XG Boost - это очень мощный алгоритм машинного обучения, который может иметь более высокий уровень точности, если задан широким диапазоном параметров в контролируемом машинном обучении. XGBoost означает экстремальное усиление градиента. XG Boost работает с параллельным усилением дерева, которое предсказывает цель, комбинируя результаты нескольких слабых моделей . Библиотека XGBoost реализует алгоритм дерева решений с повышением градиента. Давайте рассмотрим подробнее на примере.
Здесь мы используем набор данных uci по сердечным заболеваниям от kaggle. Также мы пытаемся предсказать вероятность возникновения сердечных заболеваний и какие особенности для этого важнее. Вот ссылка на данные.
Сначала давайте импортируем панд для чтения данных, используя следующую строку кода.
import pandas as pdТеперь давайте прочитаем данные в фрейм данных
data = pd.read_csv(‘../input/heart-disease-uci/heart.csv’)data
Это прочитает данные в фрейм данных, называемый данными, и даст следующий результат.

Теперь давайте посмотрим информацию о данных, чтобы узнать больше о данных, используя следующий код.
data.info()Это даст следующую информацию о данных. Мы можем видеть типы данных, столбцы, нулевые значения и т. Д.
<class 'pandas.core.frame.DataFrame'> RangeIndex: 303 entries, 0 to 302 Data columns (total 14 columns): # Column Non-Null Count Dtype 0 age 303 non-null int64 1 sex 303 non-null int64 2 cp 303 non-null int64 3 trestbps 303 non-null int64 4 chol 303 non-null int64 5 fbs 303 non-null int64 6 restecg 303 non-null int64 7 thalach 303 non-null int64 8 exang 303 non-null int64 9 oldpeak 303 non-null float64 10 slope 303 non-null int64 11 ca 303 non-null int64 12 thal 303 non-null int64 13 target 303 non-null int64 dtypes: float64(1), int64(13) memory usage: 33.3 KB
Давайте посмотрим на другую форму информации с помощью следующего кода
data.describe()
Это даст описание фрейма данных следующим образом.

В описании указано количество, среднее, стандартное, минимальное, 25%, 50%, 75% и максимальное количество всех столбцов. Это еще больше помогает нам лучше понять данные. Теперь давайте импортируем библиотеки numpy, xgboost и sklearn.metrics. Для регрессии нам нужна среднеквадратическая ошибка.
import xgboost as xgb from sklearn.metrics import mean_squared_error import numpy as np
Затем нам нужно присвоить значения X и Y. Здесь мы также разделяем целевую переменную и остальные переменные, используя .iloc для подмножества данных.
X, Y = data.iloc[:,:-1],data.iloc[:,-1]
Теперь нам нужно преобразовать набор данных в оптимизированную структуру данных под названием Dmatrix, которую поддерживает XGBoost и которая дает ей признанный прирост производительности и эффективности.
data_dmatrix = xgb.DMatrix(data=X,label=Y)
Теперь мы создадим набор поездов и тестов для перекрестной проверки результатов с помощью функции train_test_split из модуля model_selection sklearn с размером test_size, равным 20% данных. Кроме того, для обеспечения воспроизводимости результатов также назначается random_state.
from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=123)
Следующим шагом является создание экземпляра объекта регрессора XGBoost путем вызова класса XGBRegressor () из библиотеки XGBoost с гиперпараметрами, переданными в качестве аргументов.
xg_reg = xgb.XGBRegressor(objective ='reg:linear', colsample_bytree = 0.3, learning_rate = 0.1,max_depth = 5, alpha = 10, n_estimators = 10)
Теперь подгоним регрессор к обучающей выборке с помощью метода .fit ().
xg_reg.fit(X_train,Y_train)
вывод после подгонки показывает многие гиперпараметры следующим образом.
XGBRegressor(alpha=10, base_score=0.5, booster='gbtree',colsample_bylevel=1,colsample_bynode=1, colsample_bytree=0.3, gamma=0, gpu_id=-1,importance_type='gain', interaction_constraints='',learning_rate=0.1, max_delta_step=0, max_depth=5,min_child_weight=1, missing=nan, monotone_constraints='()', n_estimators=10, n_jobs=0, num_parallel_tree=1,objective='reg:linear', random_state=0, reg_alpha=10, reg_lambda=1,scale_pos_weight=1, subsample=1, tree_method='exact',validate_parameters=1, verbosity=None)
Давайте спрогнозируем вышеуказанную модель с помощью метода .predict ().
preds = xg_reg.predict(X_test) preds
Результат выглядит следующим образом:
array([0.62361383, 0.436409 , 0.4638252 , 0.4234442 , 0.5576368 , 0.36139676, 0.6453048 , 0.48385164, 0.61654013, 0.53615165, 0.5271714 , 0.5342451 , 0.36847046, 0.36139676, 0.5126163 , 0.42248273, 0.47246233, 0.52830946, 0.4810629 , 0.5204763 , 0.590331 , 0.47579026, 0.6621046 , 0.39579174, 0.49821952, 0.53383183, 0.4865605 , 0.5409056 , 0.43799824, 0.53313845, 0.4234442 , 0.5955741 , 0.5409056 , 0.45628968, 0.5528887 , 0.60049963, 0.61878484, 0.6078624 , 0.62996906, 0.59981364, 0.64041364, 0.55104494, 0.5254018 , 0.62684685, 0.55517054, 0.48204178, 0.36139676, 0.44480985, 0.60275817, 0.6277096 , 0.44678292, 0.42796794, 0.6621046 , 0.5477844 , 0.49884164, 0.62160766, 0.55104494, 0.59651303, 0.5327918 , 0.55396104, 0.5179344 ], dtype=float32)
Давайте рассчитаем среднеквадратичное отклонение с помощью функции mean_sqaured_error из модуля метрик sklearn.
rmse = np.sqrt(mean_squared_error(Y_test, preds))
print("RMSE: %f" % (rmse))
Результат будет следующим.
RMSE: 0.449886
Мы можем видеть, что прогноз RMSE для сердечных заболеваний оказался таким, что наша модель может предсказать с этой ошибкой. Чтобы проанализировать, какая функция является более важным фактором, нам нужно классифицировать, и для этого используется XGBclassifier (). Импортируем необходимые библиотеки для этой задачи.
from numpy import loadtxt from xgboost import XGBClassifier from xgboost import plot_importance from matplotlib import pyplot
Назовем классификатор, используя следующую строку
model = XGBClassifier()
Здесь мы пытаемся подогнать модель
model.fit(X, Y)
Приведенное выше дает следующий результат с гиперпараметрами.
XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1,gamma=0,gpu_id=-1, importance_type='gain', interaction_constraints='', learning_rate=0.300000012, max_delta_step=0, max_depth=6, min_child_weight=1,missing=nan,monotone_constraints='()', n_estimators=100,n_jobs=0,num_parallel_tree=1,random_state=0, reg_alpha=0, reg_lambda=1,scale_pos_weight=1,subsample=1, tree_method='exact',validate_parameters=1,verbosity=None)
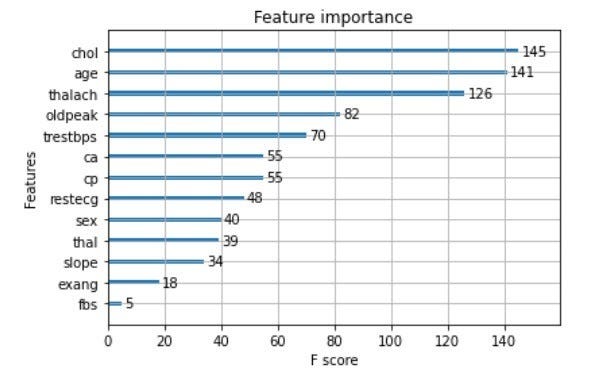
Здесь мы пытаемся построить модель важности, используя этот код.
plot_importance(model) pyplot.show()
Вывод показывает порядок важности
Заключение
Мы построили модель XGBoost для прогнозирования вероятности сердечных заболеваний, и модель имеет среднеквадратичное отклонение 0,45. Мы также обнаружили, что наиболее важным фактором при обнаружении болезни сердца является холестерин.
Первоначально опубликовано на https://www.numpyninja.com 6 ноября 2020 г.