Наука о данных с нуля
Основы: KNN для классификации и регрессии
Интуиция в том, как работают модели KNN
Курсы по науке о данных или прикладной статистике обычно начинаются с линейных моделей, но в своем роде K-ближайших соседей, вероятно, концептуально является самой простой широко используемой моделью. На самом деле модели KNN - это просто техническая реализация общей интуиции, что вещи, имеющие схожие черты, обычно похожи. Вряд ли это глубокое понимание, но эти практические реализации могут быть чрезвычайно мощными и, что особенно важно для тех, кто приближается к неизвестному набору данных, могут обрабатывать нелинейности без какой-либо сложной инженерии данных или настройки модели.
Что
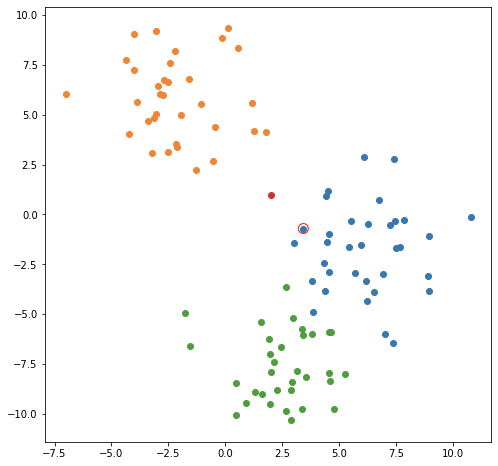
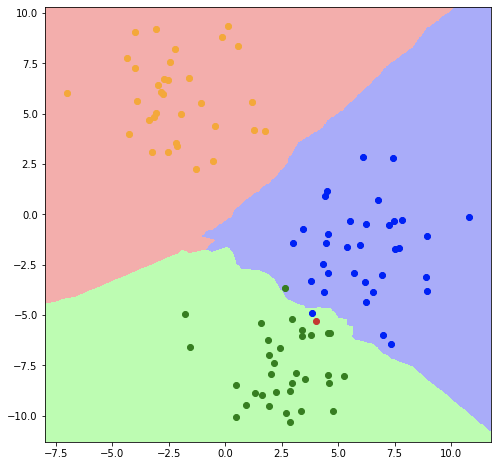
В качестве наглядного примера рассмотрим простейший случай использования модели KNN в качестве классификатора. Допустим, у вас есть точки данных, которые попадают в один из трех классов. Двумерный пример может выглядеть так:

Вероятно, вы можете довольно ясно видеть, что разные классы сгруппированы вместе - верхний левый угол графиков, кажется, принадлежит оранжевому классу, а правая / средняя часть - синему классу. Если бы вам дали координаты новой точки где-нибудь на графике и спросили, к какому классу она могла бы принадлежать, в большинстве случаев ответ был бы довольно ясным. Любая точка в верхнем левом углу графика может быть оранжевой и т. Д.
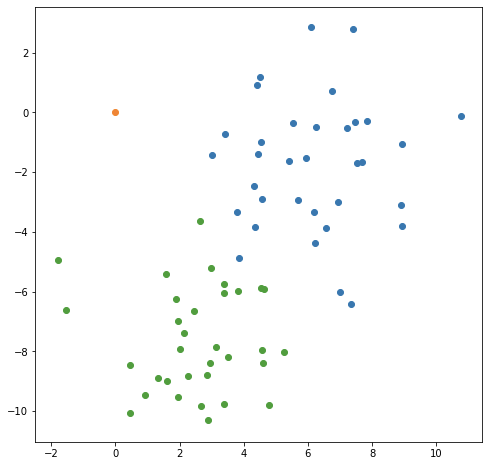
Однако задача становится немного менее определенной между классами, когда нам нужно остановиться на границе решения. Рассмотрим новую точку, добавленную красным ниже:

Следует ли классифицировать эту новую точку как оранжевую или синюю? Кажется, что точка находится между двумя кластерами. Ваша первая интуиция может заключаться в выборе кластера, который находится ближе к новой точке. Это будет подход «ближайшего соседа», и, несмотря на его концептуальную простоту, он часто дает довольно разумные прогнозы. К какой ранее определенной точке ближайшая новая точка? Может показаться неочевидным, просто глядя на график, каков ответ, но компьютер легко перебирает точки и дает нам ответ:
Похоже, что ближайшая точка находится в синей категории, так что наша новая точка, вероятно, тоже. Это метод ближайшего соседа.
В этот момент вам может быть интересно, для чего нужен «k» в k-ближайших соседях. K - количество ближайших точек, на которые модель будет смотреть при оценке новой точки. В нашем простейшем примере с ближайшим соседом это значение k было просто 1 - мы смотрели на ближайшего соседа, и все. Однако вы могли выбрать ближайшие 2 или 3 точки. Почему это важно и зачем кому-то устанавливать k на большее число? Во-первых, границы между классами могут возникать рядом друг с другом, делая менее очевидным, что ближайшая точка даст нам правильную классификацию. Рассмотрим синий и зеленый регионы в нашем примере. На самом деле, давайте увеличим их:
Обратите внимание: хотя общие области кажутся достаточно различимыми, их границы кажутся немного переплетенными друг с другом. Это обычная особенность наборов данных с небольшим шумом. В этом случае становится труднее классифицировать предметы в пограничных областях. Рассмотрим этот новый момент:

С одной стороны, визуально это определенно выглядит так, будто ближайшая ранее идентифицированная точка синего цвета, что наш компьютер может легко нам подтвердить:

С другой стороны, эта ближайшая синяя точка сама по себе кажется чем-то вроде выброса, далеко от центра синей области и как бы окружена зелеными точками. И эта новая точка находится даже за пределами этой синей точки! Что, если бы мы посмотрели на три ближайшие точки к новой красной точке?
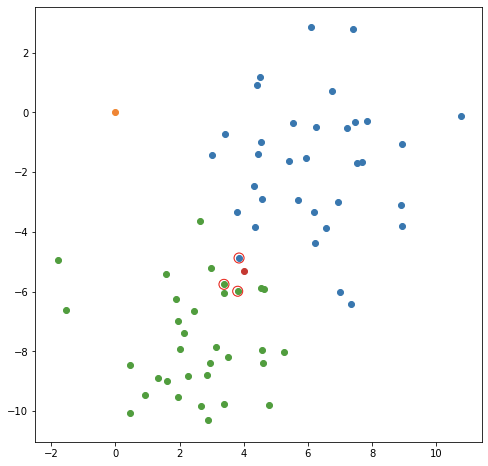
Или даже ближайшие пять пунктов к новой точке?
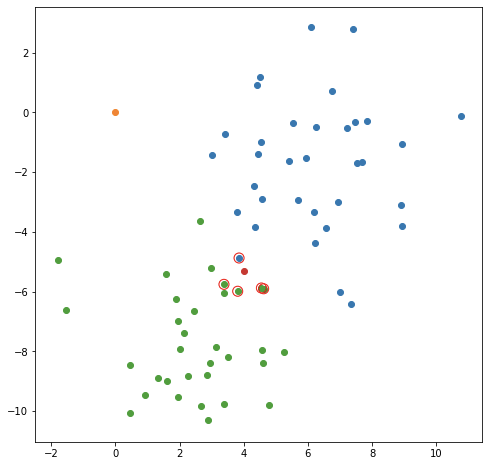
Теперь кажется, что наша новая точка находится в зеленом районе! Так получилось, что рядом есть синяя точка, но преобладание или близлежащие точки зеленые. В этом случае, возможно, имеет смысл установить более высокое значение для k, посмотреть на несколько ближайших точек и заставить их как-то проголосовать за прогноз для новой точки.
Проиллюстрированная проблема слишком уместна. Когда k установлено в единицу, граница между областями, которые определяются алгоритмом как синий и зеленый, неровная, она изгибается назад с каждой отдельной точкой. Красная точка выглядит так, как будто она может быть в синей области:

Однако доведение k до 5 сглаживает границу принятия решения, поскольку разные соседние точки голосуют. Красная точка теперь кажется твердо стоящей в зеленом районе:
Компромисс с более высокими значениями k - это потеря детализации границы принятия решения. Установка очень высокого k даст вам гладкие границы, но границы реального мира, которые вы пытаетесь смоделировать, могут быть не идеально гладкими.
Фактически, мы можем использовать тот же подход ближайших соседей для регрессий, когда нам нужна индивидуальная ценность, а не классификация. Рассмотрим следующую регрессию ниже:

Данные были сгенерированы случайным образом, но были сгенерированы как линейные, поэтому модель линейной регрессии, естественно, хорошо соответствовала бы этим данным. Однако я хочу отметить, что вы можете аппроксимировать результаты линейного метода концептуально более простым способом с помощью подхода K-ближайших соседей. Наша «регрессия» в этом случае будет не единственной формулой, которую дает нам модель OLS, а скорее наилучшим прогнозируемым выходным значением для любого заданного входа. Рассмотрим значение -75 по оси x, которое я пометил вертикальной линией:

Не решая никаких уравнений, мы можем прийти к разумному приближению того, каким должен быть результат, просто рассматривая близлежащие точки:

Имеет смысл, что прогнозируемое значение должно быть около этих точек, не намного ниже или выше. Возможно, хорошим прогнозом будет среднее значение этих баллов:

Вы можете себе представить, что делаете это для всех возможных входных значений и везде делаете прогнозы:

Соединение всех этих прогнозов линией дает нам регрессию:

В этом случае результаты не являются четкой линией, но они достаточно хорошо прослеживают восходящий наклон данных. Это может показаться не очень впечатляющим, но одним из преимуществ простоты этой реализации является то, что она хорошо справляется с нелинейностью. Рассмотрим этот новый набор очков:
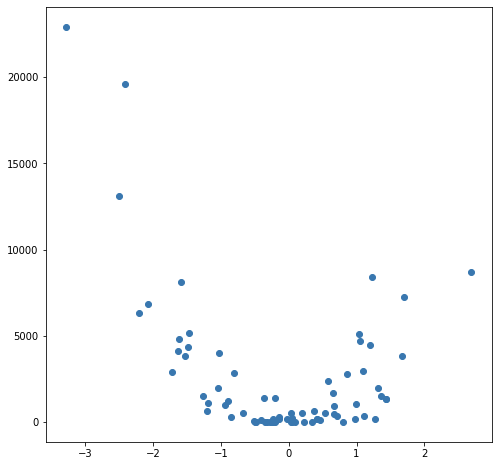
Эти точки были получены путем простого возведения в квадрат значений из предыдущего примера, но предположим, что вы наткнулись на такой набор данных в естественных условиях. Очевидно, что она не является линейной по своей природе, и хотя модель в стиле OLS может легко обрабатывать данные такого рода, она требует использования нелинейных терминов или терминов взаимодействия, что означает, что специалист по данным должен принять некоторые решения о том, какой вид инженерии данных выполнять. Подход KNN не требует дополнительных решений - тот же код, который я использовал в линейном примере, можно полностью повторно использовать для новых данных, чтобы получить работоспособный набор прогнозов:

Как и в примерах с классификатором, установка более высокого значения k помогает нам избежать переобучения, хотя вы можете начать терять предсказательную способность по марже, особенно по краям вашего набора данных. Рассмотрим первый пример набора данных с прогнозами, сделанными с k, равным единице, то есть подходом ближайшего соседа:
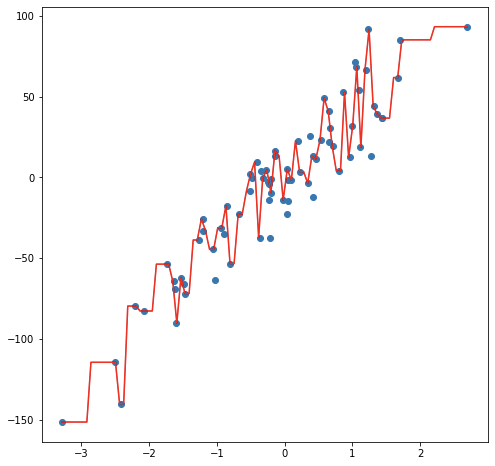
Наши прогнозы хаотично скачут по мере того, как модель перескакивает от одной точки набора данных к другой. Напротив, установка k равной десяти, так что десять общих точек усредняются вместе для прогнозирования, дает гораздо более плавную поездку:

Как правило, это выглядит лучше, но вы можете увидеть некоторую проблему на краях данных. Поскольку наша модель учитывает так много точек для любого данного прогноза, когда мы приближаемся к одному из краев нашей выборки, наши прогнозы начинают ухудшаться. Мы можем в некоторой степени решить эту проблему, взвешивая наши прогнозы в сторону более близких моментов, хотя это имеет свои собственные компромиссы.
Как
При настройке модели KNN необходимо выбрать / настроить только несколько параметров для повышения производительности.
K: количество соседей: как обсуждалось, увеличение K будет иметь тенденцию сглаживать границы принятия решения, избегая переобучения за счет некоторого разрешения. Не существует единственного значения k, которое подходило бы для каждого отдельного набора данных. Для моделей классификации, особенно если есть только два класса, для k обычно выбирается нечетное число. Это сделано для того, чтобы алгоритм никогда не сталкивался с «ничьей»: например, он смотрит на ближайшие четыре точки и обнаруживает, что две из них относятся к синей категории, а две - к красной.
Показатель расстояния. Оказывается, существуют разные способы измерить, насколько «близки» две точки друг к другу, и различия между этими методами могут стать значительными в более высоких измерениях. Чаще всего используется евклидово расстояние, стандартная сортировка, которую вы, возможно, выучили в средней школе с помощью теоремы Пифагора. Другой показатель - это так называемое «манхэттенское расстояние», которое измеряет расстояние, пройденное в каждом направлении света, а не по диагонали (как если бы вы шли от одного перекрестка улиц Манхэттена к другому и должны были следовать по сетке улиц, а не по диагонали). может выбрать самый короткий маршрут "по прямой"). В более общем смысле, это на самом деле обе формы так называемого «расстояния Минковского», формула которого такова:

Когда p установлено в 1, эта формула совпадает с манхэттенским расстоянием, а когда установлено в два, с евклидовым расстоянием.
Веса. Один из способов решить как проблему возможной «ничьей», когда алгоритм голосует за класс, так и проблему, когда наши прогнозы регрессии ухудшались по направлению к краям набора данных, - это введение взвешивания. При использовании весов ближайшие точки будут учитываться больше, чем более удаленные. Алгоритм по-прежнему будет рассматривать всех k ближайших соседей, но более близкие соседи будут иметь больше голосов, чем те, которые находятся дальше. Это не идеальное решение и снова возникает возможность переобучения. Рассмотрим наш пример регрессии, на этот раз с весами:

Наши прогнозы сейчас идут прямо к краю набора данных, но вы можете видеть, что наши прогнозы теперь намного ближе к отдельным точкам. Взвешенный метод работает достаточно хорошо, когда вы находитесь между точками, но по мере того, как вы приближаетесь к любой конкретной точке, значение этой точки все больше и больше влияет на предсказание алгоритма. Если вы подойдете достаточно близко к точке, это почти как установить k равным единице, поскольку эта точка имеет огромное влияние.
Масштабирование / нормализация. Последний, но очень важный момент заключается в том, что модели KNN могут быть отброшены, если разные переменные характеристик имеют очень разные масштабы. Рассмотрим модель, которая пытается предсказать, скажем, цену продажи дома на рынке на основе таких характеристик, как количество спален, общая площадь дома в квадратных футах и т. Д. дома, чем количество спален. Обычно в домах всего несколько спален, и даже в самом большом особняке не будет десятков или сотен спален. Квадратные футы, с другой стороны, относительно малы, поэтому дома могут варьироваться от, скажем, 1000 квадратных футов на маленькой стороне до десятков тысяч квадратных футов на большой стороне.
Рассмотрим сравнение между домом площадью 2000 кв. Футов с 2 спальнями и домом площадью 2 000 кв. Футов с двумя спальнями - 10 кв. Футов вряд ли имеют значение. Напротив, дом площадью 2000 квадратных футов с тремя спальнями очень отличается и представляет собой совсем другую и, возможно, более тесную планировку. Однако у наивного компьютера не было бы контекста, чтобы это понять. Можно сказать, что 3 спальни находятся всего в «одной» единице от 2-х спален, в то время как нижний колонтитул 2010 кв. Чтобы избежать этого, данные функций следует масштабировать перед реализацией модели KNN.
Сильные и слабые стороны
Модели KNN легко реализовать и хорошо справляются с нелинейностями. Подбор модели также обычно бывает быстрым: в конце концов, компьютеру не нужно вычислять какие-либо конкретные параметры или значения. Компромисс здесь заключается в том, что, хотя модель быстро настраивается, ее медленнее прогнозировать, поскольку для того, чтобы предсказать результат для нового значения, ей потребуется выполнить поиск по всем точкам в ее обучающем наборе, чтобы найти ближайшие. . Поэтому для больших наборов данных KNN может быть относительно медленным методом по сравнению с другими регрессиями, которые могут занять больше времени, чтобы соответствовать, но затем делают свои прогнозы с относительно простыми вычислениями.
Еще одна проблема с моделью KNN заключается в том, что ей не хватает интерпретируемости. Линейная регрессия OLS будет иметь четко интерпретируемые коэффициенты, которые сами могут дать некоторое представление о «величине эффекта» данной особенности (хотя при назначении причинности следует соблюдать некоторую осторожность). Однако спрашивать, какие функции имеют наибольший эффект, для модели KNN не имеет смысла. Частично из-за этого модели KNN также нельзя использовать для выбора функций, как это может быть линейная регрессия с добавленным термином функции стоимости, например гребень или лассо, или как дерево решений неявно выбирает, какой функции кажутся наиболее ценными.