
Случайная регрессия леса - это алгоритм обучения с учителем, который использует метод ансамблевого обучения для регрессии. Метод ансамблевого обучения - это метод, который объединяет прогнозы из нескольких алгоритмов машинного обучения для получения более точного прогноза, чем одна модель.
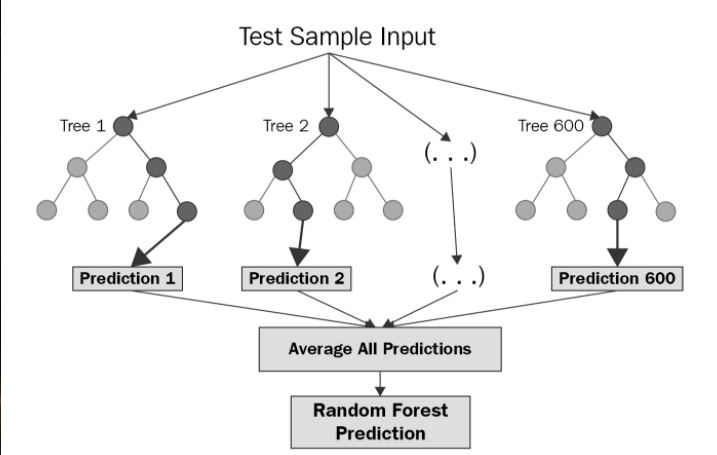
На диаграмме выше показана структура случайного леса. Вы можете заметить, что деревья работают параллельно без взаимодействия между ними. Случайный лес работает путем построения нескольких деревьев решений во время обучения и вывода среднего значения классов в качестве прогноза для всех деревьев. Чтобы лучше понять алгоритм случайного леса, давайте рассмотрим следующие шаги:
- Выберите случайным образом k точек данных из обучающей выборки.
- Постройте дерево решений, связанное с этими k точками данных.
- Выберите количество N деревьев, которое вы хотите построить, и повторите шаги 1 и 2.
- Для новой точки данных сделайте так, чтобы каждое из ваших N -деревьев предсказывало значение y для рассматриваемой точки данных и назначило новую точку данных среднему значению по все прогнозируемые значения y.
Модель регрессии случайного леса мощна и точна. Обычно он отлично справляется со многими проблемами, включая функции с нелинейными отношениями. К недостаткам, однако, можно отнести следующее: нет интерпретируемости, легко может произойти переоснащение, мы должны выбрать количество деревьев для включения в модель.
Давайте посмотрим на регрессию случайного леса в действии!
Теперь, когда у нас есть базовое представление о том, как работает модель регрессии случайного леса, мы можем оценить ее производительность на реальном наборе данных. Как и в моих предыдущих сообщениях, я буду использовать данные о продажах домов в округе Кинг, США.
После импорта библиотек, импорта набора данных, обработки нулевых значений и удаления всех необходимых столбцов мы готовы создать нашу модель регрессии случайного леса!
Шаг 1. Определите свои зависимые (y) и независимые переменные ( X)
Нашей зависимой переменной будет цены, а нашими независимыми переменными будут оставшиеся столбцы в наборе данных.

Шаг 2. Разделите набор данных на обучающий набор и тестовый набор

Важность разделения обучения и тестирования заключается в том, что обучающий набор содержит известные выходные данные, на основе которых модель учится. Затем тестовый набор проверяет предсказания модели на основе того, что она узнала из обучающего набора.
Шаг 3. Обучение модели регрессии случайного леса для всего набора данных

Из пакета sklearn, содержащего ансамблевое обучение, мы импортируем класс RandomForestRegressor, создаем его экземпляр и назначаем его переменной. Параметр n_estimators создает n количество деревьев в вашем случайном лесу, где n - это число, которое вы передаете. Мы передали 10. Расширение. Функция fit () позволяет нам обучать модель, регулируя веса в соответствии со значениями данных для достижения большей точности. После обучения наша модель готова делать прогнозы, которые вызываются методом .predict ().
Шаг 4. Прогнозирование результатов набора тестов

Теперь, когда мы успешно создали модель регрессии случайного леса, мы должны оценить ее производительность.

Оценка R² показывает, насколько хорошо наша модель соответствует данным, сравнивая ее со средней линией зависимой переменной. Если оценка ближе к 1, то это означает, что наша модель работает хорошо, а если оценка дальше от 1, то это означает, что наша модель работает не так хорошо.
Мы достигли показателя точности около 81%. Давайте сравним это с оценками, которые мы получили с помощью предыдущих регрессионных моделей:
- Простая линейная регрессия: 50%
- Множественная линейная регрессия: 65%
- Регрессия дерева решений: 65%
- Поддержка векторной регрессии: 71%
- Регрессия случайного леса: 81%
Мы видим, что наша модель регрессии случайного леса сделала наиболее точные прогнозы на данный момент с улучшением на 10% по сравнению с последней моделью!
Заключение
В этом руководстве мы рассмотрели основы моделей регрессии случайного леса. Мы узнали следующее:
- Ансамблевое обучение.
- Порядок действий при построении модели регрессии случайного леса.
- Плюсы / минусы случайной регрессии леса.
- Оценка R2 оценивает точность нашей модели.
- Модель случайной регрессии леса показала лучший результат из всех 6 моделей регрессии.
Спасибо за чтение. Будем очень благодарны за ваш отзыв!