
7 функций Pandas, которые уменьшат вашу нагрузку на манипуляции с данными
Есть причина, по которой у панд нет седых волос
Почему у панд нет седых волос? Очевидно, что, поскольку у них так много умных функций для манипулирования данными, они не уделяют этому столько внимания, как их коллеги-люди.
Кажется, что данные никогда не поступают в той форме, в которой мы их хотим. По моему личному опыту, подавляющее большинство времени, затрачиваемого на проект по науке о данных, просто тратится на манипулирование данными. Когда есть что-то, что мы хотим сделать с данными, но мы просто не знаем удобной функции pandas, которая могла бы это сделать, пора воспользоваться старым for циклом и .loc вручную изменить ячейки, руководствуясь оператором if.
В этой статье я покажу и объясню 7 функций pandas, которые при использовании по отдельности или вместе, надеюсь, избавят вас от стресса, связанного с манипуляциями с данными.
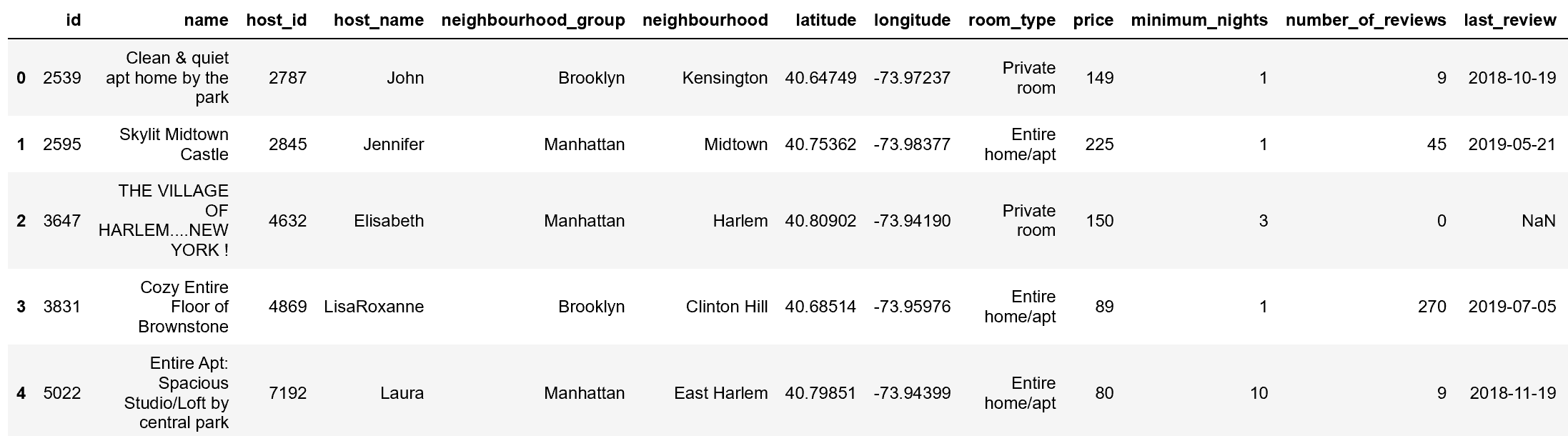
Для демонстрации мы в основном будем работать с Открытыми данными New York City Airbnb, которые содержат набор типов данных, включая числа, текст и даты.
1 | pandas.factorize (х)
Когда нам нужно пометить что-то для кодирования, обычно вы используете sci-kit learn’s LabelEncoder, но панды могут делать это без какого-либо импорта. Кроме того, доступ к меткам соответствует тому, что требует вызова функций из объекта LabelEncoder в sklearn, но по умолчанию включен в pandas.
Допустим, мы хотим пометить кодировку столбца neighbourhood в данных.
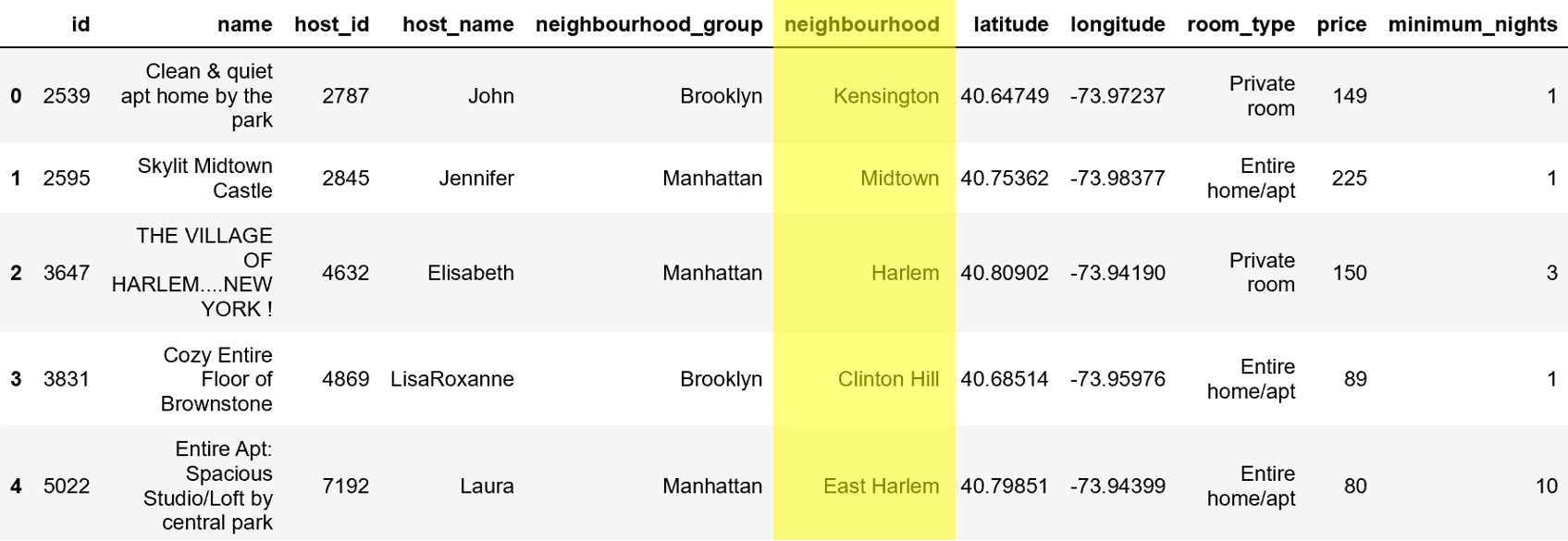
pd.factorize(data['neighbourhood'])
дает

Первый элемент кортежа - это массив, содержащий закодированные метками значения Серии. Второй элемент кортежа - это индекс / список, где индекс каждого элемента соответствует метке в первом элементе. Например, это первое значение с кодировкой метки равно 0. Это означает, что его значение с обратной кодировкой является 0-м индексом второго элемента кортежа, которым является Кенсингтон (вы можете прокрутить вверх, чтобы подтвердить это).
2 | pandas.get_dummies (х)
Иногда Label Encoding не работает по той причине, что она присваивает числовые свойства объектам, которые не являются числовыми по своей сути, например, «Гарлем в два раза больше Кенсингтона» или «Кенсингтон плюс три - это Бруклин». В этом случае предпочтительным является однократное кодирование, которое не имеет числового смещения и представляет те же данные (хотя и в очень редкой форме).
Традиционный способ сделать это - использовать sklearn’s OneHotEncoder, который требует импорта sklearn и обучения объекта OneHotEncoder.
Скажем, мы хотели One-Hot Encode тот же neighborhood column из набора данных.
pd.get_dummies(data['neighbourhood'])

Он даже расставляет столбцы для нас в алфавитном порядке!
3 | pandas.qcut (x, квантили)
Часто с задачами регрессии (такими как прогнозирование цены листинга на Airbnb в этом примере) может быть полезно разделить диапазон цен на несколько квантилей (корзины равного размера). Это может повысить точность и уменьшить неопределенность модели в случае, если квантили приемлемы.
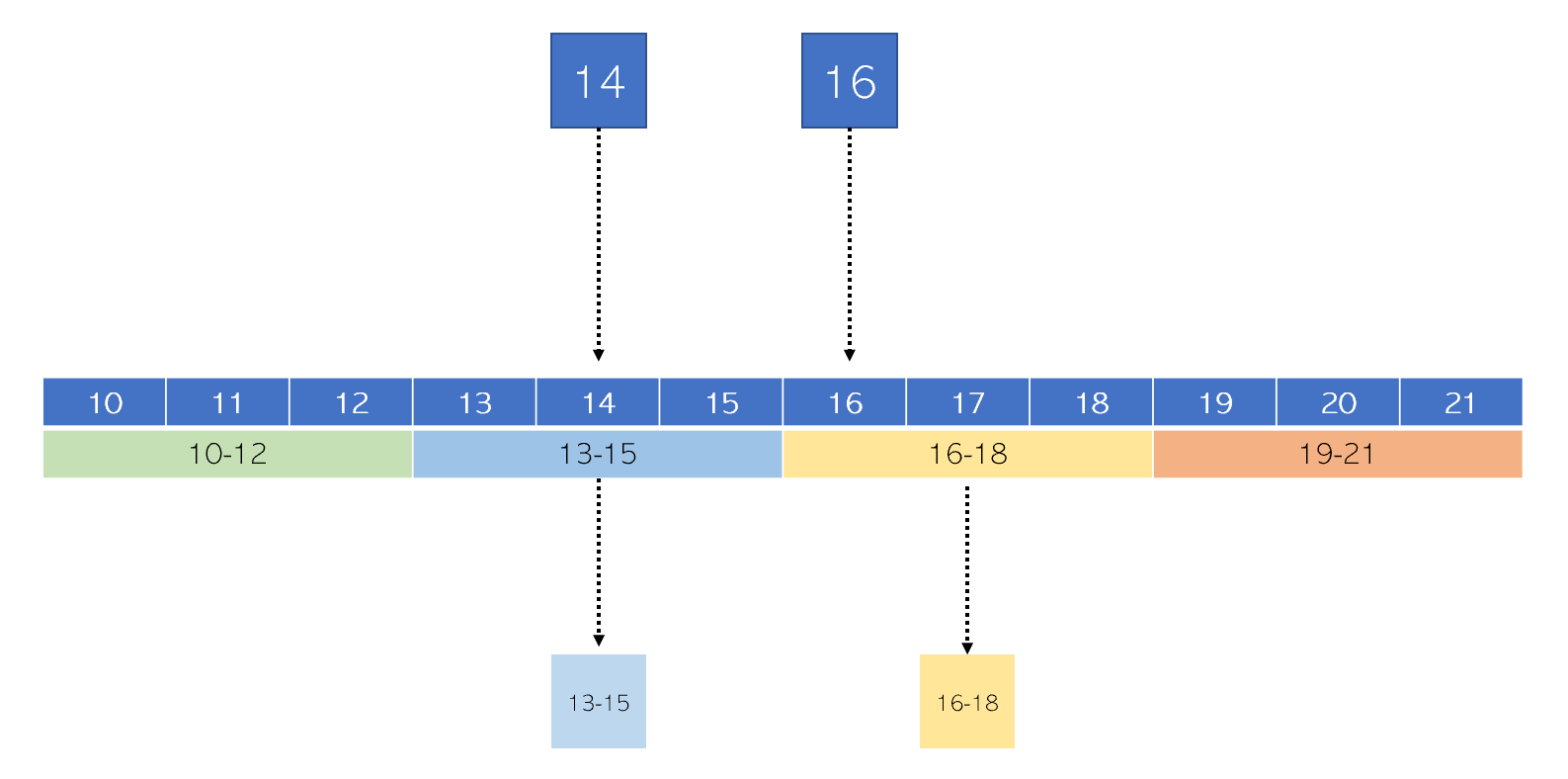
pandas может автоматически дискретизировать переменные с помощью .qcut.
Допустим, мы хотим разделить переменную price на четыре квантиля. pandas автоматически разделит ценовой диапазон на любое количество заданных вами квантилей. Обратите внимание, что pandas разделяет ценовой диапазон на сегменты так, чтобы в каждом сегменте было равное количество товаров.

pd.qcut(data['price'],4) #second number specifies num of quantiles
дает

Это серия интервальных объектов. В каждом интервале ровное количество объектов. Глядя на первый объект в серии,
pd.qcut(data['price'],4)[0]

… Это объект Interval. Вы можете преобразовать его в более читаемый вид, применив str().
str(pd.qcut(data['price'],4)[0])
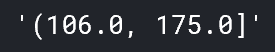
Вы можете использовать .apply(), чтобы применить функцию ко всей серии. Затем, если хотите, вы можете использовать .factorize для обозначения кодирования дискретных выборок. В использовании этой и предыдущей .factorize функции замечательно то, что, в отличие от некоторых случаев, кодирование меток (вместо One-Hot Encoding с .get_dummies впоследствии) нормально само по себе.
Причина, по которой одноразовое кодирование заключается в том, что кодирование меток устанавливает числовые отношения между метками, например, говоря, что Кенсингтон меньше, чем Гарлем, с объектами, которые нельзя сравнивать численно. Однако дискретные выборки могут быть, потому что они были взяты из числовой непрерывной линии.
Обратите внимание: если вы хотите, чтобы квантили разделялись не так, чтобы в каждой ячейке было равное количество точек данных, а чтобы диапазон количественно разделялся на равные части, используйте pandas.cut. Он принимает те же параметры и действует так же, как pandas.qcut.
pd.cut(data['price'],4)
4 | pandas.to_datetime (x)
Преобразование объектов данных - один из самых неприятных аспектов очистки данных и манипулирования данными, из которых, пожалуй, больше всего относятся к датам. Они бывают разных форм и написаны разными способами, поэтому преобразование их всех в чистый объект datetime - проблема.
Введите to_datetime панд. Эта функция может разумно вывести любую дату и преобразовать ее в объект datetime - без необходимости импортировать datetime или какой-либо другой модуль!
Давайте создадим четыре столбца с разными протоколами именования:
data['date1'] = '1,2,2019' data['date2'] = '1/2/2019' data['date3'] = '1-2-2019' data['date4'] = '1.2.2019'
… И примените to_datetime, чтобы увидеть, как pandas преобразует его.

Pandas автоматически конвертирует все за вас! Если даты расположены немного иначе, панды также могут принимать строку, описывающую расположение месяцев, дней и лет.
5 | pandas.DataFrame.T
Функция транспонирования матрицы - это когда оси x и y меняются местами друг с другом, и, следовательно, матрица отражается по диагональной линии.

Это также полезно для DataFrames. Например, посмотрите на этот временной ряд данных о смертях от коронавируса в каждой стране по дате.

Выбрав только Соединенные Штаты для построения данных и удалив столбцы, такие как страна, провинция, широта и долгота, мы получим странную форму данных.
us = data[data['Country/Region'] == 'US'] us.drop(['Province/State','Country/Region','Lat','Long'],axis=1,inplace=True) us

Наивный способ приблизиться к этому - скопировать каждое значение столбца в массив numpy для визуализации. Однако с функцией транспонирования все просто.
us = us.T us

Отсюда легко строить графики.
us.plot()

Это сэкономило нам много работы!
6 | pandas.DataFrame.drop_duplicates ()
Огромная проблема данных - это дублирование данных. Дублирующиеся данные часто поднимают свою уродливую голову в данных, которые собираются из нескольких источников, что приводит к дублированию строк. Слишком много повторяющихся строк повлияет на анализ или модель машинного обучения, поэтому их важно удалить.
У Pandas есть функция по умолчанию для удаления дубликатов, drop_duplicates().
Давайте установим первую строку равной второй, а затем удалим все дубликаты.
data.loc[1] = data.loc[0] data.drop_duplicates()

Первый ряд отсутствует. В целях демонстрации мы сохранили индекс, чтобы продемонстрировать разрыв в первой строке (первый индекс, вторая «строка», если вы хотите ссылаться на нее таким образом). Однако .drop_duplicates() принимает дополнительный необязательный параметрignore_index, который, если установлен в True, будет создавать непрерывный индекс, не прерываемый удалениями.
7 | pandas.Series.clip ()
Выбросы. Они портят анализ и скидывают данные. Для устранения выбросов в pandas есть удобная функция .clip () для удаления не только выбросов, но и потенциальных ошибок в данных (таких, как я недавно видел в наборе данных, отрицательное количество случаев коронавируса).
.clip() принимает два параметра - верхний и нижний - и присваивает любые значения выше верхней границы верхней границе и любые значения ниже нижней границы нижней границе.
Например, предположим, что Airbnb имеет правило, согласно которому максимальная цена, которую можно выставить на продажу, составляет 125 долларов, а самая низкая - 100 долларов, и все, что указано за пределами этих границ, является ошибкой (преувеличенная гипотеза).
Для справки первоначальные цены:

Давайте установим столбец цен в усеченную версию самого себя с нижними и верхними границами, которые мы понимаем из реального контекста.
data['price'] = data['price'].clip(100,125) data.head()

Все цены выше 125 долларов были установлены на уровне 125 долларов, а любые цены ниже 100 долларов были установлены на это значение. .clip() всегда следует применять с учетом контекста, чтобы гарантировать отсутствие ошибок, или / и использовать со статистическими границами выбросов.
Спасибо за прочтение!
Я надеюсь, что эти семь функций смогут сделать ваши манипуляции с данными, их очистку и анализ немного более плавными.