumber проекта:
library(plumber)
#* @apiTitle Plumber Example API
#* Echo back the input
#* @param msg The message to echo
#* @get /echo
function(msg = "") {
list(msg = paste0("The message is: '", msg, "'"))
}
#* Plot a histogram
#* @png
#* @get /plot
function() {
rand <- rnorm(100)
hist(rand)
}
#* Return the sum of two numbers
#* @param a The first number to add
#* @param b The second number to add
#* @post /sum
function(a, b) {
as.numeric(a) + as.numeric(b)
}У API есть три конечных точки:
/echo- возвращает указанное сообщение в ответе/plot- показывает гистограмму 100 случайных нормально распределенных чисел/sum- складывает два числа
Пакет plumber поставляется с пользовательским интерфейсом Swagger, поэтому вы можете исследовать и тестировать свой API в веб-браузере. Давайте взглянем:

Статистика и анализ данных
Это одна из основных причин, почему R. По этой теме есть целые книги и курсы, поэтому мы рассмотрим только основы. Мы намерены осветить более сложные концепции в следующих статьях, поэтому следите за обновлениями нашего блога, если вас это интересует.
Большая часть операций с данными в R выполняется с помощью пакета dplyr. Тем не менее, нам нужен набор данных, с которым можно работать - Gapminder поможет. Он доступен в R через пакет gapminder. Вот как загрузить обе библиотеки и изучить первую пару строк:
library(dplyr) library(gapminder)head(gapminder)
В консоли вы должны увидеть следующее:

Для выполнения любого вида статистического анализа вы можете использовать встроенные функции R, такие как min, max, range, mean, median, quantile, IQR, sd и var. Это замечательно, если вам нужно что-то конкретное, но простой вызов функции summary предоставит вам достаточно информации, скорее всего:
summary(gapminder)Вот статистическая сводка набора данных Gapminder:

С dplyr вы можете развернуть и сохранить только интересующие данные. Давайте посмотрим, как показать только данные по Польше и как рассчитать общий ВВП:
gapminder %>%
filter(continent == "Europe", country == "Poland") %>%
mutate(TotalGDP = pop * gdpPercap)Соответствующие результаты отображаются в консоли:

Визуализация данных
R известен своими безупречными возможностями визуализации данных. Пакет ggplot2 - хорошая отправная точка, поскольку он прост в использовании и по умолчанию отлично выглядит. Мы будем использовать его, чтобы сделать пару базовых визуализаций набора данных Gapminder.
Для начала мы создадим линейную диаграмму, сравнивающую общее население Польши с течением времени. Сначала нам нужно отфильтровать набор данных, чтобы он отображал данные только по Польше. Ниже вы найдете фрагмент кода для импорта библиотек, фильтрации наборов данных и визуализации данных:
library(dplyr)
library(gapminder)
library(scales)
library(ggplot2)
poland <- gapminder %>%
filter(continent == "Europe", country == "Poland")
ggplot(poland, aes(x = year, y = pop)) +
geom_line(size = 2, color = "#0099f9") +
ggtitle("Poland population over time") +
xlab("Year") +
ylab("Population") +
expand_limits(y = c(10^6 * 25, NA)) +
scale_y_continuous(
labels = paste0(c(25, 30, 35, 40), "M"),
breaks = 10^6 * c(25, 30, 35, 40)
) +
theme_bw()Вот соответствующий результат:

Вы можете получить аналогичную визуализацию с первыми двумя строками кода - остальные добавлены для стилизации.
Пакет ggplot2 может отображать практически любой тип визуализации данных, поэтому давайте теперь рассмотрим гистограммы. Мы хотим визуализировать среднюю продолжительность жизни в европейских странах в 2007 году. Вот фрагмент кода для фильтрации и визуализации набора данных:
europe_2007 <- gapminder %>%
filter(continent == "Europe", year == 2007)
ggplot(europe_2007, aes(x = reorder(country, -lifeExp), y = lifeExp)) +
geom_bar(stat = "identity", fill = "#0099f9") +
geom_text(aes(label = lifeExp), color = "white", hjust = 1.3) +
ggtitle("Average life expectancy in Europe countries in 2007") +
xlab("Country") +
ylab("Life expectancy (years)") +
coord_flip() +
theme_bw()Вот как выглядит диаграмма:

И снова первые две строки кода для визуализации будут давать аналогичный результат. Остальное здесь, чтобы оно выглядело лучше.
Обучение модели машинного обучения
Еще одна область, с которой R легко справляется. Пакет rpart отлично подходит для машинного обучения, и мы будем использовать его, чтобы создать классификатор для известного набора данных Iris. Набор данных встроен в R, поэтому вам не нужно беспокоиться о его загрузке вручную. caTools используется для разделения поездов / тестов.
Вот как загрузить библиотеки, выполнить разделение «поезд / тест», подогнать и визуализировать модель:
library(caTools)
library(rpart)
library(rpart.plot)
set.seed(42)
sample <- sample.split(iris, SplitRatio = 0.75)
iris_train = subset(iris, sample == TRUE)
iris_test = subset(iris, sample == FALSE)
model <- rpart(Species ~., data = iris_train, method = "class")
rpart.plot(model)Выполнение фрагмента не должно занимать больше секунды или двух. После этого вам будет представлена следующая визуализация:
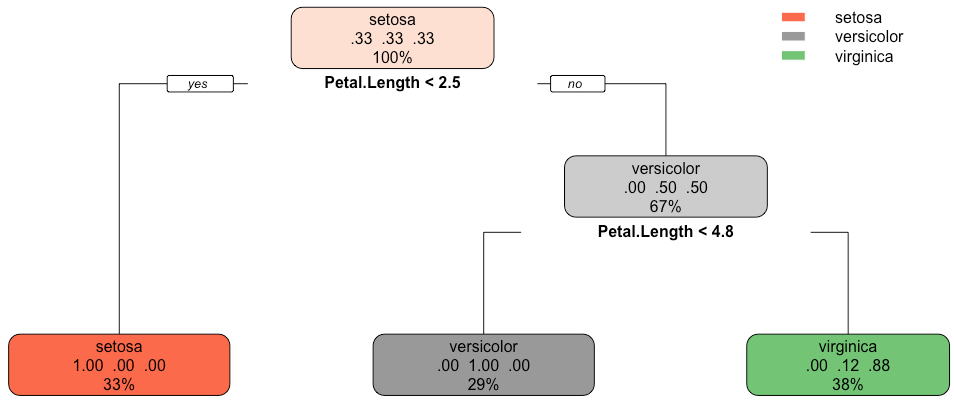
Рисунок выше рассказывает вам все о процессе принятия решения алгоритмом. Теперь мы можем оценить модель на ранее невидимых данных (набор тестов). Вот как делать прогнозы, печатать матрицу путаницы и точность:
preds <- predict(model, iris_test, type = "class")
confusion_matrix <- table(iris_test$Species, preds)
print(confusion_matrix)
accuracy <- sum(diag(confusion_matrix)) / sum(confusion_matrix)
print(accuracy)
Как видите, мы получили модель с точностью 95% всего с парой строк кода.
Разработка простых веб-приложений
На примере веб-приложения мы увидим, как создать простые интерактивные информационные панели, отображающие диаграмму разброса двух столбцов, указанных пользователем. Выбранный набор данных также встроен в R - mtcars.
Вот сценарий для приложения Shiny:
library(shiny)
library(ggplot2)
ui <- fluidPage(
sidebarPanel(
width = 3,
tags$h4("Select"),
varSelectInput(
inputId = "x_select",
label = "X-Axis",
data = mtcars
),
varSelectInput(
inputId = "y_select",
label = "Y-Axis",
data = mtcars
)
),
mainPanel(
plotOutput(outputId = "scatter")
)
)
server <- function(input, output) {
output$scatter <- renderPlot({
col1 <- sym(input$x_select)
col2 <- sym(input$y_select)
ggplot(mtcars, aes(x = !!col1, y = !!col2)) +
geom_point(size = 6, color = "#0099f9") +
ggtitle("MTCars Dataset Explorer") +
theme_bw()
})
}
shinyApp(ui = ui, server = server)А вот и соответствующее приложение Shiny:

Эта панель управления настолько проста, насколько это возможно, но это не значит, что вы не можете разрабатывать красивые приложения с помощью Shiny.
Заключение
В заключение - R может делать почти все, что может делать язык программирования общего назначения. Вопрос не в «Может ли R это сделать», а в том, «Подходит ли R для работы?».
Если вы работаете над чем-либо, связанным с данными, то да, R может это сделать и является идеальным кандидатом на эту работу.
Если вы не собираетесь работать с данными каким-либо образом, формой или формой, R может быть не оптимальным инструментом. Конечно, R может делать почти все, но некоторые задачи намного проще выполнять на Python или Java.
Хотите узнать больше о R? Начните здесь:
- Горячие клавиши и приемы RStudio
- Как написать готовый к производству R-код: инструменты и шаблоны
- Видео: создание и настройка простой блестящей панели инструментов
Первоначально опубликовано на https://appsilon.com 1 декабря 2020 г.