НАУКА ДАННЫХ
Как извлекать таблицы из PDF-файлов с помощью Camelot
Краткое руководство по извлечению таблиц из файлов PDF в Python с использованием библиотеки Camelot

Установка
Если вы работаете в Windows, обязательно установите Ghostscrip отсюда. Вы по-прежнему можете установить camelot без предварительной установки Ghostscript. Но мы столкнемся с ошибками при попытке использовать camelot.
conda install -c conda-forge camelot-py
or
pip install "camelot-py[cv]"
or
git clone https://www.github.com/camelot-dev/camelot cd camelot pip install ".[cv]"
использование
Сначала мы импортируем camelot , а затем укажем путь к файлу PDF. read_pdf имеет множество параметров, которые мы можем изучить. Образец pdf, использованный для примера ниже, находится здесь.
import camelot
tables = camelot.read_pdf('https://trade.indiabulls.com/pdf/NSE_Holidays_Equity.pdf')
Количество таблиц: выводит количество извлеченных таблиц. В статье выше 2 таблицы.
tables.n >>> 2
Отчет о синтаксическом анализе: запустите ниже, чтобы получить отчет о синтаксическом анализе для каждой извлеченной таблицы. Если мы заинтересованы в просмотре этого отчета для каждой таблицы, мы должны пройти через все таблицы.
print(tables[0].parsing_report)
>>> {'accuracy': 100.0, 'whitespace': 0.0, 'order': 1, 'page': 1}
for i in range(tables.n):
print(tables[i].parsing_report)
>>> {'accuracy': 100.0, 'whitespace': 0.0, 'order': 1, 'page': 1}
>>> {'accuracy': 100.0, 'whitespace': 0.0, 'order': 2, 'page': 1}
Форма таблицы. Приведенный ниже код дает форму всех извлеченных таблиц. Здесь форма означает количество строк и количество столбцов.
print(tables[0])
>>> <Table shape=(13, 4)>
for i in range(tables.n):
print(tables[i])
>>> <Table shape=(13, 4)>
>>> <Table shape=(8, 4)>
Экспорт таблиц: мы можем экспортировать все таблицы в форматы CSV, Excel, JSON, HTML и SQLite. См. Пример ниже для экспорта таблиц в формат CSV.
Точно так же мы можем использовать to_excel, to_json, to_html и to_sqlite.
tables[0].to_csv(‘nse_holiday_list_table1.csv’) tables[1].to_csv(‘nse_holiday_list_table2.csv’)
Преобразовать в фрейм данных pandas: мы можем экспортировать все таблицы в фрейм данных Pandas. Код tables[0].df преобразует таблицу в DataFrame, но, как видно из приведенного ниже снимка экрана, заголовок отображается неправильно. Нам нужно исправить это, чтобы таблицы отображались с правильными заголовками DataFrame.
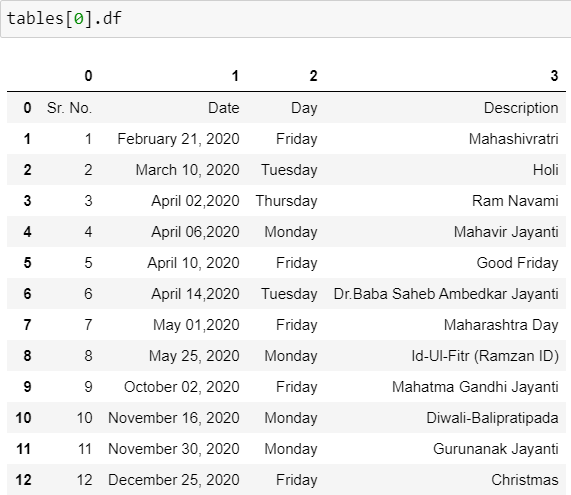
После внесения следующих изменений теперь он выглядит идеально с правильным заголовком DataFrame.
temp_df = tables[0].df temp_df.rename(columns=temp_df.iloc[0]).drop(temp_df.index[0])

Вы можете найти полный код ниже -
Интерфейс командной строки
Camelot также предоставляет интерфейс командной строки. Для команд интерфейса командной строки можно перейти по ссылке эта.
веб интерфейс
У этой замечательной библиотеки есть также веб-интерфейс, который называется Excalibur.
Услышав названия
Camelot&Excalibur, я теперь понимаю, почему это называется «Извлечение таблиц PDF для людей» :) Надеюсь, вы тоже можете догадаться! !
Для расширенного использования Camelot обратитесь к this.
Преимущества Камелота
- Camelot обеспечивает большую гибкость при извлечении таблиц по количеству параметров.
- Таблицы, которые не извлечены правильно, могут быть отброшены на основании таких показателей, как точность и пробелы. Это мы можем получить из метода анализа отчета.
- Каждую таблицу можно преобразовать в фрейм данных pandas, который можно использовать для дальнейшего анализа или обработки.
- Camelot дает возможность экспортировать таблицы в различные форматы, такие как CSV, Excel, JSON, HTML и Sqlite.
Примечание. Camelot работает только с текстовыми PDF-документами, но не с отсканированными документами.
Заключение
Мы поняли, что camelot библиотека извлекает таблицы из файлов PDF, которые вы можете использовать в своем следующем проекте.
Чтобы читать больше таких интересных статей о Python и Data Science, подпишитесь на мой блог www.pythonsimplified.com. Вы также можете связаться со мной в LinkedIn.