
Временные ряды просто представляют точки данных с течением времени. Таким образом, они повсюду в природе и в бизнесе: температура, сердцебиение, рождаемость, динамика населения, интернет-трафик, запасы, запасы, продажи, заказы, заводское производство - что угодно. В бесчисленных случаях эффективная обработка и прогнозирование временных рядов может дать решающие преимущества. Это может помочь предприятиям заранее адаптировать свои стратегии (например, если производство можно планировать заранее) или улучшить свои операции (например, путем обнаружения аномалий в сложных системах). Хотя существует множество моделей и инструментов для временных рядов, работать с ними по-прежнему часто нетривиально, поскольку каждый из них имеет свои сложности и не всегда может использоваться одинаково. В Unit8 мы часто работаем с временными рядами и поэтому начали разрабатывать собственный инструмент, чтобы упростить себе жизнь. Мы также решили внести свой вклад в сообщество, открыв его исходный код. В этой статье мы представляем дартс, нашу попытку упростить обработку временных рядов и прогнозирование в Python.
Мотивация
Если вы специалист по данным, работающий с временными рядами, вы уже знаете это: временные ряды - особые звери. С обычными табличными данными вы часто можете просто использовать scikit-learn для выполнения большинства задач машинного обучения - от предварительной обработки до прогнозирования и выбора модели. Но с временными рядами дело обстоит иначе. Вы можете легко оказаться в ситуациях, когда вам понадобится одна библиотека для предварительной обработки (например, Pandas для интерполяции отсутствующих значений и повторной выборки), другая для определения сезонности (например, statsmodels), третья для соответствия модели прогнозирования. (например, Facebook Prophet), и, наконец, чаще всего вам придется реализовать свои собственные процедуры тестирования и выбора модели. Это может быть довольно утомительно, поскольку большинство библиотек используют разные API и типы данных. И это даже не говоря о случаях, связанных с более сложными моделями, основанными на нейронных сетях, или проблемами, связанными с внешними данными и другими измерениями. В таких случаях вам, вероятно, придется самостоятельно реализовать модели для вашего варианта использования, например, с использованием таких библиотек, как Tensorflow или PyTorch. В целом, мы считаем, что опыт машинного обучения временных рядов в Python пока не совсем гладкий.
Мы большие поклонники подхода scikit-learn: единой библиотеки с открытым исходным кодом и согласованного API, которая содержит отличный набор инструментов для сквозного машинного обучения. Дартс пытается научиться изучать временные ряды, и его основная цель - упростить весь процесс машинного обучения временных рядов.

Покажите мне!
darts имеет открытый исходный код и доступен здесь. Вы можете установить его в своей любимой среде Python следующим образом:
pip install darts
Базовым типом данных в Darts является TimeSeries, который представляет многомерный (и, возможно, вероятностный) временной ряд. Его очень легко построить, например, из Pandas DataFrame. По сравнению с DataFrame, TimeSeries поставляется с некоторыми дополнительными гарантиями, гарантирующими, что он представляет правильно сформированный временной ряд с надлежащим временным индексом. За кулисами он также может опционально хранить несколько выборок, что является удобным способом представления вероятностных результатов определенных моделей. Вот как его собрать из панд DataFrame:
import pandas as pd
from darts import TimeSeries
df = pd.read_csv('AirPassengers.csv')
series = TimeSeries.from_dataframe(df, 'Month', '#Passengers')
В приведенном выше фрагменте мы сначала читаем DataFrame, содержащий набор данных авиапассажиров. Затем мы строим (одномерный) TimeSeries, указывая столбцы времени и значения (Month и #Passengers соответственно).
Давайте теперь разделим нашу серию на обучение и проверку TimeSeries и обучим модель экспоненциального сглаживания на обучающей серии:
from darts.models import ExponentialSmoothing
train, val = series.split_before(pd.Timestamp('19580101'))
model = ExponentialSmoothing()
model.fit(train)
prediction = model.predict(len(val), num_samples=500)
Вот и все, теперь у нас есть прогноз по нашей серии проверок. Мы можем построить его вместе с реальной серией:
import matplotlib.pyplot as plt series.plot(label='actual') prediction.plot(label='forecast', lw=3) plt.legend()

Это все, что нужно. Обратите внимание, что график содержит доверительные интервалы. По умолчанию, если TimeSeries является вероятностным, Дартс покажет его 5-й и 95-й процентили (здесь серия вероятностная, потому что мы вызвали predict() с num_samples=500).
Еще несколько подробностей
Как вы уже догадались, мы имитируем модели scikit-learn fit() и predict() для обучения моделей и составления прогнозов. Функция fit() принимает в качестве аргумента обучение TimeSeries, а функция predict() возвращает новый TimeSeries, представляющий прогноз. Это означает, что модели манипулируют TimeSeries, и это практически единственный тип данных, которым манипулируют в Darts. Это позволяет пользователям легко менять и сравнивать модели. Например, мы могли бы так же легко использовать модель auto-ARIMA (которая негласно обтекает pmdarima):
from darts.models import AutoARIMA model_aarima = AutoARIMA() model_aarima.fit(train) prediction_aarima = model_aarima.predict(len(val))
По сути, дартс основан на следующих простых принципах:
- Существует единый интерфейс
fit()иpredict()для всех моделей прогнозирования, от ARIMA до глубоких нейронных сетей. - Модели потребляют и производят
TimeSeries, что означает, например, что одна модель легко потребляет продукцию другой модели. TimeSeriesможет быть одномерным (одномерным) или многомерным (многомерным). Некоторые модели, такие как модели, основанные на нейронных сетях, работают с многомерными рядами, в то время как другие ограничиваются одномерными рядами.TimeSeriesможет быть детерминированным (содержащим 1 образец) или вероятностным (содержащим несколько образцов). Некоторые модели прогнозирования могут создавать вероятностные ряды (иногда даже позволяя настроить тип распределения, соответствующий данным), а другие - нет.- Неизменяемость: класс
TimeSeriesразработан так, чтобы быть неизменным.
Дартс уже содержит рабочие реализации следующих моделей прогнозирования:
- "Экспоненциальное сглаживание",
- (V) ARIMA & auto-ARIMA (включая сезонные),
- Фейсбук Пророк,
- Тета-метод,
- БПФ (быстрое преобразование Фурье),
- Рекуррентные нейронные сети (варианты ванильных RNN, GRU и LSTM),
- Временные сверточные сети (TCN),
- N-BEATS,
- Трансформер, г.
- DeepAR, г.
- DeepTCN,
- Модели прогнозирования регрессии: эти модели позволяют прогнозировать будущие значения на основе определенных запаздывающих значений целевого и ковариатного рядов, используя другую модель регрессии (например, модель регрессии scikit-learn).
- и несколько наивных базовых линий.
Дартс твердо поддерживает модели глубокого обучения. Эти модели предоставляют более широкие функциональные возможности, такие как возможность обучения нескольким сериям и ковариатам. Это можно просто сделать, вызвав fit() с последовательностями TimeSeries вместо уникального TimeSeries. Он может масштабироваться до больших наборов данных и использовать графические процессоры.
Кроме того, библиотека также содержит функции для тестирования моделей прогнозирования и регрессии на исторических данных, выполнения поиска по сетке по гиперпараметрам, предварительной обработки TimeSeries, оценки остатков и даже выполнения автоматического выбора модели. Наконец, он также содержит некоторые модели фильтрации (такие как фильтр Калмана и гауссовские процессы), которые позволяют выполнять вероятностную фильтрацию и логический вывод по временным рядам.
Другой пример - бэктестинг
В нашем примере выше мы использовали Дартс для получения прогноза на следующие 36 месяцев, начиная с января 1958 года. Однако прогнозы часто необходимо обновлять, как только становятся доступными новые данные. С Darts легко рассчитывать прогнозы, полученные в результате такого процесса, с помощью бэктестинга. Например, использование бэктестинга для сравнения двух моделей выглядит следующим образом:
from darts.models import Prophet
models = [ExponentialSmoothing(), Prophet()]
backtests = [model.historical_forecasts(series,
start=.5,
forecast_horizon=3)
for model in models]
Функция historical_forecasts() доступна на всех моделях. Требуется временной ряд, начальная точка (здесь мы начинаем с половины ряда) и горизонт прогноза. Он возвращает TimeSeries, содержащий исторические прогнозы, были бы получены при использовании модели для прогнозирования ряда с указанным горизонтом прогноза (здесь 3 месяца), начиная с указанной временной метки (с использованием стратегии расширяющегося окна). .
Тип возвращаемого значения - TimeSeries, поэтому мы можем быстро вычислить показатели ошибок - например, здесь средняя абсолютная ошибка в процентах:
from darts.metrics import mape
series.plot(label='data')
for i, m in enumerate(models):
err = mape(backtests[i], series)
backtests[i].plot(lw=3, label='{}, MAPE={:.2f}%'.format(m, err))
plt.title('Backtests with 3-months forecast horizon')
plt.legend()
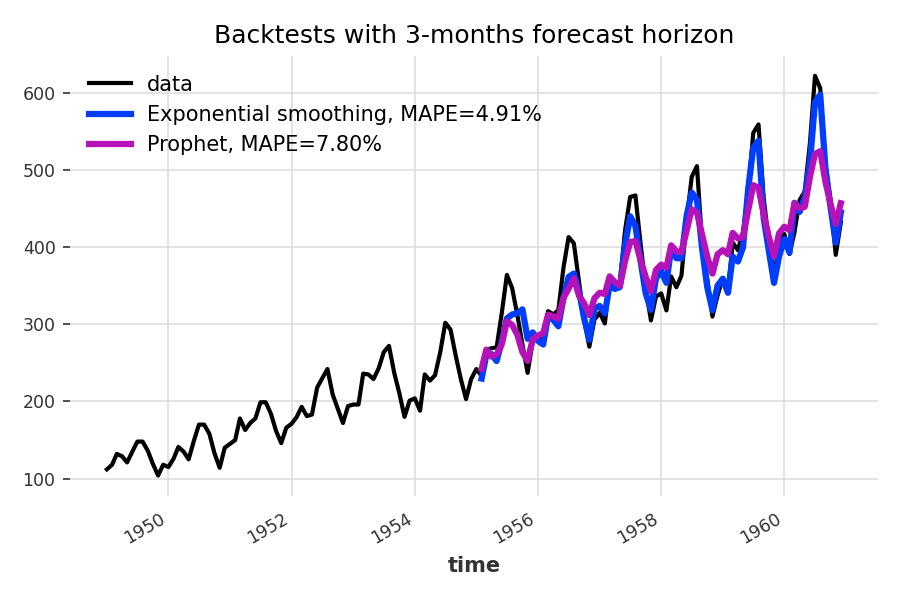
Кроме того, поскольку тип возвращаемого значения historical_forecasts() - это TimeSeries, мы также можем просто использовать серии выходных характеристик в регрессионных моделях, которые могут служить для объединения (суммирования) прогнозов, сделанных несколькими моделями, и, возможно, также включать данные внешних временных рядов. Все модели также имеют функцию backtest(), которая работает аналогично, но вместо этого напрямую возвращает распределения ошибок (для желаемой функции ошибок).
Есть еще много чего, чего мы здесь не затронули. Мы предлагаем серию примеров записных книжек, охватывающих больше материала. Например, вы можете посмотреть вводную тетрадь или узнать, как легко обучить нейронные сети RNN или TCN, используя паттерны fit() и predict(). Кроме того, мы также рекомендуем ознакомиться с Документацией по дартсу и посмотреть наше вступительное видео:
Обучающие модели на множественных временных рядах
Некоторые модели Дартса можно обучать на нескольких временных рядах, при желании также используя ковариантные временные ряды. Подробнее об этих функциях мы рассказали в отдельной статье.
Что дальше?
Мы активно развиваем дартс и добавляем новые функции. Например, вот несколько моментов в нашей дорожной карте:
- Функции обнаружения выбросов
- Возможности встраивания временных рядов и кластеризации
Мы приветствуем публикации и выпуски на github. Это также лучшее место для получения последней информации о библиотеке.
Наконец, дартс - это один из инструментов, который мы используем внутри компании в повседневной работе с ИИ / машинным обучением для нескольких компаний. Если вы считаете, что ваша компания может извлечь выгоду из решений временных рядов или у нее есть другие проблемы, связанные с данными, не стесняйтесь обращаться к нам.