
В этом блоге я собираюсь поделиться своим мыслительным процессом, который привел меня к тому, что я получил 35 место среди 6456 участников (в частной таблице лидеров).
Оглавление
- Введение
- Постановка задачи
- Задача
- Набор данных
- Визуализация данных
- Объединение данных
- Знай свои особенности
- Отсутствующие данные
- Слияние поездов, тестов и выводов.
- Найти счетчики
- Функция Datetime
- Удаление дубликата
- Модель обучения
- Ссылка
Введение
Этот хакатон был запущен WNS (Holdings) Limited (NYSE: WNS), ведущей компанией по управлению бизнес-процессами (BPM) в Analytics Vidhya. Подробнее о хакатоне можно прочитать здесь.
Zbay - это веб-сайт электронной коммерции, который продает различные продукты на своей онлайн-платформе. Zbay записывает поведение своих клиентов и сохраняет его в виде журнала. Однако в большинстве случаев пользователи не покупают продукты мгновенно, и существует временной промежуток, в течение которого покупатель может путешествовать по Интернету и, возможно, посещать веб-сайты конкурентов.
Теперь, чтобы улучшить продажи продуктов, Zbay нанял Adiza, компанию Adtech, которая построила систему, позволяющую показывать рекламу продуктов Zbay на сайтах партнеров.
Если пользователь заходит на веб-сайт Zbay и ищет продукт, а затем посещает эти партнерские веб-сайты или приложения, его / ее ранее просмотренные товары или аналогичные им товары отображаются в виде рекламы. Если пользователь нажимает на это объявление, он будет перенаправлен на веб-сайт Zbay и может купить продукт.

Задача
Задача состоит в том, чтобы спрогнозировать вероятность клика, то есть вероятность того, что пользователь нажмет на рекламу, которая отображается ему на партнерских сайтах в течение следующих 7 дней, на основе данных журнала просмотра истории, данных о показах рекламы и данных пользователя.
Набор данных
Набор данных был предоставлен в 4 файлах csv, определенных ниже
а.) Данные журнала
Он состоит из 3118622 строк и 5 столбцов.

где каждый столбец имеет собственное значение, как определено на изображении ниже.

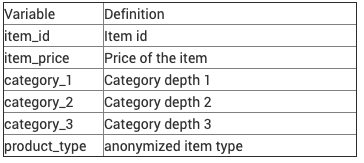
б.) данные о показах объявлений
Он состоит из 132761 строки и 6 столбцов.

где каждый столбец имеет собственное значение, как определено на изображении ниже.
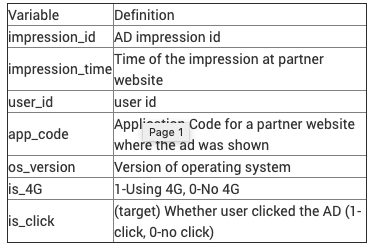
c.) данные о поездах
Он состоит из 237609 строк и 7 столбцов.

где каждый столбец имеет собственное значение, как определено на изображении ниже.
г.) тестовые данные
Он состоит из 90675 строк и 6 столбцов.

и значение каждого столбца такое же, как у поезда.
Визуализация данных
а.) статистика данных о поездах.
Это не дало никакой полезной информации

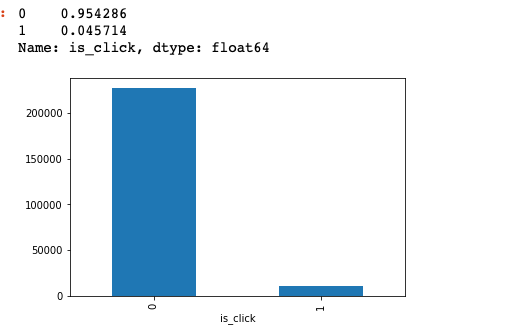
б) визуализация клика, а не клика.
визуализировав общее количество кликов, я обнаружил, что этот набор данных сильно несбалансирован. Процент not_click превышает 95%, что также верно, потому что все, что мы встречаем ежедневно на YouTube или на другой платформе, мы склонны пропускать.
Объединение данных
Так как только работа с обучающими и тестовыми данными может дать оценку auc более 0,70 в тестовых данных, это означает, что рейтинг ниже 200 в таблице лидеров. Но объединение файлов csv - это то, что меняет игру.
Мы можем объединить фрейм данных поезда и журнала на user_id, но убедитесь, что вы поставили how = «left» или «right», потому что в противном случае могут игнорироваться некоторые строки данных поезда, которые могут играть важную роль во время обучения.
После объединения поезда и журнала следующим шагом будет объединение данных поезда и показа рекламы для item_id и how = «left» или «right».
ite = pd.merge(train, view_log, on='user_id', how="left") train_data = pd.merge(ite, item, on="item_id", how="left") train_data.shape
Точно так же мы можем объединить тест, журнал и показ рекламы, как описано выше.
Но при слиянии итоговые данные train_data приобретают форму (11052882,16), что является очень большим числом.
И test_data приобретает форму (3871697,15). Это тоже большое число.
Знайте свои особенности
Как только мы внимательно рассмотрим наш набор данных, мы обнаружим, что все функции являются категориальными по своей природе.
Мы можем визуализировать это, как показано ниже
session_id
'''
Taking into account just the CLICKS
'''
session_df = pd.DataFrame()
session_df['pos_clicks'] = train_data[['session_id','is_click']].groupby(['session_id']).count().reset_index().sort_values('is_click',ascending=False)['is_click']
session_df

app_code
'''
Taking into account just the CLICKS
'''
app_df = pd.DataFrame()
app_df['pos_clicks'] = train_data[['app_code','is_click']].groupby(['app_code']).count().reset_index().sort_values('is_click',ascending=False)['is_click']
app_df

Вы даже можете попробовать диаграмму для визуализации.
Аналогичным образом мы можем поступить и с другими функциями.
Отсутствующие данные
Теперь мы можем проверить, сколько категорий есть в данных поезда, но не в тестовых данных.
os_version
test_data["os_version"].isin(train_data["os_version"]).value_counts()

мы видим, что вся тестируемая версия os_version также присутствует в данных поезда.
app_code
test_data["app_code"].isin(train_data["app_code"]).value_counts()

Здесь в тестовых данных присутствует 1485 новых категорий app_code.
Но имейте в виду, что эта визуализация выполняется для всех объединенных данных, которые также содержат несколько повторяющихся строк.
Для фактического отсутствующего значения вы можете удалить все повторяющиеся строки, при этом вы увидите, что только 55 дополнительных категорий app_data присутствуют в тесте, который не находится в обучении.
Объединение поезда, теста и заключения
Отсюда мы также можем генерировать дополнительные функции из обучения и тестирования отдельно.
Сначала я попытался подсчитать все функции, а затем, наконец, объединил на тренировке и тестировании отдельно. Но это не сработало, потому что количество, генерируемое поездом и тестом, не имело отношения, поэтому модель хорошо предсказывала данные обучения и проверки, но резко провалила тестовые данные.
Позже я удалил метку («is_click») с train и объединил train_data и test_data как один фрейм данных.
train_data = pd.concat([train_data,test_data])
Подсчет количества
Теперь, чтобы создать некоторые новые функции, я подсчитал все категориальные функции. Мы можем провести подсчет, удалив все дубликаты и сохранив все дубликаты. После удаления всех дубликатов модель показала себя лучше, но не совсем так, как ожидалось. Поэтому я провел подсчет всех повторяющихся значений, и модель показала себя очень хорошо.
#impression
train_1= train_data.groupby(train_data.impression_id).agg({"impression_id":["count"]})["impression_id"].reset_index()
train_data = pd.merge(train_data, train_1, on="impression_id", how="left")
print(train_data.shape)
#app_code
train_1= train_data.groupby(train_data.app_code).agg({"app_code":["count"]})["app_code"].reset_index()
train_data = pd.merge(train_data, train_1, on="app_code", how="left", suffixes=("_1", '_12'))
print(train_data.shape)
Во всех подсчетах наибольшее значение имеет счетчик impression_id.
Одна вещь, которую я понял при слиянии, заключается в том, что все значения дублируются по отношению к определенной функции, но в целом каждая строка была уникальной.
Функция даты и времени
Я преобразовал server_time и impression_time в datetime и извлек из него день, час, неделю. Хотя я обнаружил, что функции Server_time более важны, чем функции impression_time.
#converting to date time format import datetime train_data["impression_time"] = pd.to_datetime(train_data["impression_time"]) train_data["server_time"] = pd.to_datetime(train_data["server_time"]) #Extracting features train_data['hour_imp'] = pd.DatetimeIndex(train_data['impression_time']).hour train_data['hour_ser'] = pd.DatetimeIndex(train_data['server_time']).hour train_data['day_week_ser'] = pd.DatetimeIndex(train_data['server_time']).dayofweek train_data['day_week_imp'] = pd.DatetimeIndex(train_data['impression_time']).dayofweek
Вы также можете визуализировать дату и время, как указано выше.
Разница в минутах сервера и времени показа тоже была важной особенностью.
train_data["diff"] = abs((train_data["hour_imp"]-train_data["hour_ser"]))*60
Теперь мы можем подсчитать количество и для этих функций, а затем объединить его в окончательный CSV.
Мы можем создать еще несколько функций для разделения количества показов на количество показов.
Удаление дубликата
Теперь заполните все значения nan нулями и удалите дубликат на основе идентификатора отпечатка.
train_data.drop_duplicates(subset=["impression_id"], keep="first", inplace=True)
Откажитесь от этих функций, потому что они мало помогли в прогнозировании.
train_data.drop(['impression_id', "impression_time", "server_time", "device_type", "noon_ser", "noon_imp", "os_version"], axis=1, inplace=True)
Модель обучения
Теперь мы можем разделить данные на обучение и тестирование и передать их в Catboost Regressor.
#modelstart= time.time()
cb_model = CatBoostRegressor(iterations=1000,
learning_rate=0.02,
depth=12,
eval_metric='AUC',
random_seed = 23,
bagging_temperature = 0.2,
od_type='Iter',
metric_period = 75,
od_wait=100)
cb_model.fit(X_train, y_train,
eval_set=(X_valid,y_valid),
cat_features=categorical_var,
use_best_model=True,
verbose=True)

С этой моделью мой AUC достигает 0,7487 в тестовых данных.
Затем я обучил модель с помощью lightgbm с той же структурой.
auc с lightgbm было 0,7455.
Затем я суммирую предсказания обеих моделей с некоторым соотношением и получаю окончательные данные тестирования, равные 0,7533026.
Это все, что я сделал.
Надеюсь, вам понравился этот блог. Я скоро обновлю это в моем github и предоставлю ссылку для загрузки всего кода.
Спасибо за чтение.
Ссылки
1.) https://datahack.analyticsvidhya.com/contest/wns-analytics-wizard-2019/