Применение алгоритма Apriori с нуля в PySpark

Вероятность покупки того или иного продукта покупателями может зависеть от нескольких факторов. Примеры таких факторов, как история транзакций клиента, демографические характеристики и интересы. Итак, что, если у нас нет этих факторов. Это означает, что покупатель раньше не был в нашем магазине и у нас нет его данных (даже пола). В таких случаях есть методы, с помощью которых мы можем найти продукты, которые покупатель может купить. Обычно данные, используемые в этих методах, принадлежат другим покупателям, которые ранее совершали покупки в магазине. Эти методы принимают все транзакции, контролируют каждый элемент (продукт) в транзакциях и находят шаблоны, которые показывают, какие продукты чаще всего покупаются покупателями в одной и той же корзине. Методы, которые находят эти шаблоны, называются анализом частых шаблонов или ассоциативным правилом [1].
Априори - это один из алгоритмов, который используется для частого поиска паттернов. В этой статье я собираюсь объяснить, как применить априорный алгоритм с Spark в Python. Важно знать, как работает априорный алгоритм, прежде чем вы начнете применять приведенные ниже коды. Я также собираюсь объяснить основы априори, но если вы хотите изучить его подробно, прочтите мою предыдущую статью под названием Что такое« априорный алгоритм и как он работает» ». В этой статье будут рассмотрены следующие части,
- Пример применения Априори
- Что такое Spark и почему мы должны его использовать
- Как подготовить данные транзакции
- Априорные термины и основы
- Применение Apriori с нуля с помощью PySpark
Сокращение: вы можете найти исходный код реализации алгоритма Apriori на python PySpark в моем репозитории GitHub, и вы можете использовать модуль, созданный для Spark.
Пример случая
Предположим, в Нью-Йорке есть овощной магазин. Этот овощной магазин является крупнейшим овощным магазином Нью-Йорка, и у него миллионы клиентов в месяц. Хозяин овощного магазина покупает тонны продуктов всего за один день. Однако в некоторые дни она не может продать все продукты и выбрасывает их, потому что срок их службы истекает. Таким образом, выбрасывание продуктов приводит к большим потерям. Поэтому владелец овощного магазина решил обновить свою маркетинговую стратегию. Она хотела нанять специалиста по данным для своего овощного магазина. Обязанность этого специалиста по данным - создать алгоритм, который может найти продукты, которые клиенты могут купить после того, как они положат их в свою корзину. Она собиралась предложить скидку на продукты, которые алгоритм находит для каждого конкретного покупателя. Благодаря этому алгоритму она планирует продавать свою продукцию точно в срок. Отличная идея!
А теперь подумайте, что нанятый ею специалист по данным - это вы, с чего бы вы начали?
Среда
Apache Spark [2] - это аналитический движок с открытым исходным кодом, ориентированный на скорость, простоту использования и распределенную систему. Он может запускать алгоритмы машинного обучения в 100 раз быстрее, чем нераспределенные системы [3]. Если существует массивный набор данных, Spark был бы лучшим вариантом для анализа этого набора данных. Хорошо, давайте вернемся к нашему примеру: вам придется иметь дело с миллионами данных о транзакциях, учитывая, что у Greengrocer миллионы клиентов в месяц. Для обеспечения более быстрого анализа данных одним из лучших вариантов может быть Spark.
Как вы подготавливаете свои данные?
Во-первых, вам следует подготовить набор данных по транзакциям клиентов. Но не следует забывать, что один покупатель может купить один или несколько товаров у овощного магазина, это означает, что в нашем наборе данных не может быть определенного количества столбцов для каждой строки. Поэтому я решил записывать транзакции построчно, разделяя каждый элемент транзакции запятой и сохранять как файл «txt или CSV». Каждая строка представляет каждую транзакцию с элементами, разделенными запятыми. Например, при первой транзакции клиент купил Apple, Mango и Banana, а во второй транзакции клиент купил Banana и Mango. Если у вас есть набор данных как CSV, вы также можете использовать его (он уже разделен запятыми, но не забудьте удалить строку заголовка).
Алгоритм - Априори
Прежде чем приступить к внедрению Apriori на Spark, нам необходимо понять его основные термины и концепции. Алгоритм априори зависит от частот набора элементов. Он создает разные таблицы, которые включают комбинации элементов. Он сканирует основной набор данных, который показывает все транзакции, и определяет частоту, учитывая, сколько раз эти комбинации встречаются в основном наборе данных [4]. Эти частоты называются поддерживаемыми значениями в алгоритме априори. Кроме того, количество таблиц зависит от максимальной длины набора элементов. Если максимальная длина набора элементов равна 5, это означает, что будет 5 таблиц значений поддержки. Однако существует минимальное значение поддержки, которое используется для решения, какой набор элементов должен оставаться в таблице. Допустим, минимальные поддерживаемые значения были выбраны равными 2. Итак, если какой-либо набор элементов встречается в основном наборе данных менее 2 раз, мы должны удалить этот набор элементов из таблицы.
Давайте рассмотрим следующий рисунок, чтобы понять, как работает Apriori. Я взял несколько записей транзакций на следующем примере рисунка, чтобы сделать его простым и понятным.
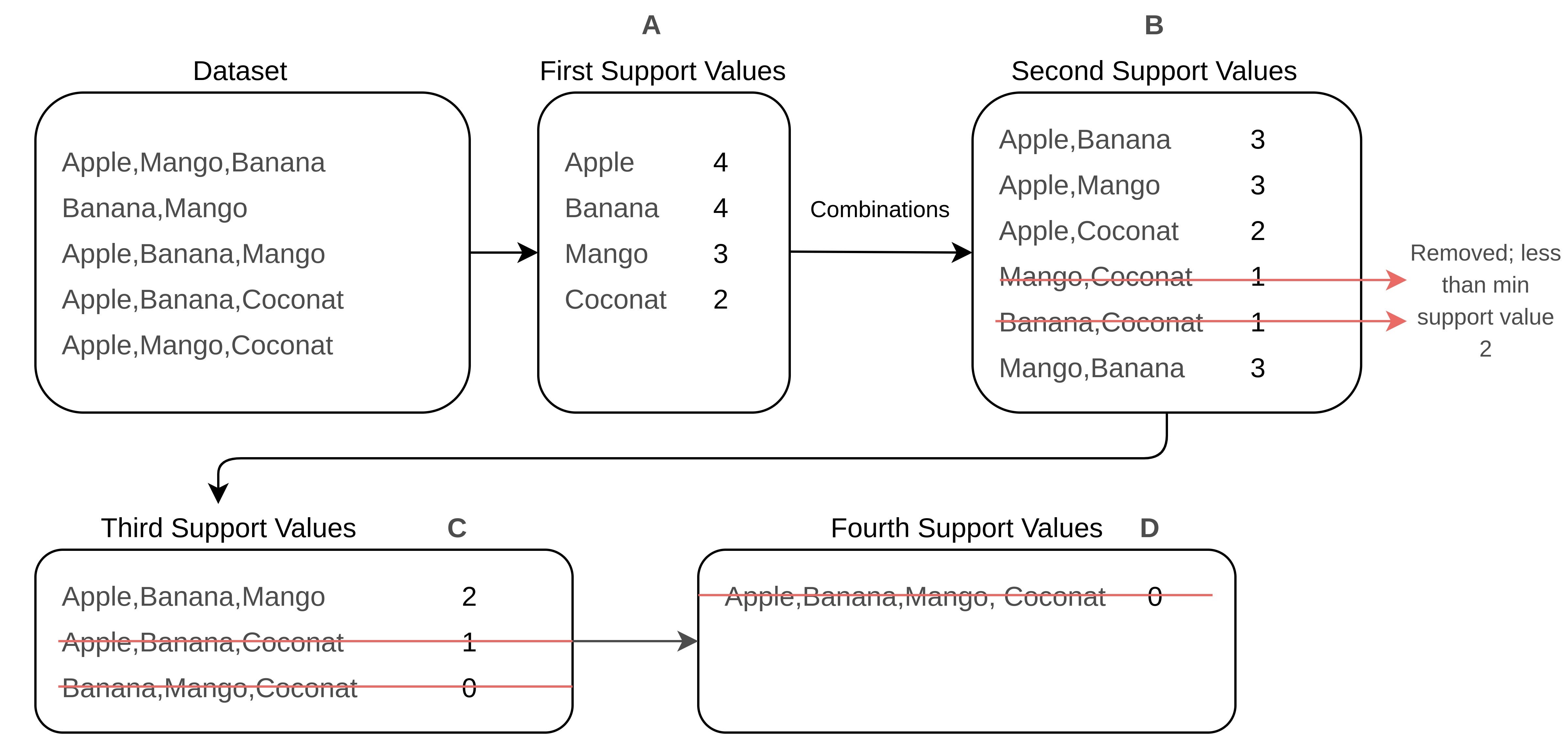
«Набор данных» представляет данные нашей транзакции, и каждая строка в «Наборе данных» показывает каждый набор элементов транзакции, который был куплен в одно и то же время покупателем. В таблице A указаны частоты отдельных элементов. Это первая таблица, которую нам нужно создать для алгоритма Apriori. После таблицы A идет таблица B, которая включает двоичные комбинации отдельных элементов. Самая важная часть здесь в том, что порядок элементов не имеет смысла. Итак, «Apple, Mango» и «Mango, Apple» - это одно и то же. Следовательно, при создании комбинаций элементов необходимо удалить репликации наборов элементов. Как видно из Таблицы B, набор элементов «Банан-Кокос» и «Манго-Кокос», поддерживающие значения которых меньше 2, был удален. Однако в таблице C есть тройные комбинации отдельных элементов и поддерживающие значения, которые показывают, сколько раз встречается в основном наборе данных. Наборы предметов, поддерживающие значения которых меньше 2, также удалены из этой таблицы. Если вы видите Таблицу D, там есть только один набор элементов, поддерживающее значение которого равно 0, и он состоит из четырех отдельных элементов. Эту таблицу не следует учитывать при применении алгоритма. Потому что в основном наборе данных такой транзакции нет.
Итак, как мы можем рассчитать вероятность покупки Mango, если покупатель купил яблоко, используя таблицы поддержки на приведенном выше рисунке? Чтобы рассчитать эту вероятность, нам нужно взять значение поддержки «Манго» и «Манго, Apple» вместе. Значение поддержки «Манго» - 4, а «Манго, яблоко» - 3. Мы можем вычислить вероятность; (3/4) * 100 =% 75. Эта вероятность априори называется достоверностью. Интерпретация этого значения такова: покупатели, покупающие Mango, могут купить Apple со значением достоверности 75%.
Теперь мы знаем, как рассчитать значения поддержки и уверенности. Понятно, что мы можем перейти к алгоритму Априори с PySpark. В следующем разделе мы увидим;
- Чтение данных с PySpark
- Разбор данных в объекты Spark RDD
- Поиск первых значений поддержки элементов с помощью «MapReduce»
- Определение минимального значения поддержки
- Создание следующих таблиц поддержки с помощью «MapReduce»
- Расчет доверительных значений
- Решить, какой продукт покупает клиент с большой уверенностью
Чтение набора данных с помощью PySpark
PySpark работает с RDD, это означает, что нам нужно преобразовать все записи транзакций в несколько RDD. Прежде чем это сделать, нам нужно убедиться, что SparkContext создан, чтобы определить каждую запись RDD и прочитать файл CSV.
Прежде чем приступить к работе с этим разделом, убедитесь, что в вашей системе установлены Spark и PySpark.
Сначала создайте файл python в своем рабочем каталоге под названием «apprioriSpark.py» (или любое другое имя по вашему выбору), а затем вы можете легко создать SparkContext с помощью приведенной ниже команды (вы также должны импортировать SparkContext из P ySpark).
После создания SparkContext мы можем прочитать данные с помощью метода textFile (), который входит в SparkContext. Убедитесь, что ваш файл данных находится в том же каталоге, что и ваш файл python.
Разбор элементов транзакции в RDD
Метод textFile () по умолчанию читает файл построчно, это означает, что каждая строка в нашем CSV-файле будет значением в RDD. Эти RDD включают строки CSV как одно строковое значение (результат в 6-й строке). Вот почему нам нужно отобразить в каждый RDD и разделить эти отдельные значения запятыми, чтобы получить каждый элемент в строках и разделить их в массив RDD. Для этого бегите;
Теперь вы можете ясно видеть, что каждая строка в наборе данных транзакции разделена запятой. И каждый массив в нашем RDD представляет списки элементов, которые являются транзакциями клиентов. Мы успешно перекрасили файл и преобразовали его в объект Spark RDD, учитывая каждую транзакцию, принадлежащую клиентам.
Получение первых значений поддержки предметов для априори
Алгоритм априори зависит от частотности пунктов. Из-за этого, во-первых, нам нужно получить частоты для каждого отдельного элемента. Эти частоты будут нашими первыми значениями поддержки в таблице 1 (как упоминалось в предыдущем разделе). Для этого нам нужно извлечь каждый элемент в RDD в целые элементы массива. Мы можем сделать это с помощью метода «flatMap».
Как видно из результата; Все наши элементы транзакции находятся в едином массиве. Теперь мы можем рассчитать частоту появления каждого уникального товара. Не забываем, что эти частоты будут нашими первыми поддерживаемыми значениями. Если бы мы работали с массивом «NumPy», найти частоты было бы легко. Но мы работаем над RDD, и поэтому нам нужно найти способ получения частот, используя подход «MapReduce». Решение; Сначала мы можем преобразовать каждый элемент в объект «кортеж» и добавить «1» в качестве второго элемента «кортежа». Мы можем просуммировать эти значения, используя метод «reduceByKey» (он похож на метод groupby в SQL). Суммируя вторые числа кортежа, мы можем получить частоту каждого уникального элемента (сколько времени происходит с транзакциями клиентов). Нам также нужно будет перечислить уникальные элементы в разделах функций. Таким образом, мы также можем получить уникальные предметы, используя «отдельный» метод.
Если вы запустите «supportRdd.collect ()» после приведенного выше фрагмента кода, вы получите первые кортежи item -support (предположим, как Таблица A). Как видно из значений поддержки, «Apple» встречается чаще, чем другие. Значит, вероятность покупок «Яблока» больше остальных. Эти значения поддержки получены при рассмотрении каждого элемента отдельно. Нам также необходимо рассмотреть, как они вместе возникают в транзакциях. Благодаря этому мы можем рассчитывать доверительные значения по алгоритму Apriori. Мы увидим эти шаги на следующих занятиях.
Мин. Значение поддержки
Чтобы решить, какие наборы элементов останутся в таблицах поддержки, нам нужно определить минимальное значение поддержки. Мы можем выбрать минимальное значение поддержки как минимальную частоту, которая находится в первом массиве значений поддержки (таблица). Если какие-либо значения поддержки в массивах наборов элементов меньше минимального значения поддержки, мы должны удалить этот набор элементов из этого массива. Если в наших данных не так много записей, минимальная поддержка может быть равна 1. В таких случаях мы можем определить минимальную поддержку как 2 или любое значение больше 1.
В этом примере у нас есть минимальное значение поддержки, которое было найдено как 1. Чтобы получить более согласованный результат, мы можем установить минимальную поддержку как 2. Это означает, что если какой-либо элемент или набор элементов встречается в транзакции менее двух раз, мы выиграли не беру в расчет. Как видно из строки 8, мы отфильтровали нашу первую таблицу набора элементов (которая представляет собой значения поддержки отдельных элементов) в соответствии с минимальным значением поддержки. Мы также создали объект «baseRdd». «BaseRdd» представляет наши первые значения поддержки для каждого отдельного элемента. Этот объект будет обновлен с учетом предстоящих значений поддержки комбинаций. Нам также необходимо определить «supportRdd», который показывает только элементы без значений поддержки. Мы будем использовать его в следующих разделах, чтобы создавать комбинации элементов.
Знакомство с алгоритмом априори
До этого раздела мы нашли только поддерживаемое значение (частоту) каждого элемента. Теперь мы создадим алгоритм, который генерирует комбинации элементов в цикле while. В каждом цикле будут создаваться разные таблицы поддержки. Этот цикл while завершится, когда не будет комбинации, поддерживающее значение которой больше минимального поддерживаемого значения. Этот алгоритм будет контролировать, сколько раз эти комбинации элементов встречаются вместе в наборе данных транзакции в каждом цикле, и сохраняют их в RDD.
Мы уже создали объект supportRdd, который включает только набор элементов первой таблицы без значений поддержки (которые имеют только один элемент в каждой строке). Теперь мы будем использовать этот RDD в цикле while, чтобы объединить его с уникальными элементами, чтобы создать другие таблицы поддержки. Однако этот RDD будет обновляться после каждого цикла. Например;
# Fitst supportRDD ([Apple] , [Mango] , [Banana] , [Grapes]) # After first loop = supportRDD ([Apple,Mango],[Mango,Banana],[Apple,Banana],[Apple,Grapes] ......) # After second loop = supportRDD ([Apple,Mango,Grapes] , [Apple,Banana,Grapes] ........ )
Алгоритм будет фильтровать каждую таблицу комбинаций в соответствии с минимальным значением поддержки. Когда не установлен ни один элемент, цикл будет завершен. Кроме того, нам также необходимо определить функцию, которая может находить репликации внутри объединенного набора элементов. Как упоминалось ранее; наборы (Apple, Mango) и (Mango, Apple) одинаковы для алгоритма Apriori. По этой причине нам необходимо найти такие шаблоны и удалить один из них. Как видно из приведенного ниже фрагмента кода, есть функция под названием «removeReplica». Эта функция удаляет такие повторяющиеся элементы после объединения и возвращает только один из них.
Ага! Мы готовы создать наш цикл while. Во-первых, нам нужно определить переменную, с помощью которой мы можем контролировать длину набора элементов в каждом цикле. В приведенном выше фрагменте кода он обозначен буквой «c». Эта переменная «c» начинается с 2. Почему? Помните, что мы уже создали нашу первую таблицу поддержки как «supportRdd». Итак, в таблице поддержки цикла while будет начинаться с c = 2. Это означает, что первая таблица поддержки, которая будет создана в цикле while, будет иметь наборы элементов, состоящие из 2 элементов. Чтобы создавать комбинации элементов, мы можем использовать «декартову» функцию, которая поставляется с PySpark (в строке 6). Создано мы будем удалять повторяющиеся элементы (в строке 7). Мы будем использовать переменную «c», чтобы фильтровать объединенные элементы больше, чем переменную «c» (в строке 9). Однако мы также используем «отдельный» метод, чтобы на всякий случай получить уникальный набор элементов.
Как вы можете видеть, в каждом цикле создаются два объекта как «комбинированный» и «комбинированный_2». Комбинированный, уже объясненный выше. «Combined_2», с другой стороны, представляет собой комбинацию «комбинированной» переменной и каждой строки всего набора данных (каждой транзакции). Как видно из строки 14, существует процесс фильтрации, который контролирует каждый набор элементов, входят ли «объединенные» наборы элементов в набор данных. Если в наборе данных нет такого набора элементов, он удаляет этот набор элементов. В конце концов, мы также получаем частоты с помощью метода «reduceByKey» и фильтруем их в соответствии с минимальным поддерживаемым значением. В строке 21 мы добавляем окончательную таблицу поддержки в «baseRDD», которая содержит все наши значения поддержки с наборами элементов (теоретически она называется таблицей). Однако нам также необходимо обновить переменную «supportRdd» на «комбинированный_2» без значений поддержки. Этот процесс будет продолжаться до тех пор, пока в «supportRdd» не останется ни одного набора элементов.
Наконец, мы можем рассчитать значения достоверности. Вы можете использовать приведенные ниже коды для расчета значений достоверности для каждой комбинации baseRdd (комбинации всего набора элементов). Существует класс «Фильтр», который может фильтровать данные в соответствии с расчетом достоверности. Он также включает метод «calculateConfidence», который вычисляет достоверность.
Если вы запустите baseRddConfidence.collect (), вы можете получить все значения достоверности. Вы также можете отфильтровать результат, который превышает определенную степень уверенности. Несколько примеров из результата показаны ниже;
[ [['Apple'], ['Mango'], 58.333333333333336], [['Mango'], ['Apple'], 70.0], [['Apple'], ['Banana'], 41.66666666666667], [['Apple'], ['Mango', 'Banana'], 33.33333333333333], [['Mango', 'Apple'], ['Banana'], 57.14285714285714], [['Apple', 'Banana'], ['Mango'], 80.0], [['Mango', 'Banana'], ['Apple'], 66.66666666666666], [['Mango', 'Apple'], ['Raspberry'], 28.57142857142857 [['Raspberry', 'Apple'], ['Mango'], 50.0], [['Mango', 'Raspberry'], ['Apple'], 50.0], [['Mango', 'Banana'], ['Raspberry'], 33.33333333333333], [['Mango', 'Raspberry'], ['Banana'], 50.0], [['Raspberry', 'Banana'], ['Mango'], 50.0] ]
Первый набор элементов в массивах показывает продукты, которые купили клиенты, а второй показывает, что клиенты могли бы купить, если бы они купили продукты в первом наборе элементов. Последний элемент массива показывает значение достоверности для этого шаблона. Например, покупатель Mango может купить Apple с уверенностью 58%. Другой пример; покупатель Mango and Banana может купить Apple с уверенностью 66,6%. Если вы внимательно посмотрите на первые два массива [«Манго», «Яблоко»] и [«Яблоко», «Манго»] имеют разные значения достоверности. Напишем формулу поддержки для [«Mango» = ›« Apple »] (уверенность в покупке Apple после Mango)
( support(["Mango" , "Apple"]) / support(["Mango"]) ) * 100 = 70
и формула [«Яблоко» = ›« Манго »]
( support(["Mango" , "Apple"]) / support(["Apple"]) ) * 100 = 58
Поддержка [«Mango», «Apple»] - 7, поддержка [«Mango»] - 10, поддержка [«Apple»] - 12. Хотя частота (поддержка) [«Apple» «Mango»] одинакова в обоих расчетах, у них разные значения достоверности, потому что частота «Яблока» и частота «Манго» различаются.
Вы также можете преобразовать результирующий фрейм данных pandas, используя приведенные ниже коды;
Заключение
В этой статье мы узнали, что такое анализ частых паттернов и как его применять к алгоритму априори. Мы взяли примерный случай с набором данных и применили алгоритм Apriori к PySpark с нуля. Есть также другие методы FPM, которые вы можете проверить, например FPGrowth, Eclat и т. Д. Поняв Априори, вы легко поймете, как работают другие методы. Если у вас есть вопросы, не стесняйтесь их задавать.
Надеюсь, это было полезно…
использованная литература
[1] Частый анализ шаблонов
https://en.wikipedia.org/wiki/Frequent_pattern_discovery
[2] Apache Spark
https://spark.apache.org/
[3] Что такое Spark
https://databricks.com/spark/about
[4] Априорный алгоритм
https://en.wikipedia.org/wiki/Apriori_algorithm