Индексы
Всем еще раз привет, сегодня мы поговорим об одной из самых интересных тем в SQL Server в частности и в БД вообще — Индексы.
Прежде всего, давайте кратко рассмотрим, что такое индекс. Я предпочитаю аналогию с телефонной книгой. Кто из нас помнит эти гигантские книги с тысячами страниц, тот знает, как сложно было искать хоть одного человека без оглавления. Содержимое таблицы сопоставляет каждого человека с соответствующим ему номером страницы и хранит его в лексикографическом порядке. Итак, когда вы ищете человека, вы сначала заходите в таблицу содержания, затем ищете его имя по алфавиту, когда вы его нашли, вы знаете номер страницы и переходите на эту страницу, а затем видите его номер. Таким образом, мы как бы говорим, что мы проиндексировали всех людей в телефонной книге.
После этой небольшой аналогии я хочу углубиться в эту тему и объяснить различные индексы, которые у нас есть в SQL Server.
- Кластерный индекс. Кластерный индекс — это наиболее распространенный индекс, который используется в SQL Server. Он хранит страницы и строки таблицы в хранилище в соответствии с ключом индекса. Следовательно, может быть только один индекс. кластеризованный индекс по таблице. Индекс сортирует страницы в соответствии с алгоритмом B Plus Tree. Поскольку этот индекс упорядочивает строки и страницы в хранилище, это может повлиять на производительность записи.
- Некластеризованный индекс. Некластеризованный индекс упорядочивает каждую строку в соответствии со столбцом, который мы проиндексировали. Индекс будет сохранен в Страницах индекса и не повлияет на порядок строк и страниц в хранилище. Этот индекс также использует алгоритм B Plus Tree.

- Уникальный индекс. Уникальный индекс — это индекс, который отвечает за уникальность любого нового ключа, поэтому каждый ключ в этом столбце будет отображаться только один раз. Ключ уникального индекса может быть одним или несколькими столбцами. Этот индекс очень важен, когда нам нужно хранить уникальные данные в БД, например, удостоверение личности. Уникальный индекс создается автоматически при создании первичного ключа.
- Индекс с включенными столбцами — Индекс с включенными столбцами похож на обычный некластеризованный индекс, но теперь мы сохраним с нашим ключом другие значения столбцов. Это очень полезно для повышения производительности, когда два или более столбца часто запрашиваются вместе. я объясню
Небольшой перерыв, чтобы понять включенные столбцы и поиск ключа.
Поиск ключа — это операция, когда SQL Server ищет другие значения строки, чтобы получить их, давайте посмотрим пример.
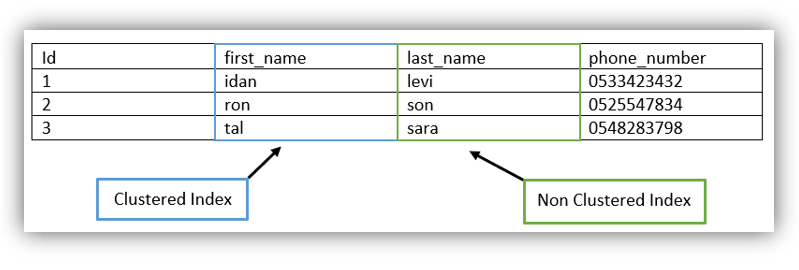
В приведенной выше таблице у нас есть кластеризованный индекс по first_name и некластеризованный индекс по last_name. Когда мы будем искать last_name «sara», SQL Server будет искать в некластеризованном индексе «sara» в соответствии с B Plus Tree, пока все хорошо. Но если мы захотим получить еще и ее имя_имя, то SQL Server также должен будет искать ее имя_имя в кластеризованном индексе, это поиск ключа.
Итак, если мы захотим получить first_name быстрее, и чтобы сохранить этот другой поиск, мы можем сохранить значение first_name со значением last_name, это включенные столбцы, и когда SQL Server будет искать last_name «sara», он также сможет немедленно получить имя first_name «tal».
Вернуться к нашим указателям
- Полнотекстовый индекс. Полнотекстовый индекс — это очень большая тема, включающая функцию полнотекстового поиска SQL Server. Короче говоря, этот индекс будет индексировать символы текста, которые у нас есть в столбце, это будет использоваться для выполнения интеллектуальных запросов слов, предложений и так далее. Полнотекстовый указатель отличается от других наших указателей, и существует множество ресурсов, посвященных этой теме.
- Пространственный индекс. Пространственный индекс — это индекс, разработанный для географических целей. В SQL Server мы можем сохранять географические объекты, такие как точка, линия и многоугольник. Пространственный индекс увеличивает количество операций, которые необходимо выполнить при расчете географических операций.
- Фильтрованный индекс. Фильтрованный индекс похож на обычный индекс, но разница в том, что в фильтрованном индексе мы будем индексировать только часть всех строк. Мы можем думать, что это похоже на некластеризованный индекс для определенных значений. Этот индекс может помочь нам, создавая небольшие и из-за этого быстрые поиски.
- XML-индекс — XML-индекс, предназначенный для разбивки компонентов XML и индексации их для быстрого доступа. Без этого индекса каждый отдельный запрос будет занимать много времени, поскольку для преобразования в реляционный формат его необходимо разбить на компоненты.
- Индекс хранилища столбцов. Индекс хранилища столбцов — это индекс, разработанный для большого объема данных, который часто используется в таблицах, связанных с хранилищами данных. В отличие от других индексов и страниц, на которых хранятся строки, индекс хранилища столбцов хранит столбцы, а не строки. Обычно этот индекс также допускает большое уплотнение, потому что данные будут более похожими.
- Индекс вычисляемых столбцов. Этот тип индекса позволяет нам индексировать вычисляемые столбцы. Вычисляемые столбцы — это виртуальные столбцы, которые не сохраняются (если только мы не объявим PERSISTED). Этот индекс может индексировать этот тип столбца.
- Хэш-индекс — хэш-индекс — это общеизвестный тип индекса, который существует не только в SQL Server, но и во многих других БД, и он является одним из моих любимых. Хэш-индекс использует хеш-функцию для создания хеш-значения для каждого ключа. Это хеш-значение представляет собой соответствующее ведро, содержащее указатель на данные. Это помогает нам очень быстро добраться до определенных ключей, но мы должны помнить, что этот индекс не подходит для большого объема данных.

После того, как мы рассмотрели большинство типов индексов SQL Server, мы теперь можем определить, какие из них подходят для наших таблиц, и улучшить нашу производительность!
Большинство ваших индексов, вероятно, будут кластеризованными и некластеризованными индексами, но теперь вы можете проверить, подходят ли они для наших таблиц. есть особые случаи, которые подходят для других типов и делают ваши запросы более быстрыми и эффективными.
Спасибо за чтение, надеюсь, вам понравилось, увидимся в следующий раз!