
Машинное обучение окружает нас повсюду, от прикосновения пальцев через автокоррекцию до интегральных технологий, которые строят наш мир. С годами машины становятся все умнее и адаптируемее, а механический интеллект достиг рекордно высокого уровня. Но что именно все это означает? Что на самом деле изучают наши машины? Ну, проще говоря, они узнают о нас. Они пытаются присоединиться к миру, о котором знают только благодаря нашему вкладу.

Информацию можно собрать практически обо всем, и, как показано на рис. а, все начинается как ввод. Это получено через модель обучения, а затем отправлено на выход. Получив ошибку, машина снова входит в модель обучения, чтобы выполнить правильный вывод, в конечном итоге извлекая уроки из опыта. Имея в виду этот базовый поток, существует три основных способа реализации моделей машинного обучения.
Обучение с учителем, обучение без учителя и обучение с подкреплением.
В этом видеоролике Simplilearn представлен широкий обзор тем, которые я буду освещать. Он отлично справляется с разбивкой концепций на составные части.
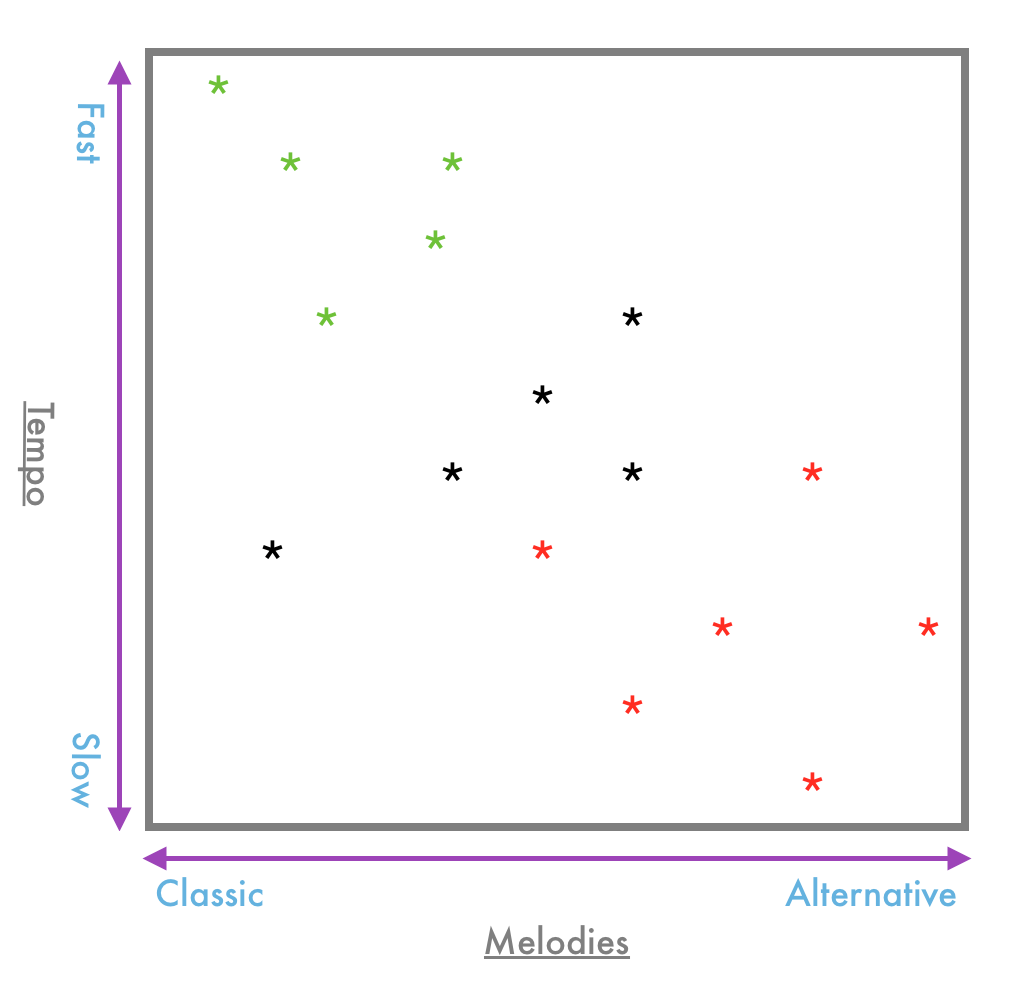
В нашем примере на рис. б) у нас есть простой график выбора песен, сгенерированный сервисом потоковой передачи музыки. Красные звездочки обозначают неприязнь, а зеленые — лайк. Учитывая все обстоятельства, машина должна угадать, попадают ли черные звезды в категорию «нравится» или «не нравится». При контролируемом и неконтролируемом обучении это осуществляется посредством обучения на основе данных, в то время как обучение с подкреплением осуществляется путем обучения на основе вознаграждения. Обучение, основанное на данных, может быть полезно для систем статистики и количественной информации, но в случае чего-то более тонкого и субъективного обучение с подкреплением может быть лучшим выбором для разработки. В этом типе обучения информация собирается на основе проверки предыдущих ответов для достижения результата. Это означает, что, хотя ей потребуется человеческое прикосновение, в конечном итоге машина должна стать достаточно самостоятельным, чтобы адаптироваться и расти самостоятельно.

Здесь мы видим на рис. c упрощенный обзор отношений между стилями машинного обучения. В этом мы можем видеть тонкие различия намного яснее. Хотя и контролируемое, и неконтролируемое обучение основаны на собранных данных, они имеют несколько существенных отличий. Обучение с учителем основано на размеченных данных, которые машина получает от человека. Затем машина связывает ранее определенные функции с каждым входящим элементом, что в конечном итоге приводит к набору знаний, созданных человеческим прикосновением. Неконтролируемое обучение основано на неразмеченных данных, поэтому человеческий фактор отсутствует. Обучение основано исключительно на естественных шаблонах входящих данных, а затем интерпретируется на основе этих кластеров информации. Обучение с подкреплением сочетает в себе как человеческое, так и машинное руководство в своем обучении, создавая совершенно уникальный стиль обучения от машины к машине. Этот стиль обучения основан на сохранении прошлых ошибок и способности развиваться с накопленными решениями. В этой модели чем больше вещей проходит, тем выше должна быть точность.

Учитывая все вышесказанное, наиболее важной частью машинного обучения является обработка ошибок. Единственный способ, которым машина может правильно обучиться, - это ответ после первоначальной ошибки вывода. Независимо от того, предоставлено ли это или создано, основано на данных или на основе ошибок, собранная информация действительно удивительна. Машинное обучение может полностью изменить структуру мира, каким мы его знаем, упорядочив нашу жизнь и сделав ее более эффективной.
Теперь, когда у нас есть общее представление о машинном обучении, давайте свяжем его с некоторыми примерами. На рис. b мы говорили о моделях обучения в отношении симпатий и антипатий. Та же идея может быть применена к более серьезным вопросам, таким как соблюдение условий обслуживания компании. В этой идее пользователь загружает контент, который каким-то образом нарушает его Пользовательское соглашение. Машинное обучение может быть реализовано для фильтрации контента, инициирования нарушения, а затем удаления рассматриваемого контента. В случае ошибки будет осуществлена ручная проверка, и машина будет уведомлена. Этот процесс позволяет получить огромное количество информации для данной модели обучения и в конечном итоге приводит к лучшим результатам. Короче говоря, и люди, и машины больше всего учатся на том, как они справляются со своими ошибками.
Простые способы, которые можно увидеть в реальном мире, — это реализованная на YouTube модель обучения с подкреплением на их платформе. Первоначально создатели и зрители были поражены решениями, которые принимала их система. Со временем была заметна разница в точности, даже в случае невероятно тонких вопросов. Конечно, нет ничего идеального, но это прекрасный пример того, как со временем все действительно может развиваться. Видно на рис. d, генеральный директор YouTube Сьюзан Войжитски затрагивает несколько тем, в том числе эту концепцию и будущее технологии, лежащей в основе платформы.
В то время как некоторые компании столкнулись только с противоречиями, нет ничего хуже, чем риск для жизни человека из-за машинного обучения. Один из способов, которым это сразу видно, — это полная автоматизация беспилотных автомобилей. В статье ниже от Forbes как раз это и обсуждается.

Видно на рис. На графике, предоставленном Cognilytica, беспилотные автомобили основаны на системе уровней от 0 до 5, где ноль — это почти каждый автомобиль на дороге. Автомобиль более высокого класса с одной функцией, такой как самостоятельная парковка, будет иметь уровень 1 или 2 в зависимости от технических характеристик. Функция AutoPilot от Tesla оценивается на уровне 3 и предлагает полное вождение с человеком наготове! Автомобиль, упомянутый в статье Forbes, находится на уровне 4 или 5, где в настоящее время очень немногие автомобили занимают этот уровень. Даже в вышеупомянутом случае тестового запуска беспилотного автомобиля Uber водитель был наготове. Поскольку эта технология уже использовалась, казалось, что все в их пользу, но трагически в марте 2018 года автомобиль сбил пешехода и убил его. Хотя это абсолютно наихудший сценарий, он заставляет нас задуматься, как этого можно было избежать? Были ли пропущенные пограничные случаи в программном обеспечении?

Предотвращение этого наихудшего сценария должно быть в центре внимания каждого программиста. В приведенной выше лекции это обсуждается, а также важность обучения на периферии. Эта концепция позволяет машине принимать еще более важные решения с большей точностью и точностью, что, как мы надеемся, способствует более быстрому развитию машинного обучения. В основном в более простых терминах, проиллюстрированных на рис. g, хотя общие знания для всей платформы находятся в более удаленном облаке, информация для более индивидуального опыта должна оставаться локально внутри машины. Если у машины нет достаточно близкого доступа к этим прошлым реакциям, эффективность предыдущего обучения ставится под угрозу. С появлением машинного обучения в различных областях необходимо установить эти прецеденты в структурах того, как эта технология будет реализована, прежде чем она еще больше интегрируется в наше общество.
С другой стороны, машинное обучение произвело революционную революцию в здравоохранении. Возможность вводить полностью неструктурированные данные и синтезировать их в организованные пакеты является революционной. Некоторые из этих замечательных приложений обсуждаются в статье IBM ниже.
«ИИ — это инструмент. Выбор того, как он будет развернут, остается за нами». -Орен Эциони
Хотя искусственный интеллект появился в медицине еще в 1972 году, в здравоохранении он не использовался по-настоящему до середины 2000-х годов. Здесь на рис. g, мы узнаем об IBM Watson, невероятной технологии, используемой в онкологии. В такой сложной области медицины наличие искусственного интеллекта для помощи пациентам действительно может быть разницей между жизнью и смертью. Здесь мы видим, как Watson реализуется различными способами, от генетических факторов до медицинских противопоказаний, технология способна интерпретировать множество совершенно неорганизованных данных и помогать в уходе за пациентами. Поскольку технологические достижения в медицине происходят быстро, жизненно важно, чтобы медицинские работники были готовы справляться со всей возникающей новой информацией. По своей природе человеческий разум имеет конечные пределы обучения изо дня в день, еще меньше в отношении бессонницы, которую может получить медицинский работник. Было бы наивно не использовать эту невероятную технологию, чтобы уменьшить вероятность предотвратимой человеческой ошибки. Хотя у машинного обучения и искусственного интеллекта может быть кривая обучения, чем раньше будет реализована модель обучения, тем лучше технология может стать для нашего будущего.
Здесь, в приведенной выше статье, мы можем видеть в статистике использования искусственного интеллекта за 2019 год, что, хотя машины не используются на полную мощность, технология, безусловно, находится на подъеме по ряду направлений. Буквально со всех концов света машинное обучение может быть реализовано в ближайшие пару десятилетий. Учитывая все обстоятельства, будет интересно посмотреть, к чему нас могут привести эти технологические достижения. Имея возможность для машин должным образом учиться на всех входных данных, которые мы можем предложить, мы действительно живем в эпоху, когда люди растут вместе с машинами.

— — — Написано Кэтлин Маккирнан для Holberton New Haven — — —
