
Ключевые статистические концепции в науке о данных
Сборник некоторых статистических концепций, которые необходимо знать
Если вы работаете с данными, вы часто можете встретить термины, такие как «тесты», «оценки», «значения» и т. Д., Которым предшествуют алфавиты, например 'F' , "P", "R", "T", "Z" и т. Д. Эта статья посвящена объяснению для непрофессионала некоторых из таких статистических терминов / понятий, которые часто встречаются в мире Наука о данных.
Отказ от ответственности: о чем эта статья?
Эта статья не о исчерпывающем объяснении, но кратком и высоком уровне некоторых ключевых статистических показателей. . Каждой из концепций, представленных ниже, посвящено несколько статей. Я дам вам ссылки на несколько таких статей.
Будут рассмотрены следующие темы:
1) H_0 и H_a - проверка гипотезы
2) P-значение
3) Z-счет
4) t-тест
5) F-тест
6) R-квадрат
1) H_0 и H_a - Проверка гипотез
Проще говоря, гипотеза - это идея (или предпосылка, или утверждение), которую вы хотите проверить (или подтвердить). Например, потягивая кофе, вы начинаете думать: «Как соотносится средний (средний) рост людей в штате Нью-Йорк со средним (средним) ростом людей в штате Калифорния?» Это ваша идея.

Теперь, чтобы проверить вашу идею / утверждение, вам понадобятся некоторые данные. Кроме того, вам необходимо сформулировать формулировку проблемы - гипотезу, а для проверки этой гипотезы вам понадобится проверка гипотезы. В частности, вам необходимо создать два сценария - один, который поддерживает ваше утверждение, а другой, альтернативный сценарий.
Нулевая гипотеза - это, по сути, статус-кво (или установка по умолчанию, или общепринятое значение, как прекрасно объясняет это видео). Например, статус-кво может заключаться в том, что средний (средний) рост людей в обоих штатах одинаков. Это сформирует вашу нулевую гипотезу , обозначенную как H_0. В суде у вас есть обвинение и защита. Аналогичным образом, для каждой нулевой гипотезы у вас есть альтернативная (или альтернативная) гипотеза (для проверки вашей идеи / утверждения) , обозначенная как H_a (также известная как исследовательская гипотеза, как вы необходимо провести исследование / выборку, чтобы оспорить H_0).
Сформулировав свою нулевую и альтернативную гипотезы, теперь вам нужны некоторые данные. Конечно, нецелесообразно измерять рост всего населения Нью-Йорка и Калифорнии. Итак, вы должны собрать образцы данных для нескольких человек (скажем, 50, 100 или больше), чтобы проверить свое утверждение. Имея образцы данных, вы можете выполнить некоторые статистические тесты, которые объяснены (с использованием других, но эквивалентных примеров) в следующих разделах.
Дополнительные материалы:
2) P-значение
Этот термин в основном используется для измерения статистической значимости результатов во время проверки гипотез. Здесь P означает «вероятность». Итак, это значение вероятности от 0 до 1. Вы используете его, чтобы отклонить или поддержать нулевую гипотезу.

Вместе со значением P является уровень значимости (обозначается греческой буквой альфа), который обычно составляет 0,05 (или 5%). По сути, это уровень достоверности, вычитаемый из 100%. Более высокий уровень альфа означает более низкий доверительный интервал и наоборот.
Если значение P меньше этого уровня значимости, гипотеза о нуле отклоняется. Если значение P больше уровня значимости , поддержка альтернативной гипотезы не столь сильна и, следовательно, нулевая гипотеза не отклоняется, т. е. альтернативная гипотеза не принимается .
Лично я считаю P -значение более интуитивным, когда значение «значимость» количественно соотносится со «случайностью». Например, P -значение 0,01 (действительно небольшое значение) означает, что существует всего лишь 1% шанс (вероятность) того, что результаты эксперимента, который вы провели, выборка была получена «случайно» или произошла «случайно» из-за некоторой ошибки выборки. Другими словами, вы можете радоваться тому, что полученные вами результаты действительно очень значительны. Проще говоря, чем меньше значение P, тем значительнее ваши результаты и менее вероятно, что они были получены (получены) случайно или случайно. Следуя этой логике, высокое значение P, скажем 0,7, означает, что существует 70% -ная вероятность того, что ваши результаты были получены случайно, что не имеет никакого отношения к тому, как вы выполнили свой эксперимент. Итак, ваши выводы сейчас менее значительны.
Мой уровень значимости (альфа) слишком строг или слишком мягок?
Ответ: это зависит от решаемой проблемы. Представьте, что, отвергая нулевую гипотезу, вы принимаете неправильное решение, то есть, хотя теперь вы выбираете альтернативную гипотезу, ваш выбор отклонения нулевой гипотезы не был удачным. Вы просто отклонили его, потому что ваше P -значение упало ниже альфа-значения. Вы просто следовали правилам (основанным на альфа-значении, которое вы установили перед исследованием). Но не все правила должны быть хорошими.
Теперь, если вы проводите проверку гипотезы для средней скорости, с которой игроки бьют штраф, вы должны быть довольны 95% -ным доверительным интервалом, то есть оставляя широкое окно в 5% (считайте это 5% снисходительным) для отклонения Нулевая гипотеза, или 5% окно для принятия неправильного решения. Хорошо. Просто невероятная скорость. Однако, если вы изучаете что-то важное, например, влияние неинвазивного лечения на опухоль у пациента, вам определенно понадобится высокий доверительный интервал, возможно, 99,9%, оставив уровень значимости 0,1%, то есть 0,001 (считайте, что это всего лишь 0,1% снисходительности; очень, очень строго в отношении анализа опухоли). Теперь у вас есть гораздо меньшее окно, всего 0,1%, для принятия неправильного решения (предположение, что неправильный здесь означает отказ от нулевой гипотезы и принятие альтернативной гипотезы).
Дополнительные статьи о P -значении:
- Все, что вы должны знать о p-value с нуля для науки о данных
- P-значения, объясненные специалистом по данным
- Простое объяснение P-значения для специалистов по данным
- Святой Грааль для P-значений и как они помогают нам в проверке гипотез
- П-значения, и когда их не использовать
- Интуитивное объяснение проверки гипотез и P-значений
- Статистическая значимость объяснена
3) Z-счет

Z -счет (также известный как стандартный балл) показывает, сколько стандартных отклонений осталось (ниже / слева или выше / справа) наблюдение основано на среднем нормальном распределении. Может принимать как положительные, так и отрицательные значения. Отрицательный показатель Z означает, что точка данных находится на Z стандартном отклонении слева от среднего, а положительный показатель Z означает, что точка данных находится Z стандартное отклонение справа от среднего нормального распределения, которому принадлежит точка данных.
Где использовать Z -счет?
Одним из важных приложений является вычисление (вероятности) площади под нормальной кривой, связанной с данной точкой данных. Ничего не понял? Продолжайте читать!

Возьмем пример, адаптированный из этого замечательного видео. Предположим, возраст участников вашего занятия йогой соответствует нормальному распределению (левая кривая на рисунке ниже) со средним значением 50 (лет) и стандартным отклонением 10 (лет). Я знаю, что по мере приближения к пенсии вам нужна йога!
Теперь вас спрашивают, какая доля участников моложе 35 лет (заштрихованная область под кривой). Чтобы ответить на этот вопрос, вам нужно сначала стандартизировать нормальное распределение, т. Е. нормальное распределение со средним значением = 0 и стандартным отклонением = 1, используя формулу ниже. Значения на оси x в стандартизированном распределении обозначены в единицах стандартных отклонений от среднего (0) и представляют собой Z -счет. Значение 35 лет теперь на -1,5 стандартного отклонения от среднего, то есть Z -счет составляет -1,5. По определению, Z -счет безразмерный.

Итак, задача определения доли участников моложе 35 лет превращается в определение доли Z ‹-1,5. Теперь все, что вам нужно сделать, это посмотреть вверх по Z-таблице оценок для значения, соответствующего Z = -1,5. Это значение 0,0668. Это необходимая пропорция (площадь заштрихованной области, где общая площадь под черной кривой равна 1) - 6,68% участников.
Некоторые другие применения Z-score
Аналогичным образом, вы можете использовать Z -score для сравнения двух или более ситуаций, в которых данные имеют разные масштабы. Например, поиск 10% лучших студентов, сдавших два разных экзамена (разные системы баллов), такие как GMAT и SAT.
Другое приложение - обнаружение выбросов в генеральной совокупности / наборе данных. Как? Стандартизируйте распределение населения (если это нормально) и отметьте точки данных, которые лежат ниже Z -счета -3 и выше Z -счета +3 потому что эти точки будут лежать за пределами трехкратного стандартного отклонения от среднего, т. е. вероятности 0,003 (99,7% площади находится в пределах плюс-минус 3 стандартных отклонения).
Дополнительные материалы:
4) t-тест
Это проверка гипотез (также известная как t -тест Стьюдента), которая позволяет определить, есть ли значительная статистическая разница между двумя исследуемыми группами / образцами , точки данных которого, как предполагается, распределены нормально.

Пример:
Предположим, вы хотите сравнить рост людей с двух разных континентов. Вы берете две независимые / непарные выборки, по одной от населения каждого континента, и предполагаете, что они распределены нормально. Хотя вы могли бы просто возразить, что вы можете сравнить среднее значение двух выборок и сказать, что на континенте, имеющем большее среднее значение, есть более высокие люди. Но как насчет дисперсии / разброса в пределах выборки распределения? Возможно, выборки статистически значимо отличаются.
Здесь на помощь приходит значение t. Как прекрасно объясняет это видео, это, по сути, отношение сигнала (разница в средних) и шума (вариация в двух выборках), как показано на рисунке. на рисунке ниже. Чем больше разница между двумя средними значениями, тем выше значение t. Чем выше вариация, тем меньше значение t.
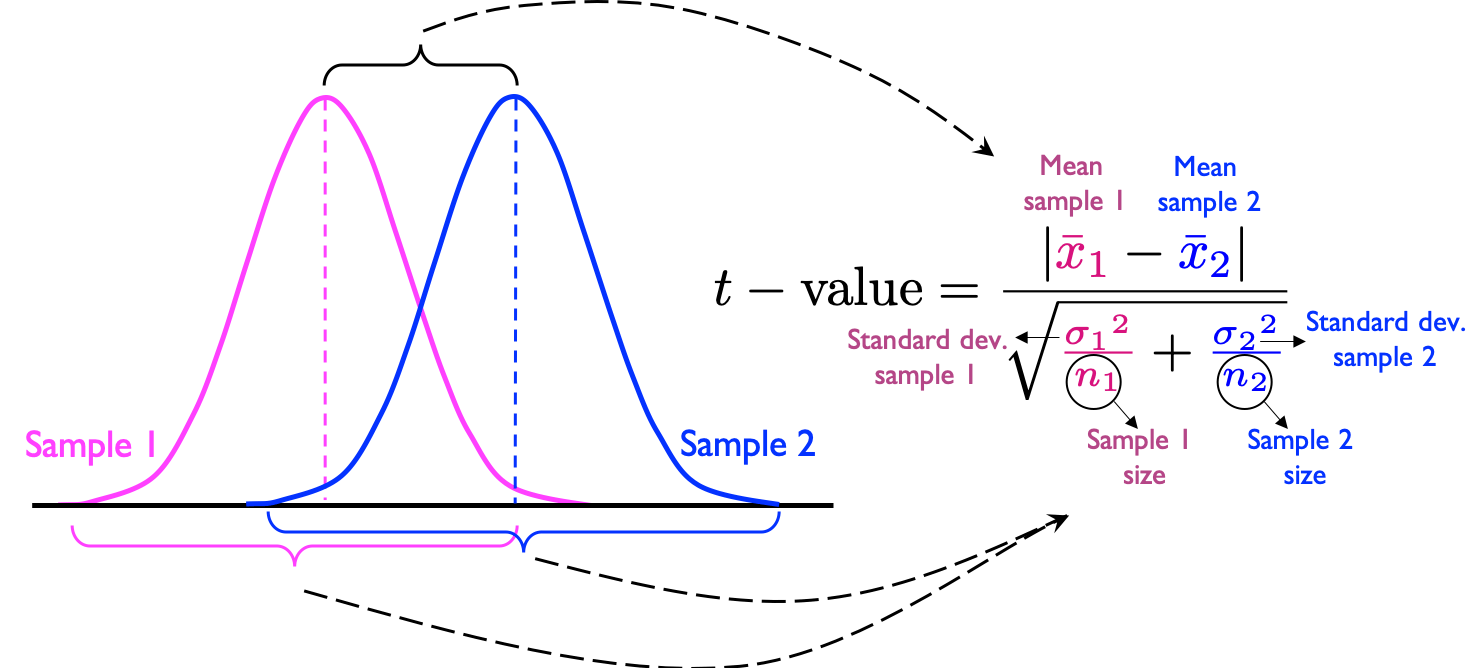
Теперь вы можете использовать это t -значение в t -тесте своей гипотезы, где ваша нулевая гипотеза может сказать, что статистически значимой разницы между двумя выборками нет. Если значение t выше критического значения t (аналогично уровню значимости альфа в контексте значения p ), нулевая гипотеза отклоняется (т. е. две выборки статистически различаются) в пользу альтернативной гипотезы. Если значение t ниже критического значения t, гипотеза о нуле не отклоняется.
Как выбрать критическое значение t?
Критическое значение можно найти с помощью t -таблицы. Чтобы использовать t -таблицу, вам потребуется предварительно определенное p -значение и степени свободы f, которые просто n -2, где n - общее количество точек данных в обеих выборках (общий размер выборки). Используя эти два значения (p и f), вы можете найти критическое значение t.
Дополнительные материалы:
- Т-тест с использованием Python и Numpy
- Статистические тесты - когда использовать какие?
- T-тест статистического анализа для новичков и экспертов
5) F-тест

Почему F? Свое название тест получил в честь Р. А. Фишера, который разработал эту концепцию. F -тест широко используется для сравнения статистических моделей, подогнанных к набору данных, чтобы определить, какая из них лучше объясняет или фиксирует дисперсию независимой / целевой переменной.
Одно из ключевых приложений F -теста - в контексте проблем регрессии. В частности, учитывая регрессионную модель с некоторыми параметрами p_ 1 (называемую ограниченной моделью), она позволяет вам определить, может ли еще более сложная (с большим количеством регрессоров) регрессионная модель ( называется неограниченной моделью) с p_ 2 параметрами (p_ 2 ›p_ 1) - лучший выбор для моделирования ваших данных.
ВНИМАНИЕ! Не путайте p_1 и p_2 с введенным ранее значением p.
Простейшей (наиболее наивной / базовой) моделью с ограничениями может быть простая модель только с перехватом (например, для среднего значения ваших целевых данных), имеющая p _1 = 1. В модели только с перехватом все коэффициенты регрессии равны нулю. Непосредственной следующей конкурентной неограниченной моделью может быть модель, имеющая только одну независимую функцию в дополнение к перехвату, т. Е. p _2 = 2. Аналогичным образом вы можете обобщить p _1 и p _2 на любые значения.
Использование F-теста
Вы можете использовать F -тест в контексте проверки гипотез, сформулировав нулевую гипотезу H _0, которая гласит: «Неограниченная модель существенно не лучше, чем ограниченный ". Соответствующая альтернативная гипотеза, H_a, будет заключаться в том, что неограниченная модель значительно лучше, чем ограниченная.
В приведенной ниже формуле индексы 1 и 2 соответствуют модели с ограничениями и без ограничений, соответственно, с RSS_1 и RSS_2 в качестве соответствующих остаточных сумм квадратов. Очевидно, что числитель показывает, сколько отклонений остается необъяснимой моделью с ограничениями (модель 1) по сравнению с моделью без ограничений (модель 2).

Имея вычисленное значение F -статистики, вам понадобится заранее определенный уровень значимости p (как в t -тест выше; обычно 0,05 означает оценку F -статистики с доверительным интервалом 95%). Теперь, в предположении нулевой гипотезы, F -статистика следует F -распределению, которое имеет две степени свободы в качестве двух характерных параметров. Наконец, чтобы проверить свою гипотезу (утверждение), вы просматриваете F -таблицу распределения, где df_1 будет вашей первой степенью свободы, а df _ 2 второй. Для вашего предварительно определенного значения p, точка пересечения df _1 и df _2 в F -распределительная таблица будет критическим значением. Если ваше вычисленное F -статистическое значение превышает критическое значение, вы отклоняете нулевую гипотезу, и наоборот.
Интуитивно большая разница в числителе в F -статистической формуле означает, что неограниченная модель (модель 2) объясняет большую дисперсию в данных, чем объясняется ограниченной / более простой моделью (модель 1). Следовательно, чем выше F -статистическое значение, тем лучше модель 2 и тем выше шансы отклонить нулевую гипотезу.
Другое ключевое применение F -теста - это дисперсионный анализ (ANOVA) для набора групп выборок, чтобы определить, различаются ли они статистически.
Дополнительная литература:
6) R-квадрат
Внимание: это не квадрат любой переменной с именем R.

Он известен как коэффициент детерминации, часто обозначается как R ² и произносится как «R. -квадрат ». Он показывает, насколько хорошо подходит ваша модель по сравнению с простым базовым предположением среднего значения целевой переменной. Точнее, он измеряет какая доля вариации целевой (ответной / зависимой) переменной определяется (фиксируется, объясняется или прогнозируется) вашей моделью.
Следующее определение R ² проясняет это.


Какие два цветных члена в формуле?
Оба термина являются своего рода отклонениями. Итак, второй член - это, по сути, отношение двух дисперсий.
- Синий член - это остаточная сумма квадратов.
- Пурпурный член - это общая сумма квадратов (по определению пропорциональна дисперсии данных).
Если ваша модель идеально подходит, ваша черная прямая линия на правом рисунке будет проходить через каждую из точек данных, а синий член в формуле будет равен нулю, что приведет к R ² = 1. Если ваша модель f представляет собой просто среднее значение целевой переменной y, т. Е. Базовую модель, у вас будет синий член, равный пурпурному члену, что даст R ² = 0.
Например, значение R ² 0,85 означает, что ваша модель улавливает 85% дисперсии прогнозируемой целевой переменной. Чем выше R ², тем лучше прогноз. Однако лучший прогноз не всегда означает лучшую модель. У вас также может быть переоснащение. Так что будь осторожен!
Разрушитель мифов: статья Взгляд на R -квадрат объясняет, почему низкий R -квадрат не всегда плох, а высокий R -квадрат не всегда хорошо.
Примечание. отрицательный R -квадрат просто означает, что ваша модель даже хуже, чем простая средняя базовая модель. Пора проверить свою модель!
Скорректированный R-квадрат
Если вы продолжите добавлять новые функции в свою модель, значение R ² будет всегда увеличиваться. Таким образом, хотя вы будете получать все более и более высокие баллы, вы можете в конечном итоге переобучить свои данные. Чтобы избежать этой ситуации, иногда используется скорректированный R -квадрат. Он включает штрафной член, который зависит от количества функций (переменных / регрессоров) p и количества точек данных n.

Дополнительные статьи о R -Squared:
- Глядя на R-Squared
- Ода R-квадрат
- Что такое R-квадрат и Скорректированный R-квадрат?
- R-квадрат (R²) и скорректированный R-квадрат
Заключение:
Целью этого поста было дать читателю базовое представление о наиболее распространенных статистических методах, используемых в Data Science. Тесты / концепции, обсуждаемые в этой статье, не ограничиваются какой-либо конкретной областью, а являются общими по своей структуре.
На этом я подошел к концу этого поста. Чтобы быть в курсе моих статей, подписывайтесь на меня здесь. Если вы хотите, чтобы я что-то добавил к этому сообщению, не стесняйтесь комментировать с соответствующими источниками.