На прошлой неделе я обучил модель YOLOv3 и модель YOLOv3-tiny локализации штрих-кода с помощью глубокого обучения. Сравнивая их производительность, я отказался от YOLOv3, потому что YOLOv3-tiny намного быстрее. Я доволен скоростью обнаружения QR-кода, запустив модель YOLOv3-tiny на моей видеокарте GeForce RTX2060. В этой статье я заставлю Darknet декодировать QR-код, интегрировав SDK штрих-кода Dynamsoft C/C++. Моя цель — выяснить, можно ли использовать глубокое обучение для повышения производительности распознавания штрих-кода.
Штрих-код SDK Скачать
Dynamsoft C/C++ Barcode SDK для Windows
Даркнет Скачать
git clone https://github.com/AlexeyAB/darknet --depth 1
Распознавание штрих-кода с помощью глубокого обучения и компьютерного зрения
Давайте найдем функцию run_detector(), которая анализирует входные аргументы в detector.c. Продублируйте строку вызова функции test_detector() и переименуйте ее в штрих-код:
if (0 == strcmp(argv[2], "barcode")) barcode_detector(datacfg, cfg, weights, filename, thresh, hier_thresh, dont_show, ext_output, save_labels, outfile, letter_box, benchmark_layers);else if (0 == strcmp(argv[2], "test")) test_detector(datacfg, cfg, weights, filename, thresh, hier_thresh, dont_show, ext_output, save_labels, outfile, letter_box, benchmark_layers);
В зависимости от модификации команда распознавания штрих-кода:
darknet detector barcode ...
Функция barcode_detector() пока аналогична функции test_detector(). Код, который я собираюсь изменить, заключается в том, чтобы получить ограничивающую рамку QR-кода по мере выполнения прогнозирования сети, а затем вызвать функцию DBR_DecodeBuffer() для декодирования QR-кода со значениями региона.
Вот код для получения ограничивающей рамки объекта и имени класса:
int selected_detections_num;detection_with_class* selected_detections = get_actual_detections(dets, nboxes, thresh, &selected_detections_num, names);int i;for (i = 0; i < selected_detections_num; ++i) {const int best_class = selected_detections[i].best_class;if (selected_detections[i].det.prob[best_class] < 0.5) continue;printf("%s: %.0f%%\n\n", names[best_class], selected_detections[i].det.prob[best_class] * 100);box b = selected_detections[i].det.bbox;int left = (b.x - b.w / 2.)*im.w;int right = (b.x + b.w / 2.)*im.w;int top = (b.y - b.h / 2.)*im.h;int bot = (b.y + b.h / 2.)*im.h;decode_barcode_buffer(barcodeReader, image_buffer, im.w, im.h, im.c, TRUE, left, right, top, bot);}
Мы можем отфильтровать результаты по значению достоверности. Я установил 0,5 в качестве порога.
Тип буфера изображения, используемый для DBR_DecodeBuffer(), — unsigned char*, а тип данных, используемых для предсказания сети, — float *, что несовместим с unsigned char*. Чтобы понять, как получить правильный тип данных, мы можем перейти к строке:
image im = load_image(input, 0, 0, net.c);
Проследив стек вызовов load_image() ‹ load_image_cv() ‹ mat_to_image(), мы можем увидеть, как float * преобразуется из unsigned char *:
extern "C" image mat_to_image(cv::Mat mat){int w = mat.cols;int h = mat.rows;int c = mat.channels();image im = make_image(w, h, c);unsigned char *data = (unsigned char *)mat.data;int step = mat.step;for (int y = 0; y < h; ++y) {for (int k = 0; k < c; ++k) {for (int x = 0; x < w; ++x) {im.data[k*w*h + y*w + x] = data[y*step + x*c + k] / 255.0f;}}}return im;}
Чтобы получить массив символов без знака, декодированный из файла изображения, я создаю две новые функции, load_image_buffer() и buffer_to_image(), чтобы заменить mat_to_image(). сильный>:
extern "C" void load_image_buffer(char *filename, int channels, unsigned char** buffer, int *width, int *height, int *channel){cv::Mat mat = load_image_mat(filename, channels);int w = mat.cols;int h = mat.rows;int c = mat.channels();unsigned char *data = (unsigned char *)mat.data;int size = sizeof(unsigned char) * w * h * c;unsigned char* image_buffer = (unsigned char*)malloc(size);memcpy(image_buffer, data, size);*buffer = image_buffer;*width = w;*height = h;*channel = c;}extern "C" image buffer_to_image(unsigned char* buffer, int w, int h, int c){cv::Mat mat = cv::Mat(h, w, CV_8UC(c));int step = mat.step;image im = make_image(w, h, c);unsigned char *data = buffer;for (int y = 0; y < h; ++y) {for (int k = 0; k < c; ++k) {for (int x = 0; x < w; ++x) {im.data[k*w*h + y*w + x] = data[y*step + x*c + k] / 255.0f;}}}return im;}
Наконец, я реализую функцию decode_barcode_buffer() для декодирования штрих-кода из полного изображения или декодирования региона для QR-кода, обнаруженного моделью YOLO.
Разница заключается в том, что первый полностью полагается на алгоритм компьютерного зрения, а второй использует глубокое обучение для обнаружения области QR-кода и алгоритм компьютерного зрения для декодирования QR-кода из определенной области, которая может быть намного меньше, чем полный размер изображения.
Мне не терпится собрать и протестировать программу.
> build.ps1> darknet.exe detector barcode qrcode.data qrcode-yolov3-tiny.cfg qrcode-yolov3-tiny_last.weights 20201105151910.jpg
Оценка эффективности
Только компьютерное зрение
Barcode buffer decoding in 175.577000 milli-seconds.
Глубокое обучение + компьютерное зрение
20201105151910.jpg: Predicted in 4.021 milli-seconds.Barcode buffer decoding in 84.98 milli-seconds.
Кажется, что глубокое обучение приводит к огромному скачку производительности. Однако не горячитесь слишком рано. Давайте проанализируем недостающие части через весь процесс распознавания штрих-кода:
- Прочитайте изображение в беззнаковый массив символов с помощью OpenCV API. Эта часть используется в обоих случаях, поэтому мы можем ее игнорировать.
- Преобразование массива беззнаковых символов в объект изображения. Эта часть занимает 120,461 миллисекунды.
- Измените размер изображения до 416 × 416 — размер, используемый для обучения моей модели. Эта часть занимает 49,898 миллисекунд.
The time cost of computer vision only = 175.577000 ms.The time cost of deep learning and computer vision = 120.461 + 49.898 + 4.021 + 84.98 = 259.36ms.
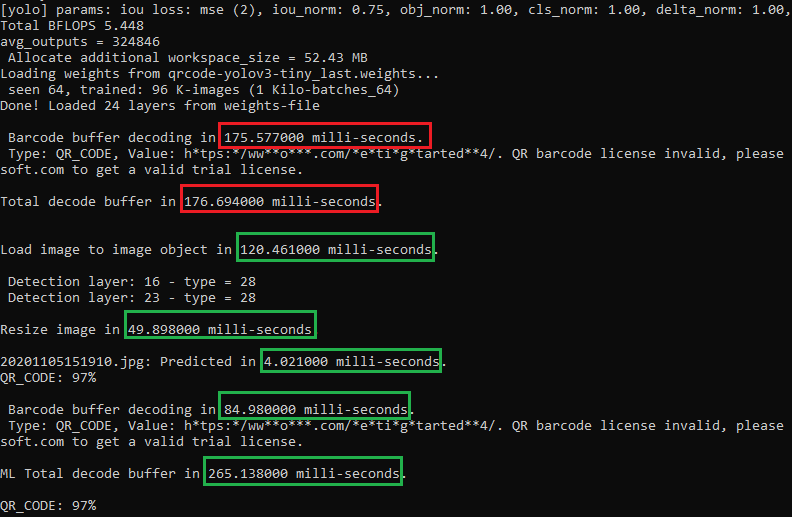

Согласно подсчету общего прошедшего времени, чистый алгоритм компьютерного зрения является победителем для распознавания QR-кода на моем ПК.
Плюсы и минусы глубокого обучения для сканирования штрих-кода
Плюсы
- Поскольку подход к предварительной обработке изображения (обрезка объектов штрих-кода из изображения) может значительно повысить производительность.
Минусы
- Обучение модели глубокого обучения стоит дорого.
- Загрузка и предварительная обработка изображений занимают гораздо больше времени, чем алгоритмы компьютерного зрения.
- Сильно зависит от производительности графического процессора.
Все вышеизложенные пункты основаны на сравнении глубокого обучения и Dynamsoft Barcode Reader SDK. Тем не менее, не все SDK для штрих-кодов столь же эффективны, как Dynamsoft Barcode Reader SDK. Я еще не тестировал другие SDK штрих-кода, реализованные в алгоритме компьютерного зрения. Вероятно, глубокое обучение могло бы стать хорошим дополнением к бесплатным SDK для штрих-кодов, таким как ZXing.
Исходный код
https://github.com/yushulx/darknet
Первоначально опубликовано на https://www.dynamsoft.com 15 ноября 2020 г.