Более точные данные превосходят более сложные алгоритмы

Очистка данных или очистка данных - это процесс обнаружения и исправления (или удаления) поврежденных или неточных записей из набора записей, таблицы или базы данных и ссылки для выявления неполных, неправильных, неточных или несущественных частей данных с последующей заменой, изменением или удалением грязных или грубых данных. [Википедия]
Зачем нужна очистка / очистка данных?
Если вы поговорили с Data Scientist или Data Analyst, у которых был большой опыт построения моделей машин, он скажет вам, что подготовка данных занимает очень много времени и очень важно.
Модели машинного обучения, предназначенные для получения огромного количества данных и поиска закономерностей в этих данных, чтобы иметь возможность принимать разумные решения.
Предположим, вы создаете модель машинного обучения для разделения изображений яблок и апельсинов. Если вы введете все свои данные только с оранжевыми изображениями, то модель не сможет предсказать яблоко, потому что у нее недостаточно данных для изучения и определения шаблонов для яблок.
Этот пример до нас «Мусор в мусоре вне»
Если данные, введенные в модель машинного обучения, низкого качества, модель будет низкого качества.
Проблемы с данными
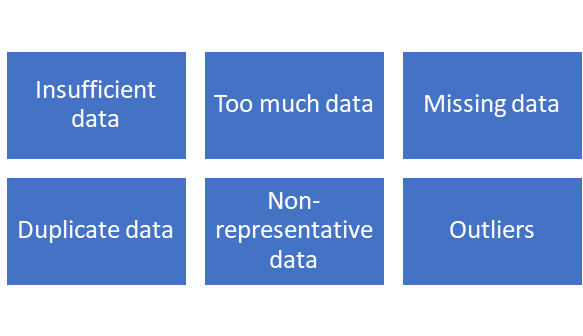
Как решить каждую из вышеперечисленных проблем?

Недостаточные данные
[Шерлок Холмс:] Я пришел к совершенно ошибочному выводу, мой дорогой Ватсон, как всегда опасно рассуждать из-за недостатка данных.
-Приключение пятнистой ленты
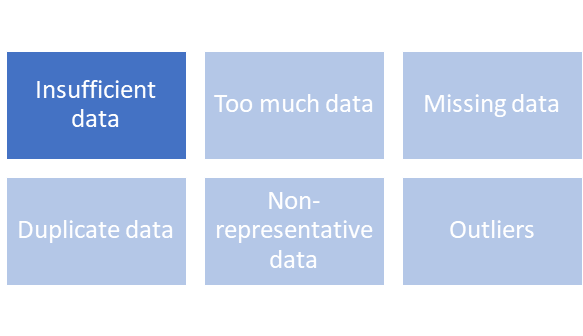
Модели, обученные с недостаточным количеством данных, плохо справляются с прогнозированием. если у вас есть всего несколько записей для вашей модели машинного обучения, это приведет вас к одной из двух нижеизложенных проблем, связанных с моделированием машинного обучения.
Переоснащение: слишком много чтения, чтобы получить слишком мало данных.
Недостаточное соответствие. Постройте чрезмерно упрощенную модель на основе имеющихся данных.
В реальной жизни проблема недостаточности данных - это обычная проблема для проекта, вы можете обнаружить, что соответствующие данные могут быть недоступны, и даже если это фактическая обработка сбора данных, это очень сложно и требует много времени.
По правде говоря, нет отличного решения для работы с недостаточными данными, вам просто нужно найти больше источников данных и долго ждать, пока у вас будут собраны соответствующие данные.
Но есть кое-что, что вы можете сделать, чтобы обойти эту проблему, но учтите, что обсуждаемые методы не широко применимы для всех случаев использования.
Теперь что мы можем сделать, если у нас есть небольшие наборы данных?
Сложность модели. Если у вас небольшой объем данных, вы можете выбрать более простую модель, более простая модель лучше работает с меньшим количеством данных.
Трансферное обучение:, если вы работаете с методами глубокого обучения нейронных сетей, вы можете использовать трансферное обучение.
Увеличение данных. Вы можете попытаться увеличить объем данных, используя методы увеличения данных, которые обычно используются с данными изображений.
Синтетические данные: понимайте, какие данные вам нужны для построения вашей модели, и используйте статистические свойства этих данных для создания синтетических искусственных данных.
Сложность модели
У каждого алгоритма машинного обучения есть свой набор параметров. например, простая линейная регрессия против регрессии дерева решений.
Если у вас меньше данных, выберите более простую модель с меньшим количеством параметров модели. Более простая модель менее восприимчива к переоснащению ваших данных и запоминанию закономерностей в ваших данных.
Некоторые модели машинного обучения просты с несколькими параметрами, например, наивный байесовский классификатор или модель логистической регрессии. Деревья решений имеют гораздо больше параметров и рассматриваются как сложная модель.
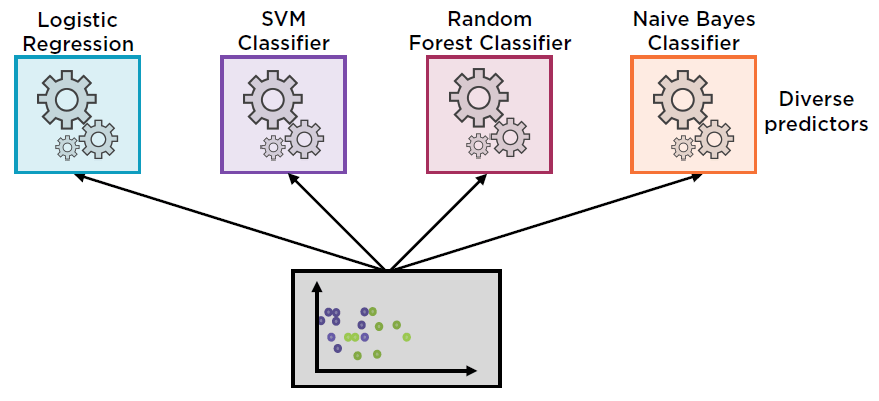
Еще один вариант обучения ваших данных с использованием ансамблевых методов.
Ансамблевое обучение: метод машинного обучения, при котором несколько учащихся объединяются для достижения более высоких результатов, чем любой из учащихся в отдельности.
Передача обучения
Если вы работаете с нейронными сетями и у вас недостаточно данных для обучения модели, переносное обучение может решить эту проблему.
Передача обучения: практика повторного использования обученной нейронной сети, которая решает проблему, аналогичную вашей, обычно оставляя архитектуру сети неизменной и повторно используя часть или весь вес модели.
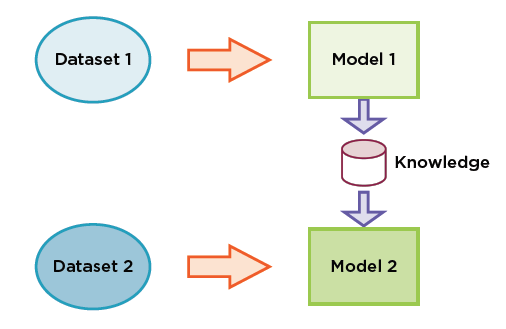
Переданные знания особенно полезны с новым набором данных, когда он невелик и недостаточен для обучения модели с нуля.
Увеличение объема данных

Методы увеличения данных позволяют увеличить количество обучающих выборок, и обычно они используются с данными изображений: вы берете все изображения, с которыми работаете, и каким-то образом изменяете и искажаете эти изображения для создания новых изображений.
Вы можете возмущать эти изображения, применяя масштабирование, вращение и аффинное преобразование. И эти параметры обработки изображений часто используют методы предварительной обработки, чтобы сделать ваши модели классификации изображений, построенные с использованием CNN или вычислительных нейронных сетей, более надежными, их также можно использовать для создания дополнительных образцов, с которыми вы можете работать.
Синтетические данные
Синтетические данные имеют свой собственный набор проблем, по сути, вы будете искусственно генерировать образцы, имитирующие реальные данные. Вы должны понимать, какие данные вам нужны.
Вы можете передискретизировать существующие точки данных для создания новых точек данных или использовать другие методы для создания искусственных данных, но это может внести систематическую ошибку в существующие данные.
Слишком много данных
Может показаться странным, что слишком много данных является проблемой, но какой толк в данных, если это неправильные данные. Данные могут быть чрезмерными по двум причинам:
1- Устаревшие исторические данные: слишком много строк.
Работа с историческими данными важна, но насколько важно, если у вас слишком много исторических данных, которые на самом деле не имеют большого значения, вы можете закончить что-то, называемое «концептуальным дрейфом».
Дрейф концепций. Отношения между функциями (переменные X) и метками (переменные Y) со временем меняются; Модели машинного обучения не успевают за ними, и, как следствие, страдает их производительность.
Дрейф концепций означает, что модель машинного обучения по-прежнему выглядит устаревшей и не более значимой или актуальной.
Итак, если вы работаете с историческими данными, примите во внимание следующее:
- Если его не устранить, это приведет к дрейфу концепции.
- Устаревшие исторические данные представляют собой серьезную проблему, особенно когда вы работаете с моделями машинного обучения, которые работают с финансовыми данными, особенно если вы моделируете фондовый рынок.
- Обычно требуются специалисты-люди, чтобы решить, какие строки следует исключить.
2- Проклятие размерности: слишком много столбцов.
Ваши образцы, которые должны использовать их для обучения модели машинного обучения, и каждый образец могут иметь слишком много столбцов, слишком много функций в простейшей форме, когда вы имеете дело с проклятием размерности, вы можете в конечном итоге использовать нерелевантные функции, которые действительно не помогают вашей модели улучшаться.
Проклятие размерности - это огромная тема, которая была подробно изучена специалистами по данным.
Когда доступно слишком много данных, возникают две специфические проблемы:
- Решаем, какие данные действительно актуальны.
- Агрегирование данных очень низкого уровня в полезные функции.
Исторические данные - довольно сложная проблема для решения, но проблемы проклятия размерности решить легче.
Как?
Вы можете использовать Feature Selection, чтобы решить, какие данные релевантны.
Вы можете использовать Feature Engineering для объединения низкоуровневых данных в полезные функции.
Вы можете выполнить уменьшение размерности, чтобы уменьшить сложность без потери информации.
Непредставительные данные
Есть несколько проявлений нерепрезентативных данных: один вводит неправильные характеристики в вашу модель, а есть и другие проявления. Возможно, что собранные вами данные каким-то образом содержат неточные данные, небольшая ошибка существенно повлияет на вашу модель.
Еще одно проявление нерепрезентативности данных - необъективные данные. Например, вы собираете данные с 5 датчиков из 5 разных мест, и один из этих датчиков не работает все время, ваши данные смещены, потому что у вас нет пропорциональных данных от одного из датчиков. Работа с предвзятыми данными приводит к предвзятым моделям, которые плохо работают на практике.
Вы можете смягчить это за счет передискретизации и недостаточной выборки. Таким образом, если у вас меньше данных с одного из датчиков, вы можете выполнить избыточную выборку из имеющихся данных. Итак, у вас будет репрезентативный образец.
Дубликаты данных

Если вы собираете данные, они могут дублироваться. Если данные могут быть помечены как повторяющиеся, проблему относительно легко решить, просто исключив дубликаты данных перед их загрузкой в вашу модель.
Но мир не так прост, в некоторых приложениях, например потоковой передаче в реальном времени, может быть сложно идентифицировать дубликаты. Вы можете просто жить с этим и учитывать это.
Отсутствующие данные

Когда вы работаете с данными, которые отсутствуют в записях, которые вам нужно обучить вашей модели. Есть два подхода, которым вы можете следовать, чтобы работать с этими данными.
1- Удаление
2- Вменение
Удаление A.K.A. Удаление по списку
Удаляет записи (строки) целиком, если отсутствует одно значение (столбец).
Это простой и беспроблемный метод работы с отсутствующими значениями, но он может привести к смещению, поскольку вы можете удалить очень относительные данные.
Списочное удаление часто является наиболее распространенным на практике, потому что оно простое, но может привести к нескольким проблемам. Это может значительно уменьшить размер выборки, с которой вы работаете. Если у вас не так много записей и вы применили этот подход, может возникнуть ситуация, когда у вас недостаточно данных для обучения модели машинного обучения.
Еще один повод для беспокойства: если значения не пропадают случайно, их удаление может привести к значительному смещению. Например, если вы собираете данные с датчиков и есть датчик, у которого отсутствуют значения в определенном поле, если вы продолжите и удалите все записи с этого датчика. Это может привести к значительной систематической ошибке.
Итак, совершенно очевидно, что просто отбрасывать целые записи, в которых отсутствуют некоторые поля, не самый лучший вариант, поэтому мы переходим к Вменению.
Расчет
Заполните отсутствующие значения столбца, а не удаляйте записи с пропущенными значениями. Отсутствующие значения выводятся из известных данных.
После того, как вы решили использовать замену пропущенных значений методом вменения, вы можете выбрать ряд методов от очень простых до очень сложных.
Самый простой из возможных методов - использовать среднее значение по столбцу. Вы предполагаете, что отсутствующие значения по существу равны среднему значению в этом столбце или для этой функции. Другой очень похожий вариант - использовать среднее значение этого столбца или режим этого столбца.
Другой способ вменения отсутствующих значений я интерполирую из других близлежащих значений. Этот метод полезен, когда ваши записи упорядочены в определенном порядке.
Вменение для заполнения пропущенных значений может быть очень сложным, на самом деле вы можете построить всю модель машинного обучения для прогнозирования отсутствующих значений в ваших данных.
Теперь вы можете выполнить вменение разными способами.
Многовариантное вменение
Одномерное вменение: полагайтесь на известные значения в той же функции или столбце.
Многовариантность вменения: используйте все известные данные для вывода отсутствующих данных.
Например - для многомерного вменения - вы можете построить модели регрессии из других столбцов, чтобы предсказать этот конкретный столбец, вы повторите это для всех столбцов, которые содержат пропущенные значения.
Есть и другие методы, которые можно применить для заполнения недостающих значений.
Hot-deck Imputation
Вы отсортируете все имеющиеся у вас записи по любым критериям. для каждого отсутствующего значения вы можете использовать непосредственно предшествующее доступное значение.
Заполнение пропущенных значений с использованием предыдущего значения, одна из ваших записей была заказана. Это специально используется для заполнения данных временных рядов, где прогрессия во времени имеет полезное значение.
Для временных рядов эквивалентно предположению, что с момента последнего измерения не произошло никаких изменений.
Распространенной техникой, которая часто используется, является замещение среднего значения.
Среднее замещение
Для каждого пропущенного значения подставьте среднее всех доступных значений. Подстановка среднего имеет эффект ослабления корреляции между столбцами, которые существуют в ваших данных.
Когда вы, по сути, называете эту среднюю точку данных, в ней нет ничего особенного, вы ослабляете корреляцию, и это может быть проблематичным при выполнении двумерной Анализ, это анализ для определения взаимосвязи между двумя столбцами.
Если вы хотите разумно предсказать недостающие значения в ваших данных, возможно, вы захотите использовать машинное обучение.
Регрессия
Подобрать модель для прогнозирования отсутствующих столбцов на основе значений других столбцов. Применение этого метода имеет тенденцию усиливать корреляции, существующие в ваших данных, потому что вы, по сути, говорите, что этот столбец зависит от другого столбца.
Регрессия и подстановка среднего для заполнения пропущенных значений имеют взаимодополняющие преимущества
Выбросы
Выбросы: точка данных, которая значительно отличается от других точек в том же наборе данных.
Если вы визуализируете свои данные, вы можете найти что-то вроде этого
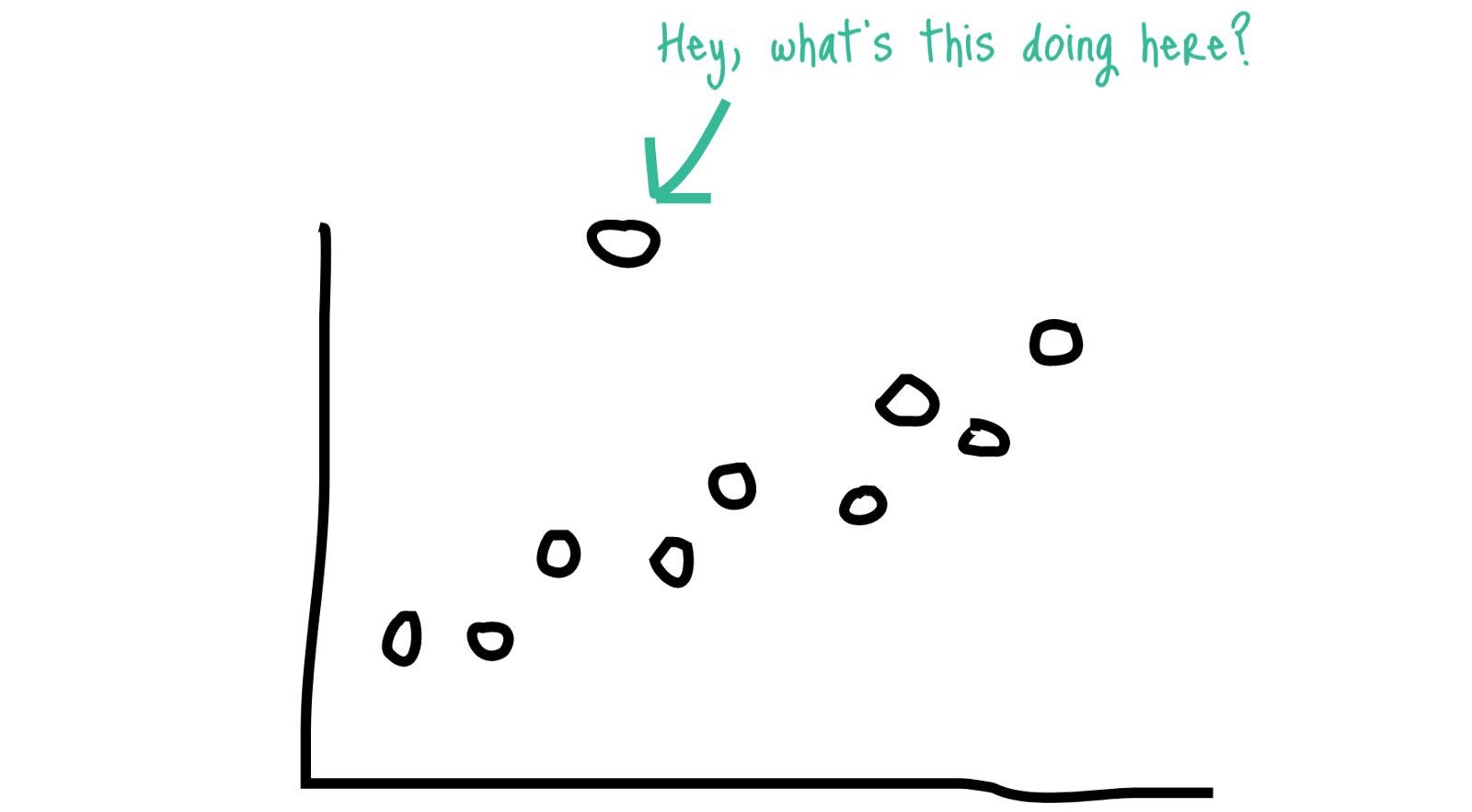
Возможно, вся запись каким-то образом является выбросом или есть определенные поля с выбросами.
При работе с данными выбросов это двухэтапный процесс, первый шаг - это определение выбросов, которые существуют в ваших данных, второй шаг - использование методов, позволяющих справиться с этими выбросами.
Существуют определенные алгоритмы машинного обучения, которые были созданы для обнаружения выбросов, но на самом базовом уровне вы можете идентифицировать выбросы, видя расстояние до этой точки данных от среднего значения ваших данных или расстояние от линии, которую вы вписываете в свои данные.
Определив выбросы, вы можете справиться с выбросами, используя три метода: отбросить записи с данными выбросов, выбросы верхнего / нижнего пределов или установить выбросы на среднее значение этой характеристики.

Выявление выбросов: расстояние от среднего
Если у вас есть точка данных со значением, далеким от среднего значения, которое можно рассматривать как выброс, или вы можете выполнить некоторый регрессионный анализ и найти линию или кривую, которые следуют шаблону в ваших данных, если у вас есть точка, которая далека от этой подходящей линии, которая является выбросом.
Если вы хотите быстро обобщить любой набор данных, с которым вы работаете, первая мера, которую вы укажете, является средним значением этих данных.
Среднее или среднее - это одно число, которое лучше всего представляет все эти точки данных.
Среднее или Среднее любого набора данных - это сумма всех чисел, деленная на количество чисел.

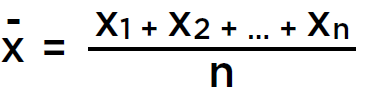
Однако наряду со средним значением также важны вариации, существующие в ваших данных.
Вариант: это показатель того, меняется ли число в вашем наборе данных.
Одним из важных показателей вариации в наборе данных является диапазон.
Диапазоны полностью игнорируют среднее значение, и на него влияют выбросы, которые присутствуют в вашем наборе данных, вот где и проявляется дисперсия.
Дисперсия - это второе по важности число для суммирования любого набора точек, с которым вы работаете.

Среднее значение и дисперсия кратко суммируют любой набор чисел.
Помимо дисперсии, вы можете встретить еще один термин - стандартное отклонение.
Стандартное отклонение: представляет собой квадратный корень из дисперсии и является мерой вариации ваших данных.
Стандартное отклонение помогает вам выразить, насколько далеко конкретная точка данных находится от среднего значения.
Выявление выбросов: расстояние от подогнанной линии

Выбросы также могут быть точками данных, которые не соответствуют тем же отношениям, что и остальные данные.
Как справиться с выбросами
Как только вы определите выбросы, вам нужно выяснить, как вы с ними справляетесь, как вы хотите с ними справляться?
Всегда начинайте с тщательного изучения выбросов, которые существуют в ваших данных
При ошибочном наблюдении:
- Удалите всю запись, если все атрибуты этой точки ошибочны.
- В строке или записи есть один атрибут, который, по вашему мнению, является ошибочным: установите для него среднее значение.
Вполне возможно, что ваши данные о выбросах не являются неправильным наблюдением, это подлинные, законные выбросы. У вас есть 2 подхода к работе с такими выбросами:
- Оставить как есть, если модель не искажена
- Cap / Floor, если модель искажена, но сначала вам нужно стандартизировать ваши данные.
Заключительные слова…
Поскольку вам необходимо использовать данные для принятия важных бизнес-решений, можно с уверенностью сказать, что периодическая очистка и обогащение ваших данных является обязательной.
Спасибо за внимание!
Надеюсь, вам понравилась моя статья об очистке данных.