«Слова, которые вдохновят» - это анализ более 2500 выступлений на TED с использованием текстовой аналитики и машинного обучения на R, чтобы найти факторы, которые делают одни выступления более популярными, чем другие.
Что послужило мотивацией для выполнения этого проекта?
Я участвую в группе встреч под названием «Спикеры Data Scientist» в Лондоне, которая регулярно встречается, чтобы попрактиковаться в беседах по науке о данных и получить отзывы для улучшения публичных выступлений.
Каждый год в клубе проводится конкурс, чтобы узнать, кто сможет рассказать лучший рассказ о науке о данных. Я присоединился к этому конкурсу и хотел сделать в нем что-то особенное: я хотел объединить свои навыки в области науки о данных, чтобы анализировать известные выступления или выступления и использовать эти идеи для создания совершенно нового.

Что послужило источником вдохновения?
Я начал свой анализ с трех моих самых любимых речей, они были произнесены самыми выдающимися ораторами, и их выступления вдохновили миллионы людей на формирование мира. мы живем сегодня.
Можете ли вы узнать эти речи и их спикеров по следующим фрагментам?

Я говорю о Джоне Ф. Кеннеди, Мартине Лютере Кинге-младшем и Уинстоне Черчилле.
Расчет на обратной стороне конверта
В этих трех выступлениях я проанализировал частоту употребления слов и был удивлен ... наиболее часто используемым словом в каждой речи та же! Вы видите это там, прямо посреди словесных облаков?

Три говорящих чаще всего употребляют слово «Will» (Уинстон Черчилль использовал Shall в правильном британском стиле!). Они потенциально использовали слово «Воля» как способ вдохновить людей на действия или указать, что что-то изменится в будущем. В дополнение к этому сходству, три динамика также использовали что-то, что называется структурными повторениями. Они повторяют одну и ту же фразу много раз, чтобы произвести впечатление и запомнить.
Но нам нужно больше данных!
Эти совпадения заставили меня подумать, что в словах могут быть закономерности, которые могут сделать речь более вдохновляющей. Но определенно трех выступлений недостаточно, чтобы сделать выводы, и это поставило меня в поисках подходящей группы выступлений, которые я мог бы проанализировать. В идеале для анализа данных в переговорах должны быть:
- Достаточное количество разговоров для анализа
- В идеале одинаковый формат и стиль, чтобы избежать предвзятого отношения к разным форматам переговоров.
- Должны быть доступны стенограммы, так как это сократит время и усилия.
- А для использования машинного обучения должен быть способ отслеживать рост популярности, чтобы обнаруживать более вдохновляющие разговоры против менее вдохновляющих.
Момент Эврики
Похоже, что найти набор переговоров с этими соображениями может быть сложной задачей. Однако я быстро понял, что уже были переговоры со всеми этими характеристиками: Ted Talks!
Тед говорит в схожем стиле, и их тысячи, они отслеживают популярность, и у них есть доступные стенограммы и другая информация, такая как количество просмотров и комментарии на своем веб-сайте. Чтобы упростить задачу, сайт конкурса по науке о данных Kaggle уже опубликовал все эти данные и сделал их доступными для скачивания в подходящем формате.
Подход науки о данных
Теперь, когда данные стали доступны, я был готов провести анализ, который можно разделить на три этапа:
I. Извлечение данных и разработка функций
II. Анализ данных и ансамбль моделей
III. Модель Insights
I. Извлечение данных и разработка функций
Набор данных, предоставленный Kaggle, представлял собой довольно много данных, которые необходимо было преобразовать в первую очередь для проведения анализа. Я регулярно пользуюсь R, но не очень хорошо разбирался в текстовой аналитике, поэтому в основном следил за всем, что было в книге «Анализ текста с помощью R». Эта книга, безусловно, является источником текстовой аналитики с использованием R.
Набор данных содержал все мероприятия TED talk со всеми их стенограммами и любыми другими данными, которые вы можете увидеть на их веб-странице. Один действительно хороший момент заключается в том, что он также включает дату извлечения данных, дату публикации каждого выступления TED на веб-сайте и дату их съемки. Эти характеристики станут важными для выполнения прогнозного анализа при поиске закономерностей с использованием алгоритмов машинного обучения.
Я создал более 50 функций в качестве потенциальных факторов, чтобы проверить, почему одни доклады популярнее других. Большинство из этих исходных факторов были связаны с частотным анализом подсчета слов, например:
- Скорость речи говорящего с использованием слов в минуту, количество произнесенных предложений и количество слов в предложении.
- Реакция аудитории с использованием одной интересной особенности, обнаруженной в стенограммах, включает конкретные случаи, когда аудитория смеялась, аплодисменты, количество вопросов.
- И я включил множество подсчетов наиболее часто встречающихся n-граммов, чтобы увидеть, есть ли определенные слова, которые они склонны повторять.
С учетом этих факторов моей целью была задача классификации, чтобы предсказать, станет ли тед-доклад популярным или нет.
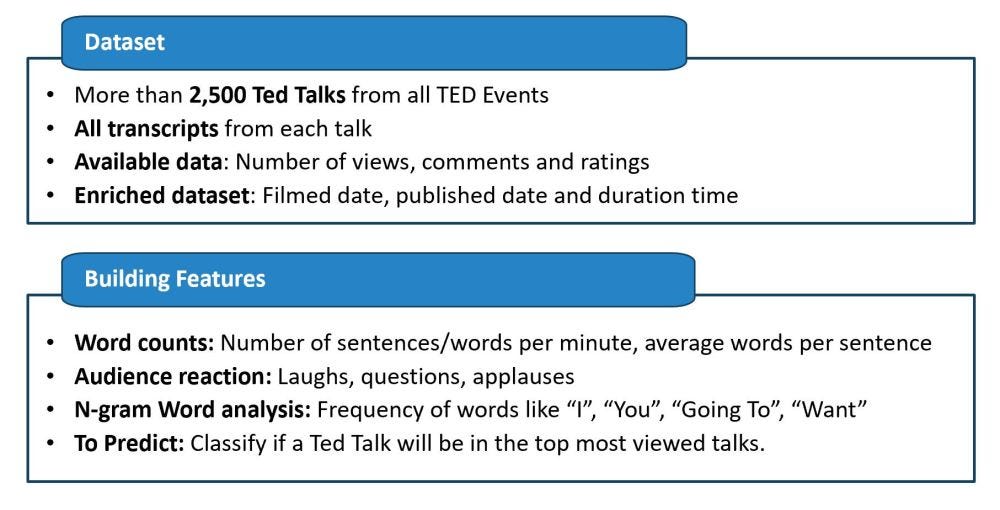
II. Анализ данных и ансамбль моделей
Этот этап можно резюмировать в следующих этапах.
1. Описательный анализ: Одна из ключевых особенностей анализа заключалась в том, чтобы каким-то образом стандартизировать количество времени, в течение которого Ted Talk был доступен в Интернете. Чем больше времени на веб-сайте будет размещаться выступление TED, тем больше будет шансов на большее количество просмотров. Поэтому я стандартизировал усреднение показателей за месяц, а не использовал итоги.
2. Корреляционный анализ: многие переменные имеют тенденцию коррелировать с другими. Поэтому один метод, который я использую, состоит в том, чтобы использовать только наиболее предсказуемую переменную (на одномерном уровне) и отбросить менее предсказуемую переменную, с которой была коррелирована.
3. Разработка дополнительных функций: Некоторые n-граммы были коррелированы между собой, поскольку в них использовалось одно и то же слово, поэтому я объединяю те полезные n-граммы, которые были похожи, в одну переменную.
4. Оценка модели: я начал анализировать данные на одномерном уровне, используя логистическую регрессию, чтобы найти наиболее релевантные переменные и отбросить переменные, которые вообще не были предсказательными. Используя 20 наиболее подходящих индивидуальных переменных, я начал вручную разрабатывать несколько типов моделей, включая логистические регрессии, случайный лес и XGBoost, путем настройки гиперпараметров, интервалов переменных и различных методологий выбора переменных.

В дополнение к моделям, разработанным вручную, я использовал функцию AutoML H2O, которая автоматически разрабатывает несколько типов моделей, таких как Stacked Models, Deep Learning и другие методологии повышения градиента. Эти методы автоматического моделирования помогут мне получить представление о том, как другие типы моделей будут работать по сравнению с теми, которые я разработал вручную.
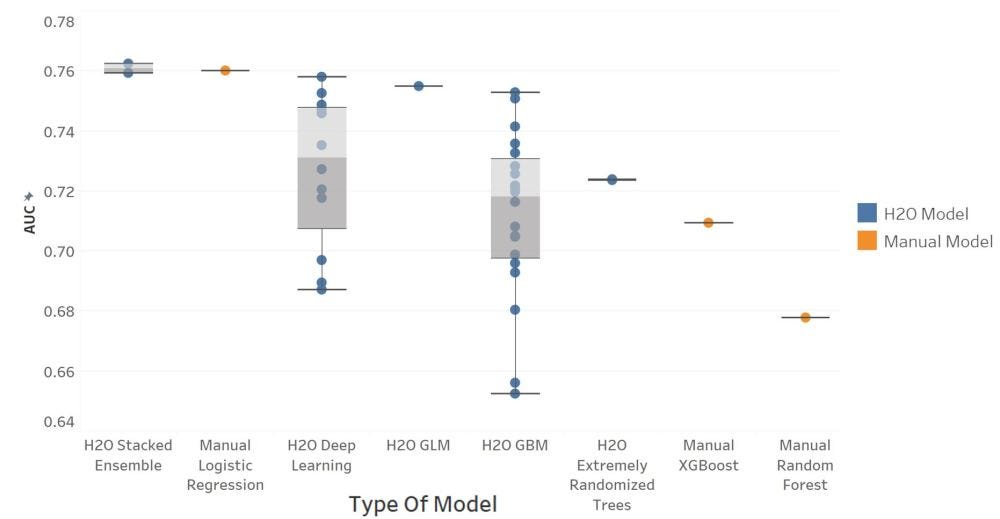
III. Модель Insights
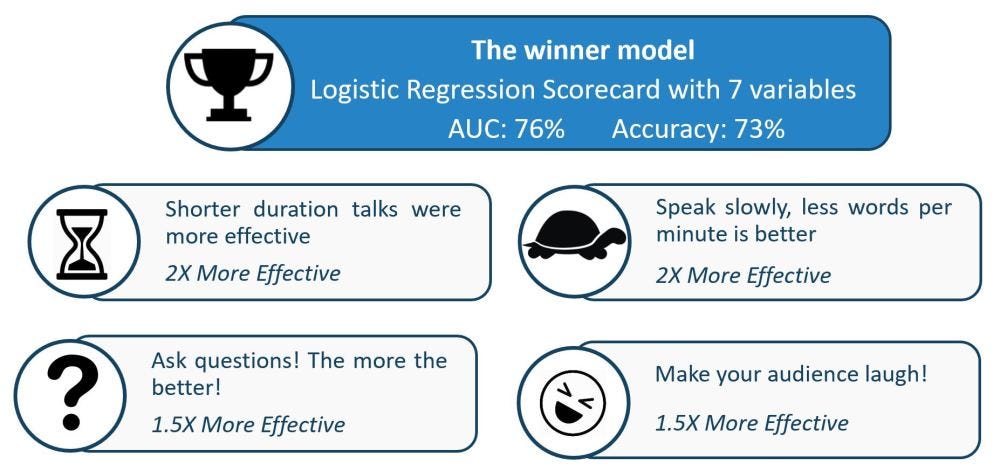
Удивительно, но различные типы моделей, разработанные H20, были не намного далеки с точки зрения производительности, чем модель ручной логистической регрессии. Поэтому я решил использовать логистическую регрессию, чтобы упростить объяснение того, как строились прогнозы. Чтобы сделать модели еще проще для понимания и избежать проблем с выбросами, я сгруппировал независимые переменные по квартилям на заключительном этапе моделирования. В окончательной модели было семь переменных, AUC 76% и точность 73% правильного предсказания популярного выступления.
Модель победителя показала мне, что:
- Короткие беседы более эффективны, чем более длительные
- Говорить медленно было более эффективным, это измерялось путем подсчета количества слов в минуту на основе общего количества слов в разговоре и его продолжительности.
- Задавать вопросы во время беседы было более эффективным. Это было измерено путем определения вопросительных знаков в расшифровке стенограммы.
- Рассмешить публику оказалось более эффективным. Это было измерено путем определения появления подписей к смеху в расшифровке стенограммы.
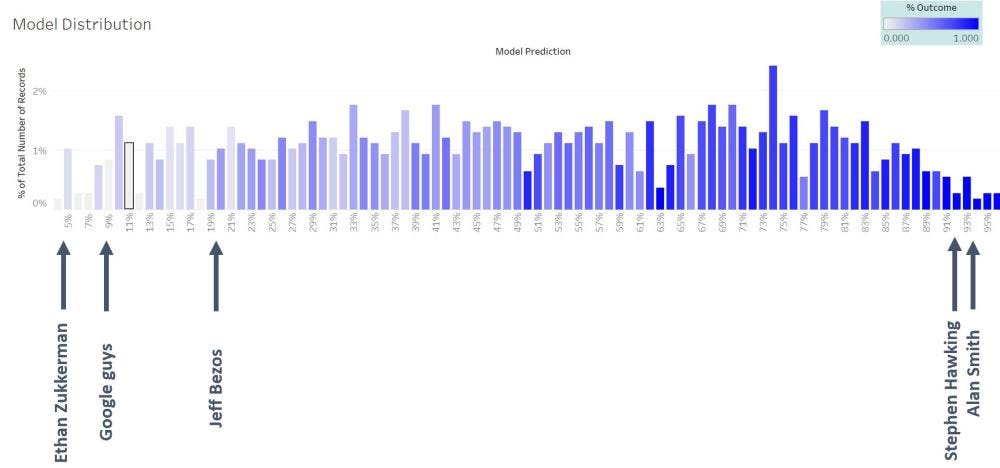
С помощью этой последней модели я также проверил самые высокие и самые низкие предсказанные оценки и проанализировал, как модели были ранжированы. здесь слева направо мы перешли от разговоров с плохой работой к лучшим (конечно, не пытаясь недооценить самые низкие оценки!).
- На моделях с самым низким рейтингом я обнаружил, что разговор Итана Цуккермана «Прислушиваясь к глобальным голосам» работает плохо. У этого были самые низкие оценки по каждой переменной (длительная продолжительность, быстрая речь, почти не было вопросов смеха).
- Ребята из Google Сергей Брин и Ларри Пейдж также получили довольно низкие оценки.
- Джефф Безос с докладом на тему «Электроэнергетическая метафора будущего Интернета» также получил более низкие оценки.
- Самый высокий балл получил модель Стивен Хокинг с докладом «Задавая вопросы вселенной». Этот доклад получил довольно высокие баллы по переменным модели с помощью того, что речь шла о том, чтобы задавать много вопросов, а также о медленной речи (поскольку вспомогательный голос довольно медленный!)
- Одним из флагманов хороших выступлений стал доклад Алана Смита на тему «Почему вам следует любить статистику». Это вселяет в меня надежду, что статистик может быть действительно хорошим оратором!
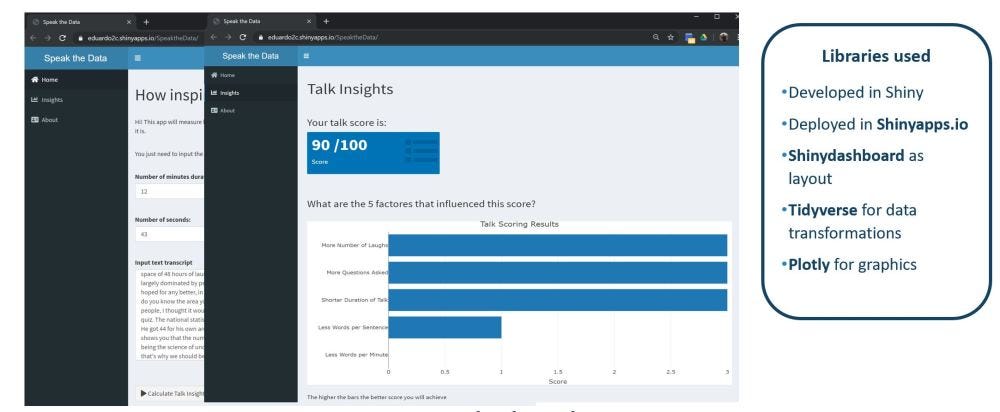
Теперь с разработанной моделью, почему бы не сделать ее доступной для всех! Я использовал Shiny и ShinyApps для развертывания онлайн-инструмента, который вы используете в разделе Анализируйте свое выступление на этом веб-сайте. Пожалуйста, следуйте инструкциям о том, что вам нужно сделать, это просто произнести речь и оценить, насколько хорошо она будет выступать, и что вы можете сделать, чтобы ее улучшить!
Что я узнал из этого проекта?
Я обнаружил, что есть факторы, которые могут помочь предсказать, станет ли выступление популярным, и они основаны на использовании таких слов, как задавать вопросы, говорить медленно, использовать юмор и быть кратким.
Я также узнал, что использование стороннего проекта на работе также может быть действительно забавным, а также экспериментировать и изучать новые темы науки о данных и о том, как лучше говорить!
У меня также была возможность дважды представить этот проект в Лондоне. Я представил его на конференции LondonR 25 июня 2019 года и на конференции EARL 2019 в Лондоне 11 сентября 2019 года. Вот несколько фотографий с мероприятий.


Ваше здоровье,
Эдуардо
Первоначально опубликовано на http://www.speakthedata.com 15 октября 2019 г.