Рабочие прототипы в воздухе

Эксперимент с цифровым сонаром, часть 1
Последние 10 лет или около того я хотел создать какого-нибудь подводного робота. Я предполагаю, что это результат слишком большого чтения Касслера и небольшого погружения с аквалангом, но я не могу избавиться от этого. С большим интересом слежу за рядом проектов, в частности OpenROV. Одна из проблем, с которой, похоже, не так много занимались любители, - это доступный подводный гидролокатор. Существует множество недорогих гидролокаторов для наземной и воздушной робототехники - современные радиоуправляемые дроны хорошо используют их для измерения на малых высотах - но, похоже, их пока нет для использования в воде.
Я решил, что имеет смысл сначала понять алгоритмы и отладить их в воздухе, поскольку в воде звук распространяется намного быстрее, а в воде возникают проблемы с акустической связью и гидроизоляцией, которые не являются проблемой в воздухе.
Я решил сначала изучить, что можно делать на ПК, просто для простоты программирования. Я обнаружил, что это было сделано раньше, успешно и хорошо задокументировано этим джентльменом. Его страница содержала очень полезную информацию об обнаружении эха, знакомя меня с идеей корреляционных функций для обнаружения короткого сигнала в другом потоке сигналов. Обладая этой информацией, я нашел онлайн-книгу по цифровой обработке сигналов (DSP), в которой обсуждались корреляционные функции и их использование.
Обнаружение эха
Когда я начал это делать, я ничего не знал об обработке сигналов и был удивлен, что это не так уж сложно с точки зрения алгоритмов. Это действительно требует значительных вычислений. По сути, после нормализации аудиосигнал состоит из набора значений амплитуды от -1 до 1 при некоторой частоте дискретизации. Для человеческих звуковых частот это обычно 44100 выборок в секунду. Причина этого в том, что для идеального воспроизведения сигнала вы должны дискретизировать его на вдвое большей частоте, которую вы хотите воспроизвести. Это Рейтинг Найквиста. Следовательно, частота 44100 Гц должна быть способна идеально воспроизводить сигнал до 22050 Гц, что, как я полагал, было пределом аудиооборудования моего ноутбука. Стоимость секунды звука составляет 44100 значений с плавающей запятой от -1 до 1.
Самый простой способ выполнить функцию корреляции - загрузить в один массив искомый опорный сигнал - пинг - и другой массив с записанными результатами. Начните с записанного массива в позиции 0 и умножьте каждое значение в chirp на следующие $ chirplength сэмплы из записанного звука. Суммируйте произведения каждого умножения (по сути, вычисляя площадь под результирующей кривой) и запишите его в массив результатов в позиции 0. Сдвиньте в позицию 1 в записанном звуковом массиве и повторите, на этот раз сохраняя результаты в позиции 1 диаграммы. массив результатов. Повторите эти действия для всех позиций в записанном звуковом массиве, пока не дойдете до места, где длина щебета пройдет мимо конца записанного звукового массива, и остановитесь.
Вы создаете скользящее окно, сравнивая щебетание с каждым фрагментом звука в записанном звуковом массиве. Результат корреляции действительно интересен - когда звук очень близок, вы получаете большой положительный всплеск результатов, который соответствует положению в записанном звуке. Этот всплеск представляет собой копию вашего щебета в записанном аудио. В первый раз, когда вы его видите, это чириканье, которое отправил ваш динамик. После этого - отголоски этого щебетания предметов.
Зная положение каждого эхо-сигнала, вы можете вычислить время, которое прошло с момента отправки первичного импульса с вашей частотой дискретизации. В то время звук был в полете. Разделите на два, чтобы пройти туда и обратно, сравните со скоростью звука и бум, вы достигли цели. Аккуратно, а?
Функция корреляции лучше всего работает с щебетанием - звуком, частота которого меняется со временем. Чириканье должно быть очень коротким, иначе эхо появится до того, как закончится чириканье. Я обнаружил, что чириканье в диапазоне 1,5 мс дало мне наилучшие результаты - оно дает минимальный диапазон 3–4 футов. Я генерировал щебетание в Audacity, колеблющееся от 4000 до 10000 Гц при полной амплитуде.
Вот записанный фрагмент звука с щебетанием, некоторым эхом и фоновым шумом.
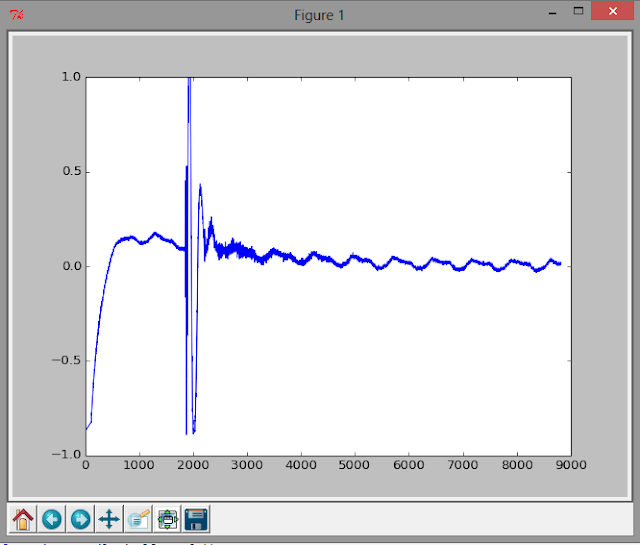
Вот результат корреляционной функции:
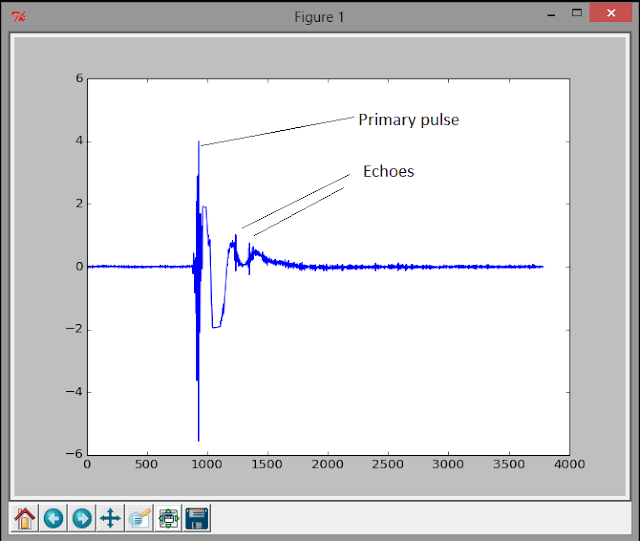
Как только вы сможете сделать это для одного чирикающего сигнала, вы можете назначить интенсивность всплескам и построить график их для множества импульсов. Это дает вам вид типа эхолота - в этом примере время идет сверху вниз, а расстояние слева направо. Обратите внимание на шум в дальней левой части изображения - он, вероятно, вызван тем, что динамик продолжает «звонить» в течение нескольких миллисекунд после прекращения сигнала.
Этап 1. Версия для ПК с оборудованием для телеконференций
Я выбрал WinPython с библиотекой PyAudio для тестирования, потому что он поставляется в комплекте с библиотеками для построения графиков и другими полезными вещами. Я использовал комбинированный USB-микрофон / динамик, предназначенный для использования VOIP, потому что я мог перемещать его, и он был довольно направленным.

Это работает - вот пример прогона, показывающий возвратные сигналы с динамиком / микрофоном, начинающимся у стены, а затем медленно движущимся в сторону, затем обратно и т. Д. Вы можете увидеть белую линию, которая выглядит как пики и впадины, соответствующие расстоянию, вдоль с фоновым шумом и многолучевым эхом. Минимальное расстояние было около 3 футов, максимальное - около 8.
В левой части экрана показано расположение датчика - представьте, что он прикреплен к корпусу лодки. Белые и серые точки представляют собой эхо-сигналы на разном расстоянии. Белая линия, возникающая при удалении динамика / микрофона от стены, смещается вправо, указывая на большее время полета и большие расстояния. Когда я приближаю его к стене, он становится ближе к левой стороне экрана. Один из способов визуализировать это - если датчик был установлен на лодке, линия показывала бы глубину воды над дном. Вы также получаете более слабую отдачу для звуков, которые отскакивают от непрямых дорожек или косяков рыб.

Этап 2. Версия микропроцессора
Следующим логическим шагом, казалось, было заставить его работать на микроконтроллере. Доступно множество недорогих ультразвуковых модулей сонара, которые действительно хорошо работают в воздухе, но идея заключалась в том, чтобы получить гидролокатор, который работал бы в воде. Кроме того, недорогие модули выдают только одно эхо - при таком подходе к обработке сигналов вы получаете серию эхо, которые могут передавать больше информации об окружающей среде. Например, лодка, плывущая над косяком рыб, может обнаруживать и рыбу, и дно.
Я выбрал Stellaris Launchpad из-за высокоскоростных аналого-цифровых преобразователей (АЦП) и оперативной памяти объемом 32 кБ. При требуемой частоте дискретизации у Launchpad достаточно ОЗУ, чтобы отправить щебетание, а затем записать долю секунды звука, чтобы можно было определить эхо. Для звука с более высокой частотой потребуется более высокая частота дискретизации, поэтому мне может потребоваться переключиться на Teensy 3.1 с 64 КБ ОЗУ.
Форма волны ЛЧМ-сигнала вычисляется и отправляется на небольшой пьезо-динамик, управляемый простой транзисторной схемой. Напряжение питания пьезоэлемента (VCC на диаграмме ниже) обеспечивается тремя последовательно включенными девятивольтовыми батареями для получения 27 В. На этой схеме показано, как это связано. Это не моя диаграмма - я нашел ее в Интернете, но у меня нет ссылки. Если это ваш, пожалуйста, напишите мне.
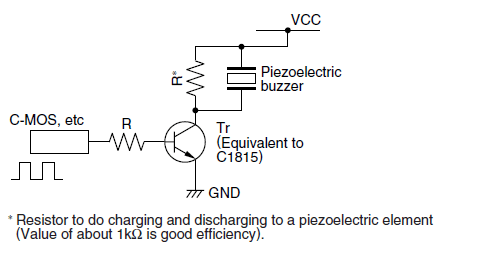
Обратное эхо улавливается маленьким усиленным микрофоном от Adafruit. Мне нравится этот модуль, потому что он имеет встроенный сдвиг уровня. Вместо того, чтобы качаться от -V до + V, он сдвигается с 0 до +3,3 В, чтобы его можно было подключить к АЦП. Очень удобно.
Пара деталей, напечатанных на 3D-принтере, удерживает все это на плате, чтобы она была направлена в правильном направлении.


Посылается щебетание, и сразу начинается запись звука, чтобы уловить эхо. Та же функция корреляции, что и в предыдущем разделе, используется для извлечения эха из записанного звука. Интенсивности корреляционной функции отправляются через порт отладки на ПК, чтобы можно было построить график.
Мне нужно поработать над оптимизацией кода обнаружения эха - в настоящее время он работает со звуком от каждого импульса в течение 4 секунд или около того. Кроме того, выходная мощность аудиопреобразователя очень мала, поэтому диапазон довольно ограничен. Он имеет эффективный диапазон от 3 до 9 футов. Ближе чем 3 фута, эхо трудно выделить из шума, производимого при отправке импульса.
Как и в оригинальных экспериментах с динамиком / микрофоном, результаты отображаются с помощью простой программы Python, настроенной аналогично дисплею типа эхолот. Результаты пробного запуска показаны ниже.


. Эксперименты с гидролокатором для воды
Хотя обработка сигнала работает нормально, я еще не смог получить что-то, что правильно передавало и принимало звук в воде. Я думаю, это связано с трудностью эффективного сочетания звука с водой и чрезвычайно низкой выходной мощностью. Я также подумал о том, чтобы просто попытаться взломать одну из новых поплавков, в которых есть гидролокаторы малой мощности. Жалко, что производители этих устройств не продают версии с хорошим серийным выходом - энтузиасты ROV купят их в мгновение ока.
Надеюсь, это полезная отправная точка для энтузиастов-единомышленников - я представляю код ПК ниже.
Спасибо! Если вы знаете, как эффективно соединить звук с водой, нам следует поговорить.
import pyaudio
import wave
import struct
import math
import pylab
import scipy
import numpy
import matplotlib
import os
import scipy.io.wavfile
import threading
import datetime
import time
from Tkinter import *
class SonarDisplay:
#Displays greyscale lines to visualize the computed echos from the sonar pings. Time and distance increase as you go from left to right. It's like a fishfinder rotated on its side.
def __init__(self):
self.SCREENHEIGHT = 1000
self.SCREENWIDTH = 1024
self.SCREENBLOCKSIZE = 2
master = Tk()
self.w = Canvas(master, width=self.SCREENWIDTH, height=self.SCREENHEIGHT, background="black")
self.w.pack()
def getWidth(self):
return self.SCREENWIDTH
def getHeight(self):
return self.SCREENHEIGHT
def getBlockSize(self):
return self.SCREENBLOCKSIZE
def plotLine(self, result, y):
x = 0
numJunkSamples = 250
intensityLowerThreshold = .26 #peaks lower than this don't get plotted, since they are probably just background noise
#on my machine, the first couple hundred samples are super noisy, so I strip them off
#these are the first samples immediately after the peak that results from the mic hearing the ping being sent
#Until the echo is clear of these (about 3 feet in air) it is hard to pull out of the noise, so that is minimum range
result = result[numJunkSamples:]
limit = self.SCREENWIDTH / self.SCREENBLOCKSIZE
if limit < len(result):
limit = len(result)
for a in range(0,len(result)):
intensity = 0
if (result[a] > intensityLowerThreshold):
intensity = result[a] * 255.0
if (intensity > 255):
intensity = 255
if (intensity < 0):
intensity = 0
rgb = intensity, intensity, intensity
Hex = '#%02x%02x%02x' % rgb
self.w.create_rectangle(x, y, x + self.SCREENBLOCKSIZE, y + self.SCREENBLOCKSIZE, fill=str(Hex), outline=str(Hex))
x = x + self.SCREENBLOCKSIZE
self.w.update()
class Sonar:
#Mic initialization and audio recording code was taken from this example on StackOverflow: http://stackoverflow.com/questions/4160175/detect-tap-with-pyaudio-from-live-mic
#Playback code based on Pyaudio documentation
def callback(self, in_data, frame_count, time_info, status):
data = self.wf.readframes(frame_count)
return (data, pyaudio.paContinue)
def __init__(self):
self.FORMAT = pyaudio.paInt16
self.SHORT_NORMALIZE = (1.0/32768.0)
CHANNELS = 2
self.RATE = 44100
INPUT_BLOCK_TIME = .20
self.INPUT_FRAMES_PER_BLOCK = int(self.RATE*INPUT_BLOCK_TIME)
WAVFILE = "test.wav"
print "Initializing sonar object..."
#Load chirp wavefile
self.wf = wave.open(WAVFILE, 'rb')
#init pyaudio
self.pa = pyaudio.PyAudio()
#identify mic device
self.device_index = None
for i in range( self.pa.get_device_count() ):
devinfo = self.pa.get_device_info_by_index(i)
print( "Device %d: %s"%(i,devinfo["name"]) )
for keyword in ["mic","input"]:
if keyword in devinfo["name"].lower():
print( "Found an input: device %d - %s"%(i,devinfo["name"]) )
self.device_index = 1 # I selected a specific mic - I needed the USB mic. You can select an input device from the list that prints.
if self.device_index == None:
print( "No preferred input found; using default input device." )
# open output stream using callback
self.stream = self.pa.open(format=self.pa.get_format_from_width(self.wf.getsampwidth()),
channels=self.wf.getnchannels(),
rate=self.wf.getframerate(),
output=True,
stream_callback=self.callback)
notNormalized = []
self.chirp = []
#read in chirp wav file to correlate against
srate, notNormalized = scipy.io.wavfile.read(WAVFILE)
for sample in notNormalized:
# sample is a signed short in +/- 32768.
# normalize it to 1.0
n = sample * self.SHORT_NORMALIZE
self.chirp.append(n)
def ping(self):
#send ping of sound
#set up input stream
self.istream = self.pa.open( format = self.FORMAT,
channels = 1, #The USB mic is only mono
rate = self.RATE,
input = True,
input_device_index = self.device_index,
frames_per_buffer = self.INPUT_FRAMES_PER_BLOCK)
# start the stream
self.stream.start_stream()
# wait for stream to finish
while self.stream.is_active():
pass
self.stream.stop_stream()
#reset wave file for next ping
self.wf.rewind()
def listen(self):
#record a sort section of sound to record the returned echo
self.samples = []
try:
block = self.istream.read(self.INPUT_FRAMES_PER_BLOCK)
except (IOError) as e:
# Something bad happened during recording
print( "(%d) Error recording: %s"%(self.errorcount,e) )
count = len(block)/2
format = "%dh"%(count)
shorts = struct.unpack( format, block )
for sample in shorts:
# sample is a signed short in +/- 32768.
# normalize it to 1.0
n = sample * self.SHORT_NORMALIZE
self.samples.append(n)
self.istream.close()
#Uncomment these lines to graph the samples. Useful for debugging.
#matplotlib.pyplot.plot(self.samples)
#matplotlib.pyplot.show()
def correlate(self):
#perform correlation by multiplying the signal by the chirp, then shifting over one sample and doing it again. Highest peaks correspond to best matches of original signal.
#Highest peak will be when the mic picks up the speaker sending the pings. Then secondary peaks represent echoes.
#my audio system has a significant delay between when you send audio and when it plays. As such, we send the wav, start recording, and get a large number of
#samples before we hear the ping. That just slows correlation down, so we remove it. This probably requires tuning between different systems. Safest, but slowest, is zero.
junkThreshold = 5000
self.samples = self.samples[junkThreshold:]
self.result = []
for offset in range(0, len(self.samples)-len(self.chirp)):
temp = 0
for a in range(0, len(self.chirp)):
temp = temp + (self.chirp[a] * self.samples[a + offset])
self.result.append(temp)
def clip(self):
#highest peak is the primary pulse. We don't need the audio before that, or the chirp itself. Strip it + chirpLength off. Remaining highest peaks are echoes.
largest = 0
peak1 = 0
for c in range(len(self.result)):
if (self.result[c] > largest):
largest = self.result[c]
peak1 = c
self.result = self.result[peak1:]
return self.result
#main control code
#initialize sonar and display
sonar = Sonar()
display = SonarDisplay()
screenHeight = display.getHeight()
screenWidth = display.getWidth()
screenBlockSize = display.getBlockSize() #size of each row in pixels
#each ping results in an array of correlated values with peaks corresponding to the time that echoes were recieved.
#send pings until we have reached the bottom of the display. An improvement would be to add scrolling.
y = 0
for a in range(0,screenHeight-screenBlockSize,screenBlockSize):
sonar.ping()
sonar.listen()
sonar.correlate()
result = sonar.clip()
display.plotLine(result, y)
y = y + screenBlockSize