
Сначала несколько слов об этом проекте, мотивации, задействованных технологиях и конечном продукте, который мы собираемся создать.
Таким образом, главная цель здесь, очевидно, состоит в том, чтобы предсказать дождь в будущем (мы попробуем 6 часов). Предсказание будет да или нет (логическое значение в терминах программирования). Я искал учебники по этому вопросу и не нашел ни одного, который был бы полным во всех отношениях. Так что мой будет использовать совершенно новый подход и вникать в каждый его аспект. Для этого мы собираемся:
- построить метеостанцию самостоятельно. Станция должна быть полностью отключена от сети с солнечной панелью и режимом чрезвычайно низкой мощности (несколько десятков микроампер в час).
- запрограммировать станцию так, чтобы она собирала данные и каждые десять минут передавала их на базовую станцию.
- собирать данные на базовой станции и сохранять их (в базе данных)
- используя нейронные сети (библиотека Keras) и другие библиотеки Python, такие как pandas, фильтруют, очищают и предварительно обрабатывают данные, а затем передают их в нейронную сеть для обучения «модели» для прогнозирования того, будет дождь или нет
- наконец, предсказать, будет ли дождь в ближайшие 6 часов, и уведомить пользователей по электронной почте.
Я лично использовал эту метеостанцию для сбора данных (вы можете загрузить данные в следующих шагах, если хотите). Имея данные о погоде всего за 600 дней, система может сделать прогноз, будет ли дождь или нет в ближайшие 6 часов с точностью около 80% в зависимости от параметров, что не так уж и плохо.
В этом руководстве мы проведем вас через все необходимые шаги для прогнозирования осадков с нуля. Мы создадим конечный продукт, который выполняет практическую работу, не используя внешние API-интерфейсы погоды или машинного обучения. По ходу дела мы узнаем, как построить практичную метеостанцию (маломощную и автономную), которая действительно собирает данные в течение длительных периодов времени без обслуживания. После этого вы научитесь программировать его с помощью Arduino IDE. Как собрать данные в базу данных на базовой станции (сервере). И как обработать данные (Pandas) и применить нейронные сети (Keras), а затем предсказать количество осадков.
Если вам нравится этот проект, вы можете найти больше подобных материалов на: Github, Instructables и YouTube.
Части:
1. Небольшая пластиковая коробка со съемными крышками (у меня на винтах). Размер коробки должен быть достаточно большим, чтобы в него поместились мелкие компоненты и батареи. В моей коробке 11 х 7 х 5 см.
2. держатель для трех батареек ААА
3. три перезаряжаемые батарейки ААА
4. Маленькая солнечная панель 6 В
5. Ардуино Про Мини 328p
6. диод, 1N4004 (для предотвращения обратного тока от аккумуляторов к панели)
7. маленький транзистор NPN и резистор 1k (для включения и выключения питания компонентов)
8. датчик дождя
9. Модуль последовательной связи HC-12
10. HC-12 USB последовательный модуль (для базовой станции)
11. Модуль датчиков bosch BME280 (для влажности, температуры, давления)
12. Светочувствительный модуль BH1750
13. Плата, провода, припой, штекер KF301–2P с винтовым разъемом, штекерные и гнездовые разъемы для печатных плат, клей.
14. Регулятор 3,3 В
15. Базовая станция: постоянно работающий ПК или макетная плата. Его роль заключается в сборе данных, обучении модели прогнозирования дождя и составлении прогнозов.
Инструменты:
1. USB-адаптер FTDI FT232RL для программирования Arduino Pro Mini.
2. Ардуино IDE
3. Дрель
4. Пила с тонким лезвием
5. Отвертки
6. Паяльник
7. Кусачки
Навыки:
1. Пайка, посмотрите этот туториал
2. Базовое программирование ардуино
3. Настройка службы Linux, установка пакета
4. Некоторые навыки программирования
Шаг 2: Строительство метеостанции















Метеостанция состоит из следующих наборов компонентов:
1. коробка с приклеенной к ней солнечной панелью
2. печатная плата с электроникой внутри
3. держатель батареи тоже внутри
4. BME280 и датчики света и дождя снаружи
1. В коробке нужно 4 отверстия, одно для проводов солнечной панели, три других для датчиков, которые будут размещены снаружи. Сначала просверлите целые, они должны быть достаточно большими, чтобы провода «папа-мама» торчали и шли к датчикам. После того, как все просверлено, приклейте панель к одной стороне коробки и протяните провода через отверстие внутри.
2. Плата будет содержать Arduino, HC-12, регулятор 3,3 В, диод, транзистор, резистор и два KF301–2P.
- сначала припаяйте два гнездовых разъема печатной платы на печатной плате для Arduino, припаяйте штекерные разъемы печатной платы к arduino и поместите arduino на печатную плату.
- светодиод Arduino должен быть удален или хотя бы один из его контактов. это очень важно, потому что светодиод будет потреблять большое количество энергии. Будьте осторожны, чтобы не повредить другие компоненты
- припаиваем транзистор, резистор и стабилизатор 3.3В
- припаяйте два КФ301–2П. Один будет для солнечной панели, другой для держателя батареи
- припаяйте три гнезда на печатной плате: для датчика света, BME280 и датчика дождя
- припаяйте небольшие провода, чтобы соединить все компоненты печатной платы (проверьте изображения и схему fritzing)
3. поместите 3 заряженных никель-металлогидридных аккумулятора ААА внутрь держателя и поместите его внутрь коробки, подключив провода в разъем KF301–2P
4. подключите BME280 и датчики освещенности снаружи коробки к соответствующим штекерным разъемам.
Для датчика дождя припаяйте к нему три провода (Gnd, Vcc, сигнал), а с другой стороны припаяйте штыревые контакты, которые войдут внутрь коробки, к соответствующим штекерным разъемам.
Последнее, что нужно сделать, это разместить станцию в ее конечной позиции. Я выбрал место, защищенное от дождя и снега. Я выбрал более длинные провода для датчика дождя и разместил его отдельно под дождем на устойчивой опоре. Для основной коробки я выбрал специальную липкую ленту (см. изображения), но подойдет любая, которая держит коробку.
Шаг 3: Код Arduino
На этом этапе вы узнаете, какие внешние библиотеки необходимы, мы рассмотрим код и то, как он работает, и, конечно же, вы сможете загрузить его или скопировать и вставить в Arduino IDE и загрузить на метеостанцию.
Роль метеостанции заключается в передаче на базовую станцию каждые 10 минут данных о ее датчиках.
Сначала опишем, что делает программа метеостанции:
1. считывать данные датчиков (влажность, температура, давление, дождь, свет, напряжение)
2. передает закодированные данные через вторую последовательную линию программного обеспечения.
Закодированные данные выглядят так:
H1:78|T1:12|PS1:1022|L1:500|R1:0|V1:4010|Заявление сверху будет означать, что: влажность на станции «1» 78 процентов, температура на станции 1 12 градусов, давление 1022 бар, уровень освещенности 500 люкс, дождь 0, напряжение 4010 милливольт.
3. выключите вспомогательные компоненты: датчики и устройство связи.
4. переводит Arduino в спящий режим на 10 минут (это позволит потреблять меньше 50 микроампер)
5. включите компоненты и повторите шаги 1–4.
Здесь есть одна небольшая дополнительная настройка: если уровень напряжения выше 4,2 В, Arduino будет использовать обычную функцию сна «задержка (миллисекунды)». Это значительно увеличит энергопотребление и быстро уменьшит напряжение. Это эффективно предотвращает перезарядку батарей солнечной панели.
Вы можете получить код из моего репозитория Github здесь:https://github.com/danionescu0/home-automation/tree/master/arduino-sketches/weatherStation
Или скопируйте и вставьте его снизу, в любом случае просто удалите строку с "transmitSenzorData("V", sensor.voltage);"
#include "LowPower.h"<br>#include "SoftwareSerial.h" #include "Wire.h" #include "Adafruit_Sensor.h" #include "Adafruit_BME280.h" #include "BH1750.h"SoftwareSerial serialComm(4, 5); // RX, TX Adafruit_BME280 bme; BH1750 lightMeter; const byte rainPin = A0; byte sensorsCode = 1; /** * voltage level that will pun the microcontroller in deep sleep instead of regular sleep */ int voltageDeepSleepThreshold = 4200; const byte peripherialsPowerPin = 6; char buffer[] = {' ',' ',' ',' ',' ',' ',' '};struct sensorData { byte humidity; int temperature; byte rain; int pressure; long voltage; int light; }; sensorData sensors;void setup() { Serial.begin(9600); serialComm.begin(9600); pinMode(peripherialsPowerPin, OUTPUT); digitalWrite(peripherialsPowerPin, HIGH); delay(500); if (!bme.begin()) { Serial.println("Could not find a valid BME280 sensor, check wiring!"); while (1) { customSleep(100); } } Serial.println("Initialization finished succesfully"); delay(50); digitalWrite(peripherialsPowerPin, HIGH); }void loop() { updateSenzors(); transmitData(); customSleep(75); }void updateSenzors() { bme.begin(); lightMeter.begin(); delay(300); sensors.temperature = bme.readTemperature(); sensors.pressure = bme.readPressure() / 100.0F; sensors.humidity = bme.readHumidity(); sensors.light = lightMeter.readLightLevel(); sensors.voltage = readVcc(); sensors.rain = readRain(); }void transmitData() { emptyIncommingSerialBuffer(); Serial.print("Temp:");Serial.println(sensors.temperature); Serial.print("Humid:");Serial.println(sensors.humidity); Serial.print("Pressure:");Serial.println(sensors.pressure); Serial.print("Light:");Serial.println(sensors.light); Serial.print("Voltage:");Serial.println(sensors.voltage); Serial.print("Rain:");Serial.println(sensors.rain); transmitSenzorData("T", sensors.temperature); transmitSenzorData("H", sensors.humidity); transmitSenzorData("PS", sensors.pressure); transmitSenzorData("L", sensors.light); transmitSenzorData("V", sensors.voltage); transmitSenzorData("R", sensors.rain); }void emptyIncommingSerialBuffer() { while (serialComm.available() > 0) { serialComm.read(); delay(5); } }void transmitSenzorData(String type, int value) { serialComm.print(type); serialComm.print(sensorsCode); serialComm.print(":"); serialComm.print(value); serialComm.print("|"); delay(50); }void customSleep(long eightSecondCycles) { if (sensors.voltage > voltageDeepSleepThreshold) { delay(eightSecondCycles * 8000); return; } digitalWrite(peripherialsPowerPin, LOW); for (int i = 0; i < eightSecondCycles; i++) { LowPower.powerDown(SLEEP_8S, ADC_OFF, BOD_OFF); } digitalWrite(peripherialsPowerPin, HIGH); delay(500); }byte readRain() { byte level = analogRead(rainPin); return map(level, 0, 1023, 0, 100); }long readVcc() { // Read 1.1V reference against AVcc // set the reference to Vcc and the measurement to the internal 1.1V reference #if defined(__AVR_ATmega32U4__) || defined(__AVR_ATmega1280__) || defined(__AVR_ATmega2560__) ADMUX = _BV(REFS0) | _BV(MUX4) | _BV(MUX3) | _BV(MUX2) | _BV(MUX1); #elif defined (__AVR_ATtiny24__) || defined(__AVR_ATtiny44__) || defined(__AVR_ATtiny84__) ADMUX = _BV(MUX5) | _BV(MUX0); #elif defined (__AVR_ATtiny25__) || defined(__AVR_ATtiny45__) || defined(__AVR_ATtiny85__) ADMUX = _BV(MUX3) | _BV(MUX2); #else ADMUX = _BV(REFS0) | _BV(MUX3) | _BV(MUX2) | _BV(MUX1); #endif delay(2); // Wait for Vref to settle ADCSRA |= _BV(ADSC); // Start conversion while (bit_is_set(ADCSRA,ADSC)); // measuring uint8_t low = ADCL; // must read ADCL first - it then locks ADCH uint8_t high = ADCH; // unlocks both long result = (high<<8) | low; result = 1125300L / result; // Calculate Vcc (in mV); 1125300 = 1.1*1023*1000 return result; // Vcc in millivolts }
Перед загрузкой кода скачайте и установите следующие библиотеки arduino:
* Библиотека BH1750: https://github.com/claws/BH1750 * Библиотека LowPower: https://github.com/rocketscream/Low-Power
* Библиотека Adafruit Sensor: https://github.com/adafruit/Adafruit_Sensor
* Библиотека Adafruit BME280: https://github.com/adafruit/Adafruit_Sensor
Если вы не знаете, как это сделать, посмотрите этот урок.
Шаг 4: Подготовка базовой станции
Базовая станция будет состоять из компьютера с ОС Linux (настольного компьютера, ноутбука или платы разработки) с подключенным модулем HC-12 USB. Компьютер должен оставаться всегда включенным для сбора данных со станции каждые 10 минут.
Я использовал свой ноутбук с Ubuntu 18.
Шаги установки:
1. Установите anaconda. Anaconda — это менеджер пакетов Python, и он упростит нам работу с одними и теми же зависимостями. Мы сможем контролировать версию Python и каждую версию пакета.
Если вы не знаете, как его установить, ознакомьтесь с этим: https://www.digitalocean.com/community/tutorials/h... и выполните шаги 1–8.
2. Установите MongoDb. MongoDb будет нашей основной базой данных для этого проекта. В нем будут храниться данные обо всех временных рядах датчиков. Он не содержит схемы и для наших целей его легко использовать.
Чтобы узнать об этапах установки, посетите их страницу: https://docs.mongodb.com/v3.4/tutorial/install-mon...
Я использовал более старую версию mongoDb 3.4.6, если вы будете следовать приведенному выше руководству, вы получите именно это. По идее должно работать с последней версией.
[Необязательно] добавьте индекс в поле даты:
mongo
use weather
db.weather_station.createIndex({"date" : 1})3. Скачать проект отсюда: https://github.com/danionescu0/home-automation.
Мы будем использовать папку прогноза погоды.
sudo apt-get install git
git clone https://github.com/danionescu0/home-automation4. Создайте и настройте среду anaconda:
cd weather-predict # create anaconda environment named "weather" with python 3.6.2 conda create --name weather python=3.6.2 # activate environment conda activate weather # install all packages pip install -r requirements.txt
Это создаст новую среду anaconda и установит необходимые пакеты. Некоторые из пакетов:
Keras (уровень нейронной сети высокого уровня, с помощью этой библиотеки мы будем делать все наши прогнозы нейронной сети)
pandas (полезный инструмент, который манипулирует данными, мы будем активно его использовать)
sklearn (инструменты для сбора и анализа данных)
pymongo (драйвер Python mongoDb)
Настроить проект
Файл конфигурации находится в папке прогноза погоды и называется config.py.
1. если вы устанавливаете MongoDb удаленно или на другой порт, измените «хост» или «порт» в
mongodb = {
'host': 'localhost',
'port': 27017
}
...
2. Теперь нам нужно подключить последовательный USB-адаптер HC-12. Перед запуском:
ls -l /dev/tty*и вы должны получить список подключенных устройств.
Теперь вставьте HC-12 в USB-порт и снова запустите ту же команду. В этом списке должна быть одна новая запись — наш последовательный адаптер. Теперь измените порт адаптера в конфиге, если это необходимо
serial = {
'port': '/dev/ttyUSB0',
'baud_rate': 9600
}
Другие записи конфигурации — это пути к некоторым файлам по умолчанию, их не нужно менять.
Шаг 5: Используйте метеостанцию на практике



Здесь мы обсудим основные вещи, связанные с импортом моих тестовых данных, запуском некоторых тестов, настройкой ваших собственных данных, отображением некоторых графиков и настройкой электронной почты с прогнозом на следующие несколько часов.
Если вы хотите узнать больше о том, как это работает, ознакомьтесь со следующим шагом «Как это работает».
Импорт моих уже собранных данных
MongoDb поставляется с командой cli для импорта данных из json:
mongoimport -d weather -c weather_station --file sample_data/weather_station.jsonЭто позволит импортировать файл из образца данных в базу данных «погода» и коллекцию «точки данных».
Здесь предупреждение: если вы используете собранные мной данные и объединяете их с вашими новыми локальными данными, точность может снизиться из-за небольших различий в оборудовании (датчики) и местных погодных условий.
Сбор новых данных
Одна из ролей базовой станции — сохранять входящие данные с метеостанции в базу данных для последующей обработки. Чтобы запустить процесс, который прослушивает последовательный порт и сохраняет в базе данных, просто запустите:
conda activate weather
python serial_listener.py
# every 10 minutes you should see data from the weather station coming in :
[Sensor: type(temperature), value(14.3)]
[Sensor: type(pressure), value(1056.0)]
...Создание прогнозной модели
Я предполагаю, что вы импортировали мои данные или «запустили сценарий в течение нескольких лет», чтобы собрать свои персонализированные данные, поэтому на этом этапе мы обработаем данные для создания модели, используемой для прогнозирования будущего дождя.
conda activate weather
python train.py --days_behind 600 --test-file-percent 10 --datapoints-behind 8 --hour-granularity 6* Первый параметр — days_behind означает, сколько данных в прошлое должен обработать скрипт. Измеряется в днях
* — test-file-percent означает, сколько данных следует учитывать для целей тестирования, это обычный шаг в алгоритме машинного обучения.
* — часовая гранулярность в основном означает, через сколько часов в будущем нам нужен прогноз.
* — данные, стоящие за этим параметром, будут обсуждаться далее в следующем разделе.
Просмотреть несколько диаграмм данных со всеми датчиками метеостанций
Скажем, за последние 10 дней:
conda activate weather
python graphs --days-behind 10Предсказать, будет ли дождь в следующий период
Мы предскажем, будет ли дождь, и отправим уведомление по электронной почте
conda activate weather python train.py --days_behind 600 --test-file-percent 10 --datapoints-behind 8 --hour-granularity 6
Запустите пакетный прогноз на тестовых данных:
python predict_batch.py -f sample_data/test_data.csvВажно использовать те же параметры, что и в приведенном выше скрипте поезда.
Чтобы уведомление по электронной почте работало, войдите в свою учетную запись gmail и включите параметр Разрешить менее безопасные приложения. Имейте в виду, что это облегчает другим доступ к вашей учетной записи.
Вам понадобятся два адреса электронной почты, адрес Gmail с активированной выше опцией и другой адрес, на который вы получите уведомление.
Если хотите получать уведомления каждый час, поместите скрипт в crontab
Чтобы увидеть, как все это возможно, проверьте следующий шаг
Шаг 6: Как это работает
На этом последнем шаге мы обсудим несколько аспектов архитектуры этого проекта:
1. Обзор проекта, мы обсудим общую архитектуру и задействованные технологии.
2. Основные понятия машинного обучения
3. Как готовятся данные (самый важный шаг)
4. Как работает реальный API-интерфейс нейронной сети (Keras)
5. Будущие улучшения
Я постараюсь привести здесь пример кода, но имейте в виду, что это не 100% код из проекта. В проекте сам код немного сложнее с классами и структурой
1. Обзор проекта, мы обсудим общую архитектуру и задействованные технологии
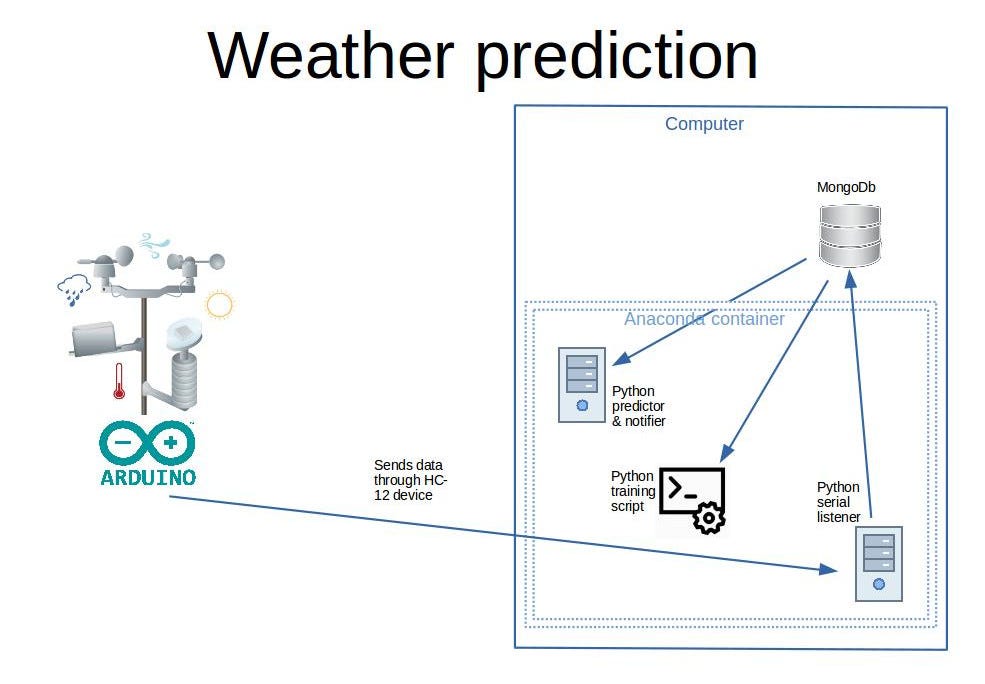
Как мы говорили ранее, проект состоит из двух отдельных частей. Сама метеостанция, единственной функцией которой является сбор и передача данных. И базовая станция, где будет происходить вся тренировка сбора и предсказания.
Преимущества разделения метеостанции и базовой станции:
- требования к электропитанию, если метеостанция также может обрабатывать данные, ей потребуется значительная мощность, возможно, большие солнечные батареи или постоянный источник питания.
- портативность, благодаря небольшому размеру метеостанция может собирать данные с расстояния в несколько сотен метров, и при необходимости вы можете легко изменить ее место
- масштабируемость, вы можете повысить точность прогноза, построив более одной метеостанции и разбросав их на несколько сотен метров
- низкая стоимость, потому что это дешевое устройство, вы можете легко собрать другое в случае, если одно потеряно или украдено
Выбор базы данных. Я выбрал MongoDb, потому что у него хорошие функции: отсутствие схем, бесплатный и простой в использовании API.
Каждый раз, когда данные датчика принимаются, данные сохраняются в базе данных, запись данных выглядит примерно так:
{
"_id" : "04python train.py -d 2000 -p 20 -dp 4 -hg 6 --data-source darksky
2017_06_17",
"humidity" : 65,
"date" : ISODate("2017-04-27T06:17:18Z"),
"pressure" : 1007,
"temperature" : 9,
"rain" : 0,
"light" : 15
}
База данных хранит данные в формате BSON (похожем на JSON), поэтому их легко читать и с ними легко работать. Я агрегировал данные под идентификатором, который содержит дату, отформатированную как строка, до минут, поэтому наименьшая группировка здесь — это минуты.
Метеостанция (при правильной работе) будет передавать точку данных каждые 10 минут. Точка данных представляет собой набор значений «дата», «влажность», «давление», «температура», «дождь» и «свет».
Выбор технологии обработки данных и нейронной сети
Я выбрал Python для бэкенда, потому что многие важные инновации в нейронных сетях можно найти в Python. Растущее сообщество с множеством репозиториев Github, обучающих блогов и книг здесь, чтобы помочь.
* Для части обработки данных я использовал Pandas (https://pandas.pydata.org/). Панды упрощают работу с данными. Вы можете загружать таблицы из структур данных CSV, Excel, Python и изменять их порядок, удалять столбцы, добавлять столбцы, индексировать по столбцу и выполнять множество других преобразований.
* Для работы с нейросетями я выбрал Keras (https://keras.io/). Keras — это высокоуровневая оболочка нейронной сети над более низкоуровневыми API, такими как Tensorflow, и можно построить многослойную нейронную сеть с помощью дюжины строк кода или около того. Это большое преимущество, потому что мы можем построить что-то полезное на великой работе других людей. Ну, это основной материал программирования, основанный на других более мелких строительных блоках.
2. Основные концепции машинного обучения
Целью этого руководства является не обучение машинному обучению, а просто описание одного из возможных вариантов его использования и того, как мы можем практически применить его к этому варианту использования.
Нейронные сети — это структуры данных, которые напоминают клетки мозга, называемые нейронами. Наука обнаружила, что в мозге есть особые клетки, называемые нейронами, которые общаются с другими нейронами с помощью электрических импульсов через «линии», называемые аксонами. При достаточной стимуляции (от многих других нейронов) нейроны будут запускать электрический импульс дальше в этой «сети», стимулируя другие нейроны. Это, конечно, чрезмерное упрощение процесса, но в основном компьютерные алгоритмы пытаются воспроизвести этот биологический процесс.
В компьютерных нейронных сетях у каждого нейрона есть «пусковая точка», где при стимуляции над этой точкой он будет распространять стимуляцию вперед, а если нет, то нет. Для этого каждый смоделированный нейрон будет иметь смещение, а каждый аксон — вес. После случайной инициализации этих значений запускается процесс, называемый «обучением», это означает, что в цикле алгоритм будет выполнять следующие шаги:
- стимулировать входные нейроны
- распространять сигналы через слои сети до тех пор, пока выходные нейроны
- прочитать выходные нейроны и сравнить результаты с желаемыми результатами
- настроить веса аксонов для лучшего результата в следующий раз
- начните снова, пока не будет достигнуто количество петель
Если вы хотите узнать больше об этом процессе, вы можете прочитать эту статью: https://mattmazur.com/2015/03/17/a-step-by-step-ba.... Также существует множество книг и руководств.
Еще одна вещь, здесь мы будем использовать метод обучения с учителем. Это означает, что мы также будем обучать алгоритм входным и выходным данным, чтобы с учетом нового набора входных данных он мог предсказывать выходные данные.
3. Как готовятся данные (самый важный шаг)
Во многих задачах машинного обучения и нейронных сетей подготовка данных является очень важной частью, и она будет охватывать:
- получить необработанные данные
- очистка данных: это будет означать удаление бесхозных значений, аберраций или других аномалий
- группировка данных: получение множества точек данных и преобразование в агрегированную точку данных
- улучшение данных: добавление других аспектов данных, полученных из собственных данных или из внешних источников.
- разделение данных в поезде и тестовых данных
- разделить каждый из поезда и тестовых данных на входы и выходы. Обычно проблема имеет много входов и несколько выходов.
- масштабировать данные так, чтобы они были между 0 и 1 (это поможет сети устранить предвзятость высоких/низких значений)
Получение необработанных данных
В нашем случае получить данные для MongoDb в python очень просто. Учитывая нашу коллекцию точек данных, подойдут только эти строки кода.
client = MongoClient(host, port).weather.datapoints
cursor = client.find(
{'$and' : [
{'date' : {'$gte' : start_date}},
{'date' : {'$lte' : end_date}}
]}
)
data = list(cursor)
..
Очистка данных
Пустые значения в кадре данных удаляются
dataframe = dataframe.dropna()Группировка и улучшение данных
Это очень важный шаг, множество небольших точек данных будут сгруппированы в интервалы по 6 часов. Для каждой группы будет рассчитано несколько метрик по каждому из датчиков (влажность, дождь, температура, освещенность, давление)
- минимальное значение
- максимальное значение
- значит
- 70, 90, 30, 10 процентилей
- кол-во раз был подъем датчика
- количество раз было падение датчика
- количество раз в датчике были устойчивые значения
Все эти вещи дадут сетевую информацию для точки данных, поэтому для каждого из 6-часовых интервалов эти вещи будут известны.
Увеличьте изображение ниже, чтобы увидеть данные:

После этого будет добавлен новый столбец с именем «has_rain». Это будет выход (наша предсказанная переменная). Дождь будет равен 0 или 1 в зависимости от того, превышает ли среднее значение дождя пороговое значение (0,1). С пандами это так же просто, как:
dataframe.insert(loc=1, column='has_rain', value=numpy.where(dataframe['rain_avg'] > 0.1, 1, 0))Очистка данных (снова)
- мы удалим столбец даты, потому что он нам не нужен, а также удалим точки данных, где минимальная температура ниже 0, потому что наша метеостанция не имеет датчика снега, поэтому мы не сможем измерить, если он снег
dataframe = dataframe.drop(['date'], axis=1)
dataframe = dataframe[dataframe['temperature_min'] >= 0]Улучшение данных
Поскольку данные в прошлом могут повлиять на наш прогноз дождя, нам нужно для каждой строки кадра данных добавить ссылку на столбцы на прошлые строки. Это связано с тем, что каждая строка будет служить точкой обучения, и если мы хотим, чтобы прогноз дождя учитывал предыдущие точки данных, это именно то, что мы должны сделать: добавить больше столбцов для точек данных в прошлом примере:

Итак, вы видите, что для каждого датчика, скажем, температуры, будут добавлены следующие строки: «температура_1», «температура_2».. означает температуру в предыдущей точке данных, температуру в двух предыдущих точках данных и т. д. Я экспериментировал с этим и нашел это оптимальное число для наших 6-часовых группировок в 8. Это означает, что 8 точек данных в прошлом (48 часов). Таким образом, наша сеть узнала лучшее из точек данных, охватывающих 48 часов в прошлом.
Очистка данных (снова)
Как видите, первые несколько столбцов имеют значения «NaN», потому что перед ними ничего нет, поэтому их следует удалить, поскольку они неполные.
Также следует отбрасывать данные о текущей точке данных, единственным исключением является «has_rain». идея состоит в том, что система должна иметь возможность предсказывать «has_rain», не зная ничего, кроме предыдущих данных.
Разделение данных в обучающих и тестовых данных
Это очень просто благодаря пакету Sklearn:
from sklearn.model_selection import train_test_split ... main_data, test_data = train_test_split(dataframe, test_size=percent_test_data) ...
Это случайным образом разделит данные на два разных набора
Разделите все данные обучения и тестирования на входные и выходные данные
Предполагая, что наш столбец интересов «has_rain» расположен первым
X = main_data.iloc[:, 1:].values y = main_data.iloc[:, 0].values
Измените масштаб данных, чтобы они были между 0 и 1
Опять же довольно легко из-за sklearn
from sklearn.preprocessing import StandardScaler from sklearn.externals import joblib .. scaler = StandardScaler() X = scaler.fit_transform(X) ... # of course we should be careful to save the scaled model for later reuse joblib.dump(scaler, 'model_file_name.save')
4. Как работает реальный API-интерфейс нейронной сети (Keras)
Построить многослойную нейронную сеть с помощью Keras очень просто:
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
...
input_dimensions = X.shape[1]
optimizer = 'rmsprop'
dropout = 0.05
model = Sequential()
inner_nodes = int(input_dimensions / 2)
model.add(Dense(inner_nodes, kernel_initializer='uniform', activation='relu', input_dim=input_dimensions))
model.add(Dropout(rate=dropout))
model.add(Dense(inner_nodes, kernel_initializer='uniform', activation='relu'))
model.add(Dropout(rate=dropout))
model.add(Dense(1, kernel_initializer='uniform', activation='sigmoid'))
model.compile(optimizer=optimizer, loss='mean_absolute_error', metrics=['accuracy'])
model.fit(X, y, batch_size=1, epochs=50)
...
# save the model for later use
classifier.save('file_model_name')
Так что же означает этот код? Здесь мы строим последовательную модель, что означает последовательное оценивание всех слоев.
а) мы объявляем входной слой (Dense), здесь все входы из нашего набора данных будут инициализированы, поэтому параметр «input_dim» должен быть равен длине строки
б) добавлен слой Dropout. Чтобы понять выпадение, сначала мы должны понять, что означает «переоснащение»: это состояние, в котором сеть изучила слишком много особенностей для определенного набора данных и будет плохо работать при столкновении с новым набором данных. Слой отсева будет случайным образом отключать нейроны на каждой итерации, чтобы сеть не переобучалась.
c) добавляется еще один слой Dense
г) еще один отсев
e) последний слой добавляется с одним выходным измерением (он будет предсказывать только да/нет)
f) модель «подогнана», что означает, что начнется процесс обучения, и модель будет обучаться
Другие параметры здесь:
- функции активации (сигмовидная, релу). Это функции, которые диктуют, когда нейрон будет передавать свой импульс дальше по сети. Их много, но наиболее распространены сигмоид и релу. Перейдите по этой ссылке для более подробной информации: https://towardsdatascience.com/activation-function...
- функция kernel_initializer (униформа). Это означает, что все веса инициализируются случайными однородными значениями.
- функция потерь (mean_absolute_error). Эта функция измеряет ошибку, сравнивая спрогнозированный сетью результат с реальным значением. Альтернатив много: https://keras.io/losses/
- метрическая функция (точность). Он измеряет производительность модели
- функции оптимизатора (rmsprop). Он оптимизирует обучение модели посредством обратного распространения.
- размер партии. Количество точек данных, которые Keras берет один раз перед применением функции оптимизатора
- эпохи: сколько раз процесс начинался с 0 (чтобы лучше учиться)
Для любой сети или набора данных не существует лучшей конфигурации, все эти параметры можно нужно настроить для достижения оптимальной производительности, и они будут иметь большое значение для успеха прогнозирования.
5. Будущие улучшения
Начнем с метеостанции. Я вижу, что здесь предстоит проделать большую работу по улучшению:
- добавить датчик скорости/направления ветра. Это может быть очень важный датчик, которого мне не хватает в моей модели.
- экспериментировать с ультрафиолетовыми лучами, датчиками газа и частиц
- добавьте по крайней мере две станции в зону для получения более качественных данных (сделайте более точные средние значения)
- собрать данные еще за несколько лет, я экспериментировал всего за полтора года
Некоторые улучшения обработки:
- попытайтесь включить в модель данные из других источников. Вы можете начать импортировать данные о скорости ветра и комбинировать их с данными местной станции для получения лучшей модели. Этот сайт предлагает исторические данные: https://www.wunderground.com/history/
- лучше оптимизируйте модель Keras, настроив: слои, количество нейронов в слоях, процент отсева, функции метрик, функции оптимизатора, функции потерь, размер пакета, эпохи обучения
- попробуйте другие архитектуры моделей, например, я экспериментировал с LSTM (долговременная кратковременная память), но это дало немного худшие результаты)
Чтобы попробовать разные параметры модели обучения, вы можете использовать
python train.py --days_behind 600 --test-file-percent 10 --datapoints-behind 6 --hour-granularity 6 --grid-search
Это будет выполнять поиск по различным значениям «batch_size», «epoch», «optimizer» и «dropout», оценивать все и распечатывать наилучшую комбинацию для ваших данных.
Если у вас есть отзывы о моей работе, поделитесь ими, спасибо, что остались до конца урока!
Шаг 7: Бонус: использование официального набора данных о погоде
Мне было интересно, смогу ли я получить лучшие результаты с более надежной метеостанцией, поэтому я немного поискал и наткнулся на Darksky API (https://darksky. net/dev), это отличный инструмент, который предоставляет текущие и исторические данные о погоде со многими другими данными датчиков:
- температура
- влажность
- давление
- скорость ветра
- порыв ветра
- УФ-индекс
- видимость
Итак, это данные официальной метеостанции, и, имея больше параметров, я подумал, что они должны работать лучше, поэтому я попробовал. Чтобы повторить мои выводы:
1. Загрузите данные из darsky или импортируйте мою коллекцию MongoDb:
а) Скачать
- чтобы загрузить себя, сначала создайте учетную запись в darsky и получите ключ API
- замените ключ API в download_import/config.py
- также в конфиге замените географические координаты на место, где вы хотите предсказать дождь
- в консоли активируйте среду anaconda «погода» и запустите:
python download_import/darksky.py -d 1000- бесплатная версия API ограничена 1000 запросов в день, поэтому, если вы хотите получить больше данных, вам придется ждать дольше
b) Импорт моих загруженных данных для города Бухарест
- в консоли запустить
mongoimport -d weather -c darksky --file sample_data/darksky.json2. При обучении модели укажите, что она должна работать на «темном» наборе данных.
python train.py -d 2000 -p 20 -dp 4 -hg 6 --data-source darksky3. Чтобы увидеть результаты, запустите пакетный скрипт прогнозирования, как и раньше.
python predict_batch.py -f sample_data/test_data.csvВы увидите, что общий процент прогнозов увеличился примерно с 80% до 90%. Также повысилась точность предсказания при учете только дождливых дней.
Так что да, набор данных действительно имеет значение.