
Несбалансированные наборы данных распространены во множестве областей и секторов, и, конечно же, это включает в себя финансовые услуги. Специалисты по обработке данных сталкиваются с ними во многих контекстах - от мошенничества до безнадежных кредитов. Проблема возникает, когда алгоритмы машинного обучения пытаются идентифицировать эти редкие случаи в довольно больших наборах данных. Из-за несоответствия классов в переменных алгоритм имеет тенденцию относиться к классу с большим количеством экземпляров, к классу большинство, в то же время создавая ложное ощущение высокоточной модели. И неспособность предсказывать редкие события, класс меньшинства, и вводящая в заблуждение точность отвлекают от создаваемых нами прогностических моделей.
Проблема классового дисбаланса между большинством и меньшинством разочаровывает, но не является неожиданностью. Теперь мы обсудим основные приемы и методы, доступные при работе с этим типом данных. В конце этого поста вы найдете общие библиотеки и пакеты из Python и R, используемые для решения этой проблемы.
Что означает несбалансированный набор данных?
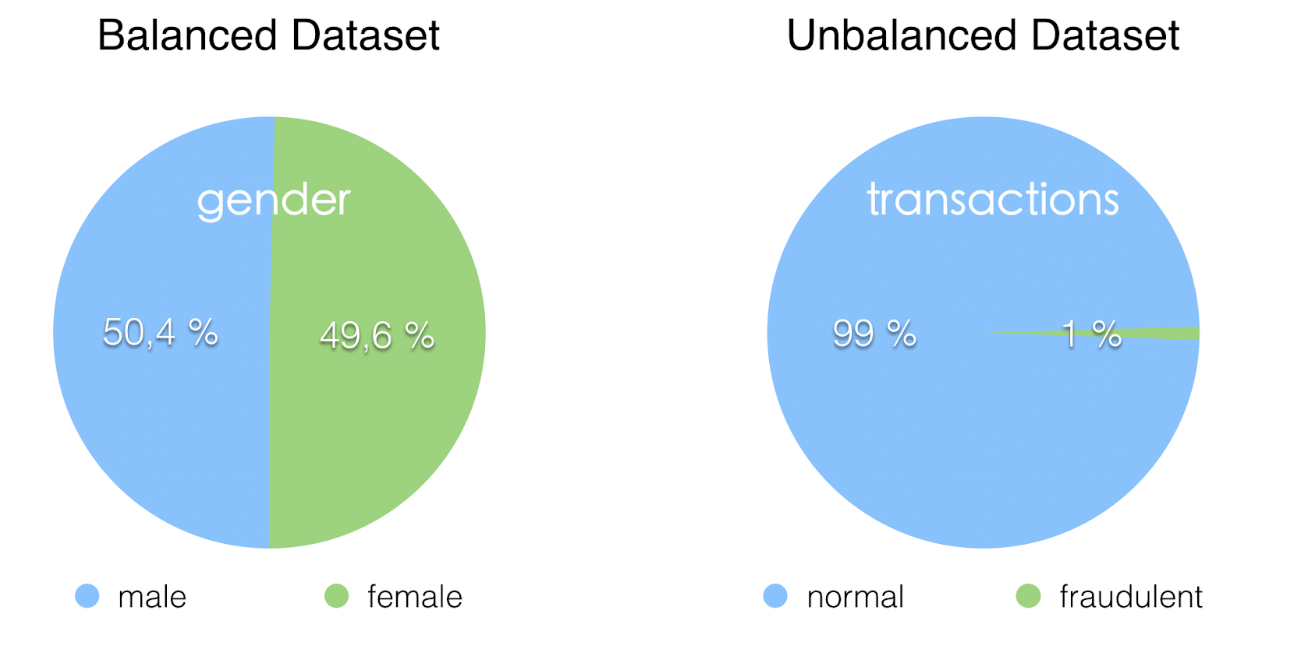
Проще говоря, несбалансированный набор данных - это тот, в котором целевая переменная имеет больше наблюдений в одном конкретном классе, чем в других.
Например, предположим, что у нас есть набор данных, используемый для обнаружения мошеннической транзакции. Если у нас есть бинарная целевая переменная (2 класса) - это 1, если транзакция является мошеннической, и 0, когда это не так, - нормально, если менее 1% наблюдений принадлежат к классу 1 (мошенничество), чем к классу 0 ( не мошенничество). В этом случае у нас очень несбалансированный набор данных.
Другой пример - целевая переменная с тремя классами, где 70% наблюдений относятся к 1-му классу, а 17% и 13% - ко 2-му и 3-му классам соответственно.
Вы можете подумать: «Хорошо, звучит просто, в чем проблема?».
Если ваша цель - использовать методы для кластеризации выборки в естественные группы или для описания взаимосвязи класса меньшинства с характеристиками (независимыми переменными), то это не создает «огромной» проблемы. Это становится проблемой только тогда, когда это «свойство» влияет на производительность алгоритмов или моделей, которые вы можете получить.
Если классы разделяются с использованием доступных функций, то распределение классов между ними не является проблемным.
Кроме того, проблема в том, что модели, обученные на несбалансированных наборах данных, часто дают плохие результаты, когда им приходится обобщать (предсказывать класс или классифицировать невидимые наблюдения). Несмотря на выбранный вами алгоритм, некоторые модели будут более восприимчивы к несбалансированным данным, чем другие. В конечном итоге это означает, что у вас не получится хорошая модель, и причины включают:
Алгоритм получает значительно больше примеров от одного класса, что побуждает его склоняться к этому конкретному классу. Он не узнает, что делает другой класс «другим», и не понимает лежащих в основе шаблонов, которые позволяют нам различать классы.
Алгоритм узнает, что данный класс более распространен, что делает его «естественным» для большей тенденции к нему. В этом случае алгоритм склонен к переобучению классу большинства. Просто предсказав класс большинства, модели получат высокие оценки по своим функциям потерь. В этих случаях возникает парадокс точности.
Какие шаги можно предпринять, столкнувшись с такой ситуацией?
1. Выполните повторную выборку набора данных:
- Недостаточная выборка. Идея состоит в том, чтобы уменьшить соотношение экземпляров на уровне большинства и меньшинства. Вы можете случайным образом выбрать наблюдения в желаемом соотношении - 50/50, 60/40 в двоичном случае или 40/30/30, если у вас три класса. В этом случае достаточно взять случайную выборку без замены. Вы можете выполнить информированную недостаточную выборку, посмотрев на распределение данных и выбрав наблюдения, которые нужно отбросить. В этом последнем случае вы можете сначала попробовать использовать метод кластеризации или k-NN (алгоритм k-ближайших соседей), чтобы получить набор данных с субдискретизацией. Этот набор данных включает наблюдения за каждой естественной группой данных внутри класса большинства. Таким образом, вы сохраните всю основную информацию в образце. В противном случае случайная понижающая выборка может выбрать все наблюдения одного типа, и вы потеряете ценную информацию из выборки. Во время повторной выборки вы можете попробовать разные соотношения, поскольку каждый класс не обязательно должен содержать одинаковое количество наблюдений.
- Передискретизация: вы можете создать синтетические наблюдения класса меньшинства на основе имеющихся данных. Некоторые алгоритмы, которые позволяют это сделать, включают вариационные автоэнкодеры (VAE), SMOTE (метод передискретизации синтетического меньшинства) или MSMOTE (метод модифицированной синтетической передискретизации меньшинства).
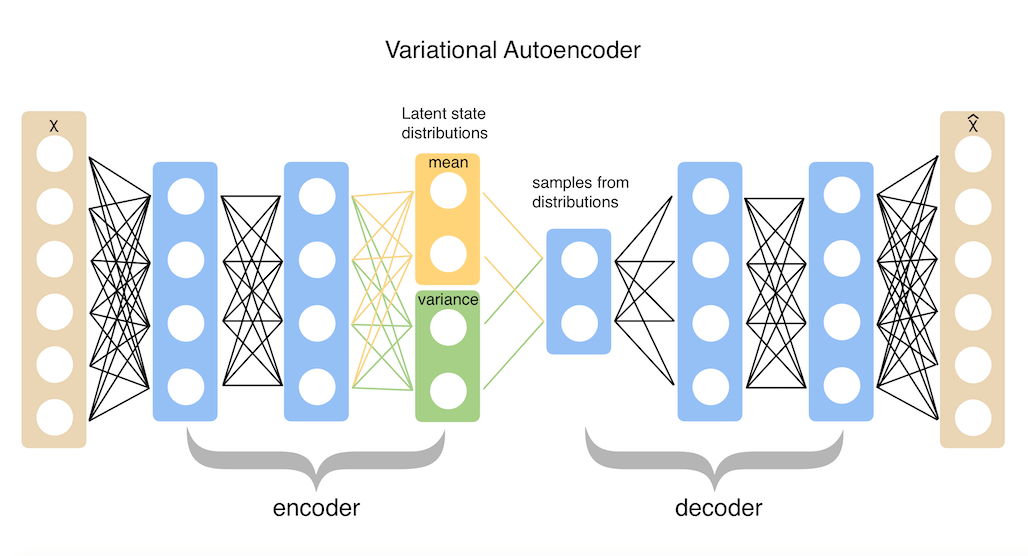
- VAE позволяет вам исследовать вариации ваших текущих данных не просто случайным образом, а в желаемом направлении. VAE - мощный метод для решения этой задачи. Теория доступна во многих ресурсах, но в целом сеть автокодировщика - это подключенные кодировщик и декодер. Кодировщик регистрирует входные данные и превращает их в более компактное и плотное представление. Сеть декодера использует это представление и преобразует его обратно в исходный вход. Стандартные автоэнкодеры учатся генерировать компактные представления и правильно реконструировать свои входные данные. Скрытое пространство, в которое они отправляют свои входные данные и где лежат их закодированные векторы, может не быть непрерывным или допускать простую интерполяцию. В случае VAE их скрытые пространства являются непрерывными по своей конструкции, что позволяет легко произвольно производить выборку и интерполяцию. Они достигают этого, создавая на выходе кодировщика не вектор кодирования, а два вектора: μ и σ. Это параметры гауссова распределения, из которого вы производите выборку, получаете закодированную выборку и затем передаете ее в декодер. Эта стохастическая генерация означает, что даже для одного и того же входа, хотя среднее и стандартное отклонения остаются неизменными, фактическое кодирование будет меняться на каждом проходе.
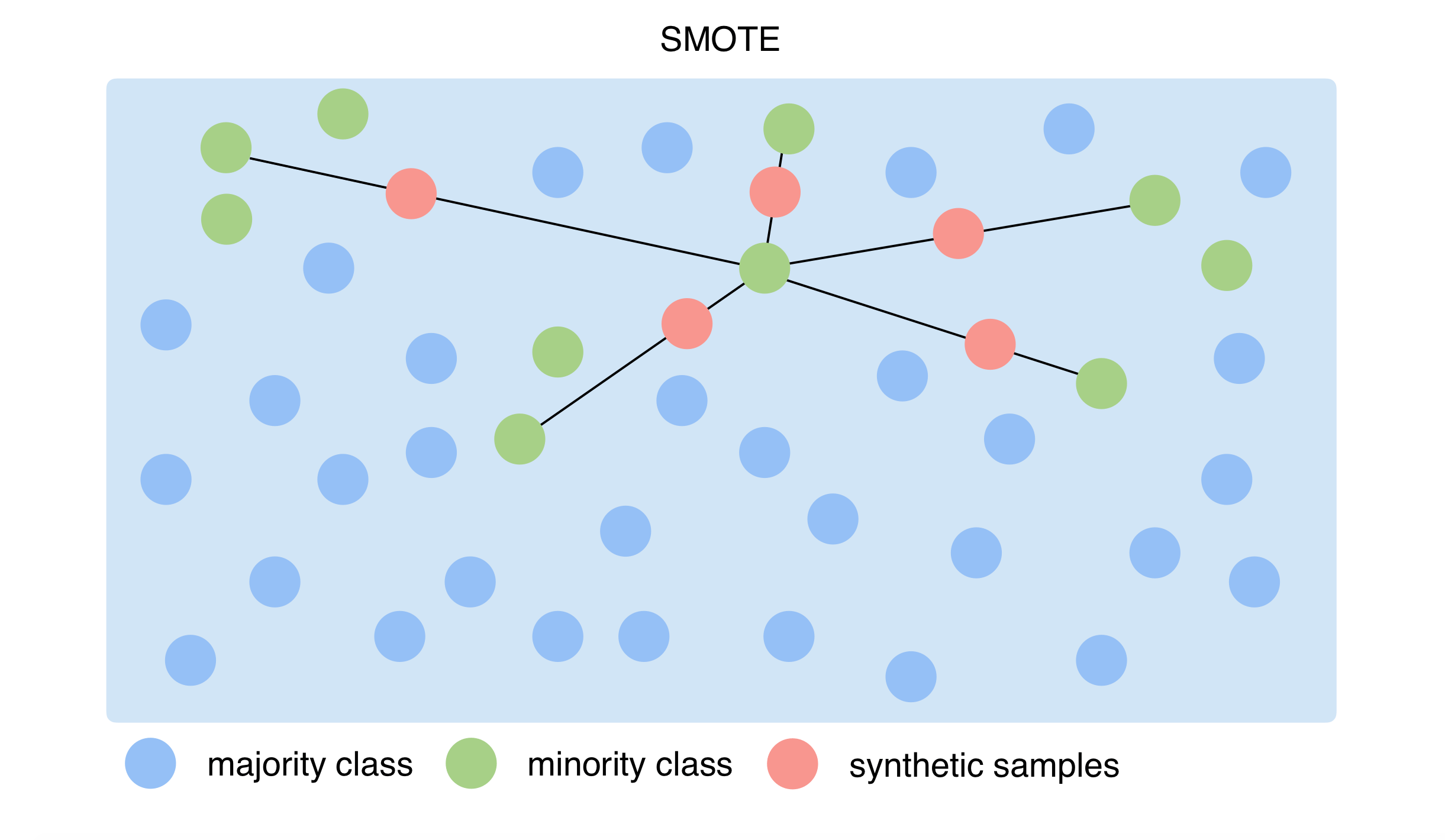
- Для SMOTE вы выбираете несколько наблюдений (20, 30 или 50, число можно изменить) и используете меру расстояния для синтетического создания нового экземпляра с теми же «свойствами» для доступных функций. Анализируя по одному объекту за раз, SMOTE учитывает разницу между наблюдением и его ближайшим соседом. Он умножает разницу на случайное число от нуля до единицы. Затем он определяет новую точку, добавляя случайное число к объекту. Таким образом, SMOTE не копирует наблюдения, а вместо этого создает новый, синтетический.
2. Соберите больше данных о классе меньшинства
Этот вариант кажется тривиальным, но он решает проблему, когда это применимо.
3. Используйте «адекватный» правильный алгоритм.
Некоторые алгоритмы более надежны, чем другие. Владение теорией, лежащей в основе каждого алгоритма, поможет вам понять их сильные и слабые стороны в различных ситуациях. Помните, что алгоритмы машинного обучения выбираются на основе входных данных и текущей задачи обучения.
4. Измените свой подход
Вместо создания классификатора иногда полезно изменить свой подход и масштаб; один из вариантов - проанализировать ваши данные с точки зрения «обнаружения аномалий». Затем вы можете применить от «SVM одного класса» к алгоритмам «Локальный фактор выброса (LOF)».
5. Используйте модели со штрафными санкциями.
У многих алгоритмов есть собственная штрафная версия. Обычно алгоритмы обрабатывают все неправильные классификации одинаково, поэтому идея состоит в том, чтобы наказывать неправильные классификации из класса меньшинства больше, чем большинства. Ошибки, допущенные во время обучения, влекут за собой дополнительные расходы (поэтому они называются классификаторами, чувствительными к затратам), но теоретически эти штрафы помогают модели улучшить внимание, уделяемое классу меньшинства. Иногда штрафы называют весами. Достижение правильной матрицы штрафов может быть трудным и иногда не очень помогает для улучшения результатов, поэтому попробуйте несколько схем, пока не найдете ту, которая лучше всего подходит для вашей ситуации.
Парадокс точности:
В несбалансированных наборах данных часто встречается «парадокс точности». Это происходит, когда вы используете метрику «точность», чтобы изучить лучшую модель.
Продолжим пример с данными об обнаружении мошенничества. Алгоритм захочет отнести 99% наблюдений к классу большинства, так как тогда точность модели будет выше 90%. Теоретически верно, что большинство наблюдений принадлежит классу большинства. На практике у вас нет хорошей модели; у вас есть модель, которая присваивает один и тот же класс всем наблюдениям и плохо обобщает.
Итак, какие показатели мы можем использовать, когда наши данные несбалансированы?
- Из матрицы неточностей мы можем вычислить (просто глядя на матрицу неточностей, мы можем получить проницательную информацию): чувствительность и специфичность, а также точность и отзыв
- F1-оценка (также F-оценка или F-мера): среднее гармоническое значение точности и отзывчивости.
- AUC (кривые ROC)
- Logloss
- Нормализованный показатель Джини (показатель Джини представляет собой просто переформулировку AUC: Джини = 2 × AUC − 1)
- Каппа: точность классификации, нормализованная несбалансированностью классов в данных.
Общие библиотеки и пакеты, используемые для решения этой проблемы
В Python одним из лучших вариантов является пакет для несбалансированного обучения:
Он включает методы передискретизации и передискретизации. Вы можете найти все параметры в документации API по указанной выше ссылке. Обратите внимание, что в нем есть утилиты для Keras и TensorFlow, а также есть функции для расчета некоторых показателей, которые обсуждались ранее.
import pandas as pd
import imblearn.under_sampling as under
from sklearn.datasets import load_breast_cancer
breast_cancer = load_breast_cancer()
pd.Series(breast_cancer.target).value_counts()
Out: 1 357
0 212
UnderSampling = under.ClusterCentroids(sampling_strategy={1:300, 0:212}, random_state=83, voting=’hard’)
x_resampled, y_resampled = UnderSampling.fit_resample(breast_cancer.data, breast_cancer.target)
pd.Series(y_resampled).value_counts()
Out: 1 300
0 212
При использовании пакета DMwR (интеллектуальный анализ данных с R) от R вы можете найти функцию SMOTE для применения описанного выше метода.
Другой вариант - функция ROSE (пакет имеет такое же имя). ROSE (Примеры случайной передискретизации) помогает при бинарной классификации при наличии редких классов. Он создает синтетическую и, вероятно, сбалансированную выборку данных, смоделированную с использованием подхода сглаженной начальной загрузки.
Пакет каретки включает такие полезные функции, как:
- downSample: произвольно выбирает набор данных, чтобы все классы имели ту же частоту, что и класс меньшинства.
- confusionMatrix: включает показатели из матрицы неточностей (чувствительность, специфичность, каппа, точность и т. д.).
library(‘DMwR’)
data(“iris”)
table(iris$Species)
Out : setosa versicolor virginica
50 50 50
x_smote <- SMOTE(Species~., iris, perc.over = 150, perc.under = 250, k=5)
table(x_smote$Species)
Out : setosa versicolor virginica
100 66 59