Определение проекта:
В банках огромные данные фиксируют информацию о своих клиентах. Эти данные могут использоваться для создания и поддержания четких отношений и связи с клиентами, чтобы нацеливать их индивидуально на определенные продукты или банковские предложения. Обычно с выбранными клиентами связываются напрямую через: личный контакт, телефон, сотовую связь, почту и электронную почту или любые другие контакты для рекламы нового продукта / услуги или предложения, этот вид маркетинга называется прямым маркетингом. Фактически, прямой маркетинг - это в основном стратегия многих банков и страховых компаний по взаимодействию со своими клиентами.
Постановка проблемы:
Все маркетинговые кампании банка зависят от огромных электронных данных клиентов. Размер этих источников данных не позволяет аналитику-человеку получить интересную информацию, которая поможет в процессе принятия решений. Модели интеллектуального анализа данных полностью помогают в проведении этих кампаний. Цель состоит в повышении эффективности кампании за счет определения основных характеристик, влияющих на успех, на основе нескольких алгоритмов, которые мы будем тестировать (например, логистическая регрессия, случайные леса, деревья решений и другие). С помощью экспериментальных результатов мы продемонстрируем производительность моделей с помощью статистических показателей, таких как точность, чувствительность, точность, отзывчивость и т. Д. При более высокой оценке этих показателей мы сможем судить об успехе этих моделей в прогнозировании лучшей кампании. связаться с клиентами для подписки на депозит. Целью маркетинговой кампании было побудить клиентов подписаться на продукт срочного банковского вклада. Сделали они это или нет - это переменная «y» в наборе данных. Рассматриваемый банк рассматривает, как оптимизировать эту кампанию в будущем.
Показатели:
Предлагаемые метрики оценки соответствуют контексту данных, постановке проблемы и предполагаемому решению. Эффективность каждой модели классификации оценивается с использованием трех статистических показателей: точность классификации, чувствительность и специфичность. Он использует истинно положительный (TP), истинно отрицательный (TN), ложноположительный (FP) и ложноотрицательный (FN). Процент правильной / неправильной классификации - это разница между фактическими и прогнозируемыми значениями переменных. Истинно-положительный (TP) - это количество правильных прогнозов того, что экземпляр является истинным, или другими словами; это происходит, когда положительный прогноз классификатора совпал с положительным прогнозом целевого атрибута. Истинно-отрицательный (TN) представляет собой ряд правильных прогнозов о том, что экземпляр является ложным (т. Е.), Когда и классификатор, и целевой атрибут предполагают отсутствие положительного прогноза. Ложноположительный результат (FP) - это количество неверных прогнозов, что экземпляр является истинным. Наконец, ложноотрицательный (FN) - это количество неверных прогнозов о том, что экземпляр является ложным.
Точность классификации определяется как отношение количества правильно классифицированных случаев и равна сумме TP и TN, деленной на общее количество случаев (TN + FN + TP + FP).

Точность определяется как количество истинных положительных результатов (TP) по сравнению с количеством истинных положительных результатов плюс количество ложных срабатываний (FP).
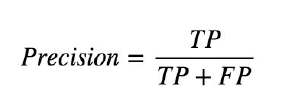
Отзыв определяется как количество истинных положительных результатов (TP) по сравнению с количеством истинных положительных результатов плюс количество ложных отрицательных результатов (FN).

Чувствительность относится к количеству правильно классифицированных положительных результатов и равна TP, деленному на сумму TP и FN. Чувствительность можно назвать истинно положительным показателем.

Специфичность относится к количеству правильно классифицированных негатива и равна отношению TN к сумме TN и FP.

Анализ:
Исследование данных:
Эти данные связаны с кампаниями прямого маркетинга португальского банковского учреждения. Маркетинговые кампании основывались на телефонных звонках. Часто требовалось более одного контакта с одним и тем же клиентом, чтобы получить доступ, будет ли продукт (срочный банковский депозит) подписан («да») или нет («нет»). Цель классификации - предсказать, подпишется ли клиент (да / нет) на срочный депозит (переменная y).
1. возраст (числовой)
2. работа: тип работы (категориальная:
"админ", "синий воротничок", "предприниматель", "домработница", "менеджмент", "пенсионер", "самозанятый", "услуги", "студент", "техник", "безработный", " неизвестный')
3. замужем: семейное положение (категориальное: «разведен», «женат», «холост», «неизвестен»; примечание: «разведен» означает разведенный или вдовец)
4. образование (категориальные: "basic.4y", "basic.6y", "basic.9y", "high.school", "неграмотный", "professional.course", "university.degree", "unknown")
5. дефолт: есть кредит в дефолте? (категорично: «нет», «да», «неизвестно»)
6. Жилье: есть жилищный кредит? (категорично: «нет», «да», «неизвестно»)
7. Кредит: есть ли личный кредит? (категорично: «нет», «да», «неизвестно»)
8. контакт: контактный вид связи (категориальный: «сотовый», «телефон»).
9. month: месяц последнего контакта в году (категориальные: «jan», «feb», «mar»,…, «nov», «dec»).
10. day_of_week: последний контактный день недели (категориальный: «пн», «вт», «ср», «чт», «пт»)
11. Продолжительность: продолжительность последнего контакта в секундах (числовое значение). Важное примечание: этот атрибут сильно влияет на цель вывода (например, если длительность = 0, то y = ’no’). Тем не менее, продолжительность вызова до выполнения вызова неизвестна. Кроме того, после окончания звонка, очевидно, известно y. Таким образом, эти входные данные следует включать только для целей эталонного тестирования и от них следует отказаться, если предполагается получить реалистичную прогностическую модель.
12. Кампания: количество контактов, выполненных во время этой кампании и для этого клиента (числовое, включая последний контакт).
13. pdays: количество дней, которые прошли после того, как с клиентом в последний раз связались из предыдущей кампании (число; 999 означает, что с клиентом ранее не связались).
14. предыдущий: количество контактов, выполненных до этой кампании и для этого клиента (числовое значение)
15. poutcome: результат предыдущей маркетинговой кампании (категоричный: «провал», «несуществующий», «успех»).
16. emp.var.rate: коэффициент вариации занятости - квартальный показатель (числовой)
17. cons.price.idx: индекс потребительских цен - месячный показатель (числовой)
18. cons.conf.idx: индекс потребительского доверия - месячный индикатор (числовой)
19. euribor3m: ставка euribor на 3 месяца - дневной индикатор (числовой)
20. Кол-во занятых: количество сотрудников - квартальный показатель (числовой)
Выходная переменная (желаемая цель):
- y - подписался ли клиент на срочный депозит? (двоичный: «да», «нет»)
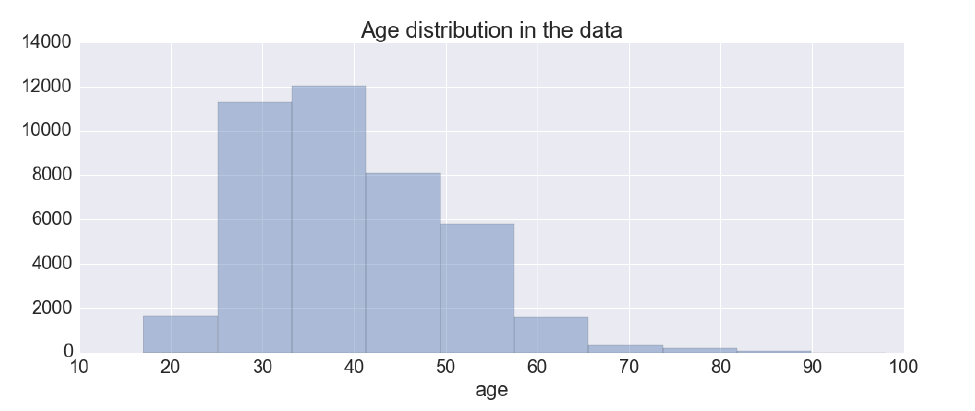
Набор данных состоит из 21 столбца и 41188 строк с 20 функциями и одной переменной ответа. Количество клиентов, которые подписались, составляет 4640, а количество клиентов, которые не подписались, - 36548. Исходя из этого, процент ответов клиентов составляет около 11,27%, что делает набор данных очень несбалансированным. На рисунке показано возрастное распределение в данных, это нормальное распределение с небольшим левым перекосом. Это намекает на то, что большинство ответов относится к возрастной группе 25–40 лет.
Ниже приведена тепловая карта, показывающая взаимосвязь между различными переменными:

Алгоритмы и методы:
Дерево решений - это надежная и прозрачная модель машинного обучения. Дерево начинается с одного узла, а затем разветвляется, и решение принимается в каждой точке ветвления. Его можно использовать для прогнозирования того, имела ли значение конкретная переменная для решения клиента о подписке на срочный депозит банка. Данный набор данных представляет собой типичную проблему контролируемого обучения, для которой модели древовидного типа работают намного лучше, чем остальные. Мы не знаем, какие алгоритмы подходят для этой проблемы или какие конфигурации использовать. Итак, давайте выберем несколько алгоритмов для оценки.
Логистическая регрессия (LR): это подходящий регрессионный анализ, который следует проводить, когда зависимая переменная является дихотомической (бинарной).
Деревья классификации и регрессии (CART): алгоритм CART структурирован как последовательность вопросов, ответы на которые определяют следующий вопрос, если таковой должен быть. Результатом этих вопросов является древовидная структура, концы которой являются конечными узлами, в которой больше нет вопросов.
Деревья классификации: где целевая переменная является категориальной, а дерево используется для определения «класса», в который, вероятно, попадет целевая переменная.
Деревья регрессии: целевая переменная является непрерывной, а дерево используется для прогнозирования ее значения.
Случайные леса (RF): идея RF состоит в том, чтобы построить множество небольших деревьев, которые используют случайное подмножество функций, а затем объединить их в «лес» деревьев. Каждое дерево само по себе является слабым предиктором, но, комбинируя множество слабых предикторов, вы часто (но не всегда!) Можете получить более сильную модель.
Адаптивное ускорение (AB): AdaBoost - это тип «ансамблевого обучения», при котором несколько учащихся используются для создания более сильного алгоритма обучения. AdaBoost работает, выбирая базовый алгоритм (например, деревья решений) и итеративно улучшая его, учитывая неправильно классифицированные примеры в обучающем наборе.
Extreme Gradient Boost (XGB): идея, лежащая в основе GBM, более сложная. Грубо говоря, идея состоит в том, чтобы снова объединить слабые предикторы. Уловка состоит в том, чтобы найти области неправильной классификации, а затем «повысить» важность этих неправильно предсказанных точек данных. И повторить. В результате получается единое дерево в отличие от RF.
XGBoost - это модель, основанная на ансамбле деревьев, который представляет собой набор деревьев классификации и регрессии (CART). XGBoost классифицирует членов семьи по разным листам и присваивает баллы на соответствующем листе. Обычно одиночное дерево - это слабый опор, который недостаточно прочен для использования на практике. Растущие деревья, как правило, неглубокие, с высоким уровнем систематической ошибки и низкой дисперсией. Модель ансамбля деревьев суммирует предсказание нескольких деревьев. Ниже приведен пример ансамбля двух деревьев, который определяет, нравится ли кому-то играть в компьютерные игры.
Контрольная модель
В таблице ниже представлены характеристики различных моделей, которые были опробованы с учетом их точности и ошибок. Стандартная модель Extreme Gradient Boosting (XGB) с параметрами по умолчанию дает точность 91,4% для данных обучения. Поэтому буду считать это эталоном и попытаюсь превзойти эталон с помощью поворота гиперпараметров.

Предварительная обработка данных:
Мы подготовим данные, разделив столбцы функций и целей / меток, а также проверим качество предоставленных данных и проведем очистку данных. Чтобы проверить, хороша ли созданная мной модель, я разделю данные на наборы для обучения и проверки, чтобы проверить точность лучшей модели. Мы разделим данные «обучающие» данные на две части, 70% из которых будут использоваться для обучения наших моделей, а 30% мы сохраним в качестве «проверочного» набора. Есть несколько нечисловых столбцов, которые необходимо преобразовать. Многие из них просто да / нет, например Корпус. Их можно разумно преобразовать в значения 1/0 (двоичные). Другие столбцы, такие как профессия и семейное положение, имеют более двух значений и известны как категориальные переменные. Рекомендуемый способ обработки такого столбца - создать как можно больше столбцов, насколько это возможно (например, Professional_admin, Professional_blue-collar и т. Д.), И присвоить 1 одному из них и 0 всем остальным. Эти сгенерированные столбцы иногда называют фиктивными переменными, и мы будем использовать функцию pandas.get_dummies () для выполнения этого преобразования. Были выполнены несколько этапов предварительной обработки данных, таких как предварительная обработка столбцов функций, определение столбцов функций и целевых столбцов, очистка данных и создание разделов данных для обучения и проверки, на которые можно ссылаться для получения подробной информации в прилагаемой записной книжке jupyter.
Выполнение:
Проект следует типичной иерархии прогнозной аналитики, показанной на рис.

Следуя направлению стрелки, как показано, с выбранным набором данных мы сначала выполнили исследовательский анализ, увидев распределение некоторых функций, которые кажутся актуальными для проблемы, которую мы планируем решить. В этом процессе мы также проверили корреляции, используя матрицу рассеяния. Затем мы выполнили шаги по очистке данных, чтобы определить столбцы с наибольшим количеством нулевых значений и принять решение, хотим ли мы заполнить недостающие значения или полностью исключить столбцы из анализа. Мы обработали данные с помощью функции предварительной обработки, чтобы определить функции, которые имеют такие значения, как «да», «нет», «неизвестно», и преобразовали их в 1, 0, np.nan. Для категориальных функций мы преобразовали их в фиктивные переменные, чтобы набор данных стал полностью числовым, а затем его можно было легко обработать с помощью выбранного нами алгоритма для получения значимого результата. Прежде чем перейти к оценке модели, мы разбиваем наш полный набор данных на обучающие и проверочные разбиения с соотношением 70:30, а затем выполняем еще одну проверку, чтобы убедиться, что разбиения имеют равный процент ответов, чтобы избежать отклонений в итерациях классификации. Мы использовали древовидные алгоритмы для проверки точности и показателей стандартной ошибки, чтобы выбрать модель, которая работает лучше всего. Как правило, Random Forest и XGBoost, как известно, в лучшем случае работают в обычных контролируемых приложениях машинного обучения, и мы подтвердили это, заметив, что XGBoost действительно имеет высочайшую точность. Одним из ключевых наблюдений, которые мы сделали, было то, что точность оболочки XGBoost sklearn была лучше по сравнению с XGBoost из библиотеки dmlc. После того, как мы измерили точность ненастроенной модели XGBoost, мы затем выполнили настройку гиперпараметров модели XGBoost партиями с помощью GridSearchCV. Таким образом, мы могли отслеживать лучшие результаты каждого параметра и применять их к следующему пакету.
Уточнение:
Мы подготовим данные, разделив столбцы функций и целей / меток, а также проверим качество предоставленных данных и проведем очистку данных. Чтобы проверить, хороша ли созданная нами модель, мы разделим данные на наборы для обучения и проверки, чтобы проверить точность лучшей модели. Мы разделим данные обучающие данные на две части, 70% из которых будут использоваться для обучения наших моделей, а 30% мы отложим в качестве набора для проверки. Мы выполнили гипер-настройку параметров оболочки XGBoost из библиотеки scikit-learn.
Результаты
Оценка и проверка модели
Мы применили и сравнили XGB-модель прямо из коробки с остальными древовидными моделями. Используемые нами метрики рассчитываются с использованием оболочки sklearn, поэтому можно доверять производительности модели. Наша конечная цель состояла в том, чтобы получить настроенную модель, которая могла бы превзойти ненастроенный тест, что она и сделала, с очень большим отрывом. Таким образом, решение, описанное ниже, соответствует нашим первоначальным ожиданиям. Мы создали окончательную модель с указанным выше списком настроенных параметров. Точность этой настроенной модели примерно на 0,2% выше, чем у ненастроенной модели. Фрагмент кода окончательной модели показан ниже:
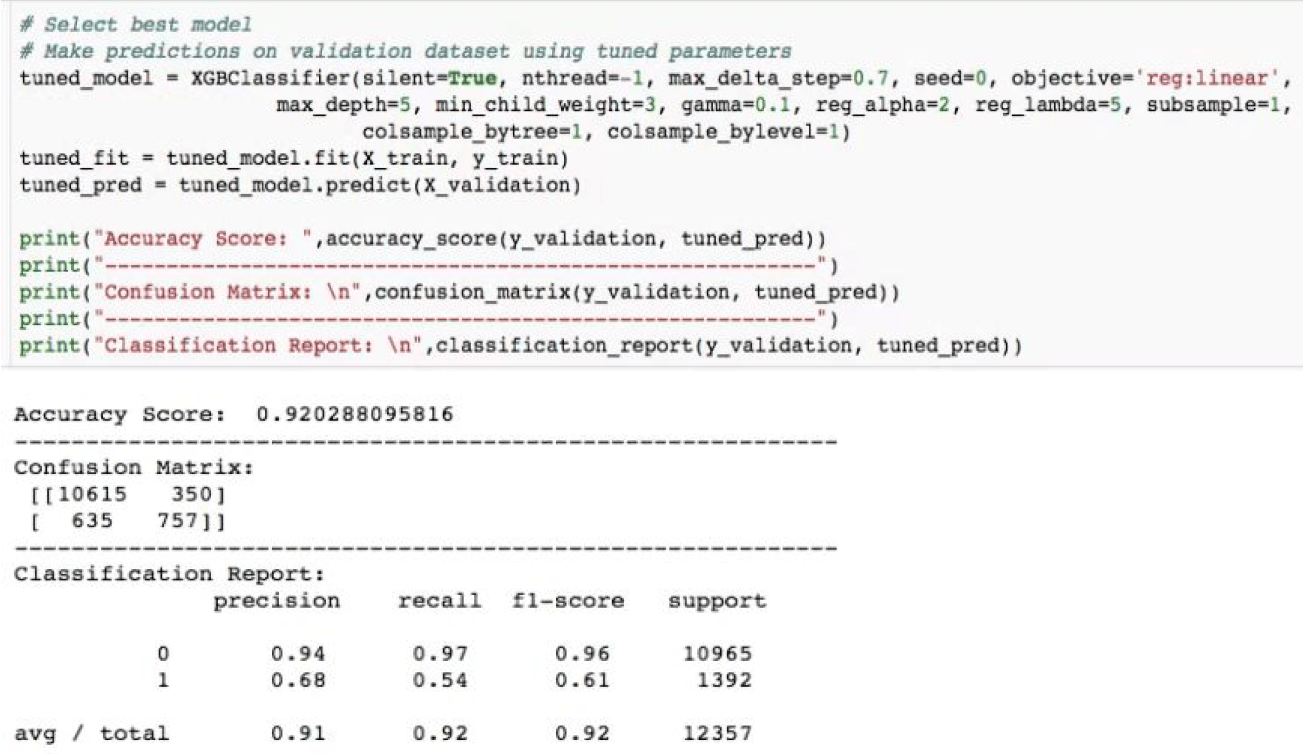
Скорость отзыва довольно низкая, как мы обсуждали в разделе выше. Это можно улучшить, придав положительным меткам «1» больший вес, что, в свою очередь, снижает общую точность, но производительность модели становится устойчивой для классификации меток результатов.
Обоснование
Окончательные результаты можно улучшить, настроенная окончательная модель не показала значительных улучшений по сравнению с ненастроенной моделью. Могло быть больше способов улучшить оценку, в частности, путем выбора подмножества функций с использованием ранжирования, полученного при наблюдении за ранжированием важности функций, а затем выполнения того же упражнения, которое мы проделали, как описано выше. Но пока это будет вне рамок данного отчета.

Вывод
Визуализация в свободной форме

Отражение
Самой важной и трудоемкой частью проблемы была очистка и обработка данных, поскольку было несколько столбцов с нулевыми значениями. После того, как данные были подготовлены и готовы, следующей задачей было выбрать алгоритм, который лучше всего подходил бы для задачи, которую мы решаем. Имея опыт и предварительные знания, а также точность данных обучения, мы заметили, что XGBoost работает лучше других. Мы знаем, что характеристики организации не зависят от банка или какого-либо менеджера компании, поскольку они являются индивидуальными характеристиками. Удаление их из важных предикторов оставляет нам в качестве варианта продолжительность, дни, предыдущие, жилье, контакт и ссуду. Среди них продолжительность может быть увеличена, и в этом случае это также самый важный предиктор. На основании проанализированных данных и следующих предметных областей даны несколько предложений по увеличению продолжительности. Исходящий звонок создает негативное отношение к банку из-за нарушения конфиденциальности. Банку следует снизить скорость исходящих звонков и разумно использовать входящие звонки для перекрестных продаж, чтобы увеличить продолжительность звонка. Во время входящих звонков агенты могут рассказывать о прибыли от срочного депозита для конкретного клиента. У банка должно быть четкое продвижение, и они должны заранее сформулировать ценностное предложение - отказ от комиссий, предложение чего-то бесплатного или продвижение пакетной услуги по сниженной цене увеличивает количество откликов по сравнению с простым информированием клиентов о продукте. Ценностное предложение должно быть прямо впереди с четким призывом к действию. «Продолжительность» положительно влияет на людей, которые говорят «да». Это связано с тем, что чем дольше вы разговариваете по телефону, тем выше интерес клиента к срочному вкладу. Банку следует сосредоточиться на потенциальных клиентах, у которых длительность звонков значительная, и, кроме того, которые решительно отреагировали на прошедшую кампанию.
Улучшения:
Одно из улучшений, которые мы могли сделать, - это выполнить настройку, чтобы улучшить скорость отзыва, чтобы улучшить общую производительность прогнозирования модели. Другое улучшение может заключаться в работе с подмножеством функций, имеющих высокое значение парето переменной важности. Другой ключевой аспект - это анализ таких показателей, как потеря журнала, чтобы понять, насколько быстро модель может настраиваться.
Ссылки:
[1] Оу, К., Лю, К., Хуанг, Дж. И Чжун, Н. «One Data Mining для прямого маркетинга», Springer-Verlag Berlin Heidelberg,
pp. 491–498., 2003.
[2] http://en.wikipedia.org/wiki/Direct_marketing. В Википедии есть инструмент для цитирования определенных статей, связанных с
к прямому маркетингу.
[3] О'Гинн, Томас ». Реклама и комплексное продвижение бренда ». Оксфорд, Оксфордшир: Издательство Оксфордского университета. п.
625. ISBN 978–0–324–56862–2. , 2008.
[4] Петрисон, Л. А., Блаттберг, Р. К. и Ван, П. «Маркетинг баз данных: прошлое, настоящее и будущее», Journal of Direct.
Маркетинг, 11, 4, 109–125, 1997.
[5] Eniafe Festus Ayetiran, «Модель отклика на основе интеллектуального анализа данных для выбора цели в прямом маркетинге»,
I.J. Информационные технологии и информатика, 2012, 1, 9–18.