Автор: Робби Нил, инженер-программист
TensorFlow предоставляет широкий спектр операций, которые значительно помогают в построении моделей из изображений и видео. Однако существует множество моделей, которые начинаются с текста, и построенные на их основе языковые модели требуют некоторой предварительной обработки, прежде чем текст можно будет ввести в модель. Например, Учебник по классификации текста, в котором используется набор IMDB, начинается с текстовых данных, которые уже были преобразованы в целочисленные идентификаторы. Эта предварительная обработка, выполняемая вне графика, может создавать перекос, если он отличается во время обучения и вывода, и требует дополнительной работы для координации этих этапов предварительной обработки.

TF.Text - это библиотека TensorFlow 2.0, которую можно легко установить с помощью PIP, и она предназначена для облегчения этой проблемы, предоставляя операторы для обработки предварительной обработки, регулярно обнаруживаемой в текстовых моделях, и другие функции, полезные для языкового моделирования, не предоставляемые ядром TensorFlow. Самая распространенная из этих операций - токенизация текста. Токенизация - это процесс разбиения строки на токены. Обычно эти токены представляют собой слова, числа и / или знаки препинания.
Каждый из включенных токенизаторов возвращает RaggedTensors с самым внутренним измерением токенов, отображаемых на исходные отдельные строки. В результате ранг получившейся фигуры повышается на единицу. Это проиллюстрировано ниже, но также просмотрите руководство по рваному тензору, если вы не знакомы с RaggedTensors.
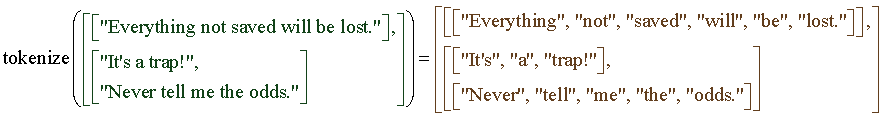
Токенизаторы
Изначально мы делаем доступными три новых токенизатора (как было предложено в недавнем RFC). Самый простой новый токенизатор - это токенизатор пробелов, который разбивает строки UTF-8 на пробельные символы, определенные ICU (например, пробел, табуляция, новая строка).
Первоначальный выпуск также включает токенизатор сценария Unicode, который разбивает строки UTF-8 на основе границ сценария Unicode. Скрипты Unicode - это наборы символов и символов, которые имеют исторически связанные языковые производные. Полный набор перечислений см. В разделе Значения UScriptCode в международных компонентах Unicode (ICU). Стоит отметить, что он похож на токенизатор пробелов, но наиболее очевидным отличием является то, что он отделяет знаки препинания USCRIPT_COMMON от языковых текстов (например, USCRIPT_LATIN, USCRIPT_CYRILLIC и т. Д.).
Последний токенизатор, представленный при запуске TF.Text, - это токенизатор словесного выражения. Это неконтролируемый текстовый токенизатор, который требует заранее определенного словаря для дальнейшего разделения токенов на подслова (префиксы и суффиксы). В моделях BERT широко используется словоформ.
Каждый из этих токенизирует строки в кодировке UTF-8 и включает параметр для получения байтовых смещений в исходной строке. Это позволяет вызывающей стороне узнать выравнивание байтов в исходной строке для каждого созданного токена.
Заключение
Это просто касается поверхности TF.Text. Наряду с этими токенизаторами мы также включаем операции для нормализации, n-граммы, ограничения последовательности для маркировки и многое другое! Мы рекомендуем вам посетить наш репозиторий Github и попробовать использовать эти операции при разработке собственной модели. Установка с PIP проста:
pip install tensorflow-text
А для более подробных рабочих примеров, пожалуйста, просмотрите наш Блокнот Colab. Он включает в себя множество фрагментов кода для многих новых операций, которые здесь не обсуждаются. Мы с нетерпением ждем продолжения этой работы и предоставления еще большего количества инструментов, которые сделают ваши языковые модели еще проще для создания в TensorFlow.