
Вспоминая предыдущие два поста, в этом посте будут использоваться алгоритмы машинного обучения для прогнозирования клиентов, которые, скорее всего, купят политику автоприцепа на основе 85 исторических социально-демографических атрибутов данных и данных о владении продуктом. В предыдущем посте мы говорили об использовании нескольких методов выбора функций, таких как пошаговый выбор вперед / назад и регуляризация лассо, чтобы уменьшить количество атрибутов, которые мы должны вписать в наши алгоритмы машинного обучения. Мы обсудим, какой набор атрибутов, определенных различными методами выбора функций, даст нам наилучшие результаты прогнозирования.
Разработка модели логистической регрессии 1
Поскольку целевой атрибут (то есть, покупает ли клиент или нет политику каравана покупок) является биномиальным дискретным, мы можем использовать простейшую логистическую регрессию в качестве нашего первого алгоритма машинного обучения, используя функциюglm из пакета glmnet. Сначала мы подбираем все переменные, чтобы увидеть, как работает модель, используя V86 ~, что означает все атрибуты в качестве переменных-предикторов, кроме V86, который является нашей целевой переменной.

Наблюдения с этой модели:
- На уровне значимости 5% используются V47 (полисы для автомобилей с вкладом), V55 (полисы с пожизненным вкладом), V59 (полисы с пожарами в виде пожертвований), V76 (количество страховок жизни), V82 (количество полисов для катера). существенный
- Остаточное отклонение меньше нулевого отклонения, что означает, что эта модель более полезна по сравнению с моделью без каких-либо переменных-предикторов.
Обратите внимание, что *** обозначает уровень значимости этой переменной-предиктора.
Мы можем использовать тест Chisq, чтобы проверить, насколько хороша модель логистической регрессии по сравнению с нулевой моделью.

Значение p действительно мало, что означает, что эта модель значительно лучше, чем нулевая модель.
Поскольку наша задача - предсказать, купит ли конкретный клиент полисы караванов, мы создаем матрицу путаницы, используя функцию confusionMatrix из библиотеки caret, чтобы показать, сколько прогнозов эта модель сделала правильно и неправильно в нашем наборе обучающих данных.

Эта модель предсказывала, что 9 + 7 = 16 клиентов будут покупать полисы на мобильные дома, а 5465 + 341 = 5806 не будут покупать полисы на мобильные дома. Из этих наблюдений 5465 из (5465 + 9), что составляет примерно 99,84% (чувствительность), были правильно предсказаны моделью, что эти клиенты не будут покупать полисы на мобильные дома, и они действительно не будут покупать их. Принимая во внимание, что только 7 из (7 + 341), что составляет примерно 2,01% (специфичность), были правильно предсказаны моделью, что эти клиенты будут покупать полисы на мобильные дома, и они действительно купили это. Следовательно, эта модель имеет высокую чувствительность, но очень низкую специфичность.
Обратите внимание, что даже несмотря на то, что точность модели высока на уровне 93,99%, это ожидается, поскольку наш набор данных сильно несбалансирован, и только 348 (6%) клиентов купили полисы для мобильных домов. Если бы мы спрогнозировали, что все клиенты не будут покупать полисы для мобильных домов, мы все равно получим общий процент правильных прогнозов 5474/5822, что составляет примерно 94,02% (то есть скорость отсутствия информации). В результате то, к чему мы стремимся с точки зрения ошибки обучения, - это модель с высокой специфичностью, поскольку мы пытаемся определить клиентов, которые будут покупать полисы для мобильных домов.
Мы можем проиллюстрировать чувствительность и специфичность модели, построив кривую рабочих характеристик приемника (ROC) с помощью библиотеки pROC.


Что будет идеальным в кривой ROC для хорошей модели, так это чтобы и чувствительность, и специфичность были близки к левому верхнему краю кривой, что означает, что площадь под кривой равна 1. Однако, как видно на этом графике, линия далеко от верхнего левого края, а площадь под кривой составляет всего 0,509, что также можно получить как сбалансированную точность в предыдущем разделе «Матрица неточностей и статистика».
Поскольку мы знаем, что наши данные сильно несбалансированы, мы можем использовать метод выборки, такой как метод перекрестной проверки K-Fold, чтобы получить более точное значение точности нашей модели. Мы будем использовать 10-кратную перекрестную проверку, которая включает разделение наших обучающих данных на 10 крат, и мы обучаем 10 моделей, каждая из которых использует 9 крат в качестве данных обучения и 10 крат в качестве данных проверки, чтобы получить точность модели. Затем мы получаем среднее значение точности всех 10 моделей.

При 10-кратной перекрестной проверке мы отметили, что точность этой модели составляет 0,9375.
Разработка модели логистической регрессии 2
Мы повторяем вышеизложенное, используя набор атрибутов, определенных как «Прямой пошаговый выбор», «Обратный пошаговый выбор» и «Регуляризация лассо». Исходя из этого, можно показать, что атрибуты, определенные с помощью регуляризации лассо, работают лучше с точки зрения специфичности. Теперь мы можем попытаться подогнать под другую модель, используя 7 важных атрибутов, определенных с помощью логистической регрессии, обученной с помощью атрибутов, определенных регуляризацией Лассо.

Наблюдения с этой модели:
- На уровне значимости 5% используются V18 (более низкий уровень образования), V47 (дополнительные правила в отношении автомобилей), V59 (дополнительные правила пожарной безопасности), V82 (количество правил для лодок), V83 (количество правил для велосипедов). существенный.
- Остаточное отклонение 2376,7, что выше, чем у 2-й модели.
Мы создаем матрицу неточностей, чтобы показать, сколько прогнозов эта модель сделала правильно и неправильно в нашем наборе обучающих данных.

Чувствительность немного увеличилась с 99,8% до 99,9%. Специфичность незначительно снизилась с 1,44% до 0,8621%.
Мы можем запустить функцию anova(), чтобы сравнить эту модель и вторую модель и посмотреть, отличаются ли они статистически.

Тест Anova показывает, что эта модель статистически отличается от второй модели, поскольку значение p низкое (т.е.

Точность с перекрестной проверкой является наивысшей на данный момент и немного выше, чем у второй модели и составляет 0,9385.
Мы можем рассмотреть факторы инфляции дисперсии, чтобы увидеть, есть ли какие-либо переменные, которые мы можем рассмотреть, чтобы удалить, чтобы упростить нашу модель.
Коэффициент инфляции дисперсии - это мера того, насколько дисперсия оцененного коэффициента регрессии «раздута» из-за наличия корреляции между переменными-предикторами в модели.
Значение VIF, равное 1, означает, что нет корреляции между k-м предиктором и оставшимися переменными предиктора, и, следовательно, дисперсия k-го коэффициента вообще не увеличивается. Общее эмпирическое правило состоит в том, что значения VIF, превышающие 4, требуют дальнейшего изучения, а значения VIF, превышающие 10, являются признаками серьезной мультиколлинеарности, требующей исправления.
Мы используем функцию vif из библиотеки car для определения VIF.

Как видно, все 7 переменных, которые были подобраны в 5-ю модель, имеют VIF около 1, что означает отсутствие корреляции между k-м предиктором и остальными предикторными переменными. Следовательно, мы будем придерживаться тех же параметров модели и будем использовать ее как лучшую модель для нашей логистической регрессии.
Разработка модели линейного дискриминантного анализа 1
Второй тип модели, которую мы можем рассмотреть, - это линейный дискриминантный анализ (LDA), который тесно связан с логистической регрессией, в которой обе модели создают границы линейных решений, которые отделяют один класс от другого. Единственное отличие состоит в том, что LDA будет предполагать, что наблюдения взяты из распределения Гаусса с общей ковариационной матрицей в каждом классе, и если это предположение верно, оно будет работать лучше, чем регрессия Logisitc.
Сначала мы подбираем модель LDA с полным набором переменных, используя функцию lda из библиотеки MASS, и показываем матрицу неточностей, чтобы выяснить специфичность и чувствительность.
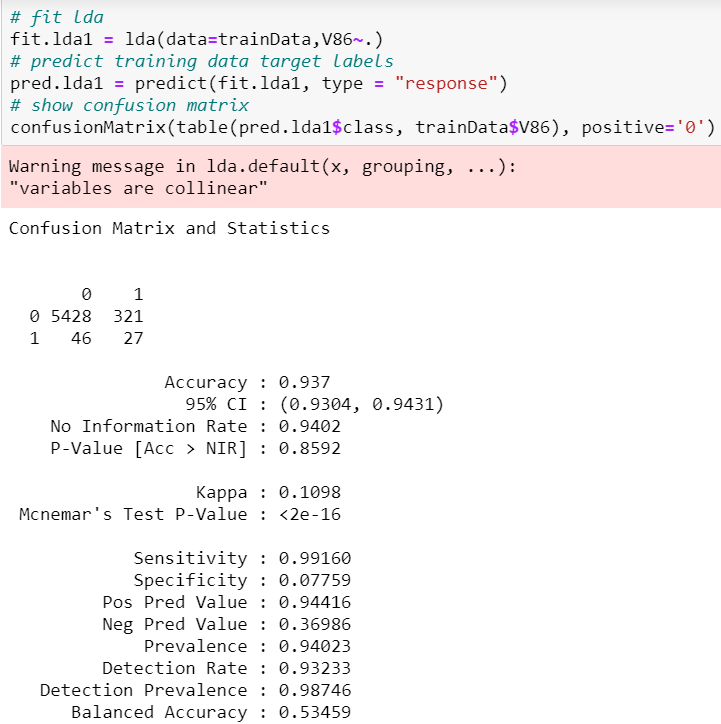
Мы видим, что чувствительность составляет 99,2%, а специфичность 7,8%. При сравнении этой полной модели LDA с полной моделью логистической регрессии, хотя чувствительность модели LDA ниже, ее специфичность выше 2,01% в полной модели логистической регрессии. Если две или более переменных представляют собой почти линейную комбинацию друг с другом, их оценочные коэффициенты будут близки к 0, что затрудняет полную интерпретацию их влияния на целевую переменную. Стоит отметить, что при подборе LDA следует избегать переменных, которые сильно коррелируют друг с другом.
Также обратите внимание, что при подгонке модели LDA к полному набору данных появляется предупреждающее сообщение «переменные коллинеарны», что означает, что некоторые из наших переменных-предикторов коррелированы друг с другом, что уже было исследовано в разделе EDA.
Давайте воспользуемся 10-кратным методом перекрестной проверки, чтобы получить точность этой модели.

Точность этой модели составляет 93,25%. Если бы мы сравнили эту модель с моделями, подходящими для логистической регрессии, эта модель в настоящее время является лучшей с точки зрения специфичности, поскольку она способна правильно предсказать 7,76% клиентов, которые действительно купили полисы для мобильных домов, что является основной целью для нашей задачи прогнозирования, хотя точность этой модели ниже, чем у всех моделей логистической регрессии.
Разработка модели линейного дискриминантного анализа 2
Затем мы пытаемся подогнать 7 переменных, которые были определены при разработке модели логистической регрессии, которые показали наилучшие результаты с точки зрения сложности модели и специфичности тестирования.
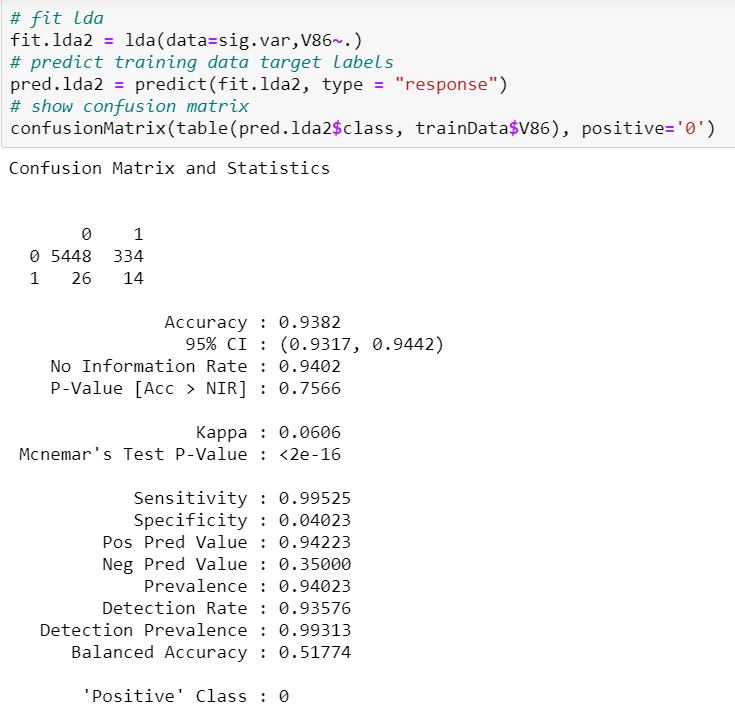
Чувствительность 99,5%, специфичность 4,02%. ROC (сбалансированная точность) составляет 0,518. Эта модель работает хуже с точки зрения специфичности и лучше с точки зрения чувствительности, чем полная модель LDA.
Обратите внимание, что мы не получили предупреждающее сообщение о том, что «переменные коллинеарны» в этой модели, поскольку 7 переменных, подогнанных между ними, имеют незначительную корреляцию между ними, которая была исследована в Variable Inflation Factor (VIF).
Давайте выполним 10-кратную перекрестную проверку, чтобы получить среднюю точность этой модели.

Точность этой модели составляет 0,9376, что выше, чем у предыдущей модели на уровне 0,9325, но все же ниже, чем у всех моделей логистической регрессии.
Разработка модели квадратичного дискриминантного анализа 1
Третий тип модели, который мы можем рассмотреть, - это квадратичный дискриминантный анализ (QDA). В линейном дискриминантном анализе мы предполагаем, что наблюдения получены из распределения Гаусса с общей ковариационной матрицей в каждом классе. Однако в QDA это предположение не выполняется, поскольку каждому классу разрешается иметь разную матрицу ковариаций.
При разработке моделей как логистической регрессии, так и линейного дискриминантного анализа мы обнаружили, что лучшей моделью, соответственно, является модель, использующая 7 переменных, которые были признаны значимыми в результате регрессии Лассо, прямого пошагового выбора и обратного пошагового выбора. Следовательно, мы сначала обучаем нашу модель QDA, используя этот набор из 7 переменных.
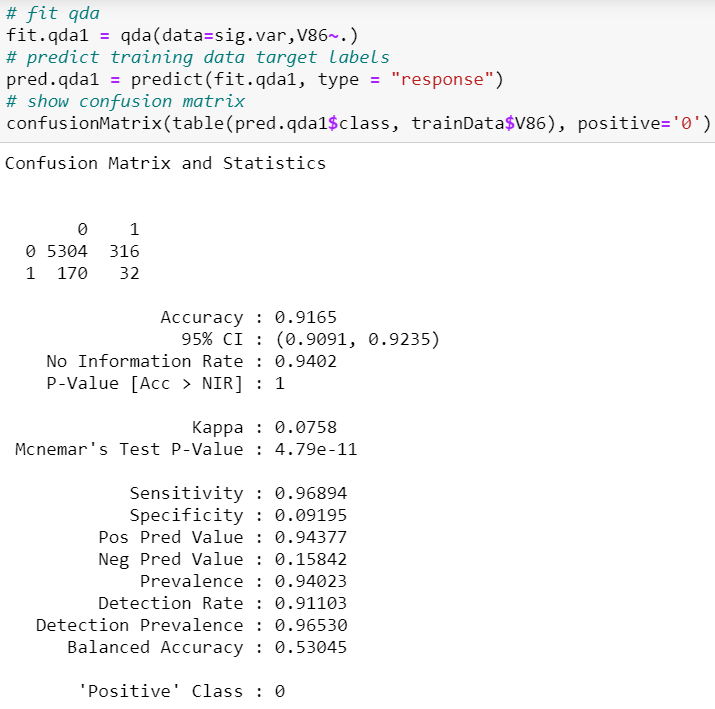
Чувствительность составляет 96,89%, что на данный момент является самым низким показателем среди всех обученных моделей. Специфичность составляет 9,20%, что на данный момент является самым высоким показателем среди всех моделей.
Давайте получим среднюю точность этой модели из 10-кратной перекрестной проверки.

Точность модели составляет 0,9189, что является самым низким показателем среди всех обученных моделей.
Поскольку точность QDA оказывается ниже, чем у модели логистической регрессии и линейного дискриминантного анализа, мы не будем тренировать больше моделей с помощью QDA.
Выбранная модель
Сравнивая эти 3 модели, лучшая модель, которую мы выберем для нашей задачи прогнозирования, будет вторая модель линейного дискриминантного анализа, содержащая набор переменных-предикторов (V18, V41, V47, V58, V59, V82, V83), которые были идентифицированы. столь же значимо, как и в первых 4 моделях логистической регрессии. Во-первых, даже несмотря на то, что точность CV ниже по сравнению с другими моделями логистической регрессии, ее специфичность самая высокая. Поскольку задача состоит в том, чтобы найти подмножество клиентов, которые, вероятно, купят полисы для автоприцепов, чтобы остальные, кто этого не сделал, получили рассылку, наша цель будет заключаться в максимальном выявлении этой группы клиентов, которые, вероятно, купят дом на колесах. полисы, чтобы страховая компания могла сэкономить на почтовых отправлениях небольшой группе клиентов, которые, по определению, вряд ли купят полисы на мобильный дом, что означает, что мы будем уделять больше внимания специфике модели. Хотя специфика модели QDA самая высокая, точность CV для модели QDA очень низкая. В результате мы выбрали вторую модель в LDA как лучшую модель для нашей задачи прогнозирования, поскольку нам нужно что-то среднее по точности и специфичности.
Прогнозирование с использованием набора данных тестирования
Нам также предоставляется набор данных тестирования, и мы можем использовать его, чтобы увидеть, насколько хорошо будет работать модель LDA, которую мы определили как лучшую. Предполагается, что в этом наборе данных тестирования мы найдем 800 клиентов, которые с наибольшей вероятностью купят полисы для мобильных домов на основе вероятностей, предсказанных нашей моделью. После идентификации этой группы из 800 клиентов мы затем используем истинные целевые значения данных тестирования и смотрим, сколько из них идентифицировано правильно и неправильно. Обратите внимание, что в реальных жизненных задачах все, что у нас может быть, - это набор данных, которые мы должны использовать таким методом, как разделение 70:30, чтобы получить данные для обучения и тестирования, чтобы протестировать наши алгоритмы машинного обучения.

Точность нашей модели с использованием набора данных тестирования составляет 79,7%, чувствительность - 81,74%, а специфичность - 47,48%. Наша модель правильно определила 113 из 238 фактических клиентов, пользующихся полисом для мобильных домов.
Резюме
Победитель этой задачи придумал алгоритм, который смог правильно идентифицировать 121 клиента, и наш алгоритм, который успешно идентифицировал 113, был не так уж и плох. Стандартные тесты производительности дают 94 результата с использованием K-ближайших соседей, 102 с использованием наивного байеса и 105 с использованием нейронных сетей, которые все были более сложными, чем наша модель LDA. Надеюсь, вам понравится это пошаговое руководство по построению модели машинного обучения, и вы теперь лучше понимаете, как подойти к проблеме с помощью исследовательского анализа данных, выбора функций и машинного обучения!