Прошло более 50 лет с тех пор, как Торонто Мэйпл Лифс выиграли Кубок Стэнли. Это результат перехода НХЛ от упорной игры и защиты к владению шайбой и мастерству. В настоящее время хоккейные звезды тренируются в межсезонье и обладают невиданными ранее в лиге навыками. Несмотря на эти новые таланты, хоккей по-прежнему считается одним из самых непредсказуемых видов спорта по сравнению с другими профессиональными спортивными лигами. Фактически, Vox film объяснил, почему хоккейные навыки не повышают вероятность победы команды. Исследователь Майкл Мобуссен описывает хоккей как вид спорта, наиболее близкий к случайности из-за сочетания небольшого размера выборки игр, небольшого количества голевых моментов в игре и распределения времени на льду между всеми игроками.

Видео заставило меня задуматься, можно ли количественно оценить удачу и мастерство? В настоящее время НХЛ отслеживает как расширенную, так и прямую статистику как для команд, так и для игроков. Итак, я решил использовать свою специальность по статистике и недавнюю стажировку в области науки о данных, чтобы предсказать исход игр НХЛ с большей вероятностью, чем бросание орла с честной монетой. В конце концов, я приехал в Уотерлоо не для того, чтобы пить молоко! Идея также возникла из The Athletic и их аналитически написанных статей, которые я люблю читать.
Метод
На высоком уровне машинное обучение, подмножество искусственного интеллекта, представляет собой набор методов, позволяющих компьютерам повышать производительность в конкретных задачах, используя данные, а не запрограммированные явно. Если это было полным ртом, то полезный пример, иллюстрирующий это, - определение спам-сообщений. Решением может быть создание вручную инструкций, определяющих, как следует обрабатывать каждое сообщение на основе функций, которые считаются важными. Например, если сообщение содержит «наследование» или «принц», оно будет помечено как спам. Другое решение - использовать данные, чтобы определить, какие функции можно использовать для выявления спама. Это достигается за счет использования классификатора машинного обучения, который автоматически распознает похожие функции в сообщениях.

Точно так же тот же набор методов можно использовать для прогнозирования исхода игр НХЛ. Задача прогнозирования игр НХЛ - это задача бинарной классификации. Другими словами, имея набор данных, мы пытаемся узнать, как потреблять новые экземпляры, и определить, к какому классу они принадлежат. Например, получив новое сообщение, мы делаем вывод, спам это или нет, или учитывая хоккейный матч, какая команда выиграет или проиграет. Для успешного определения класса экземпляра требуются помеченные данные. То есть известно, что каждое сообщение является спамом или нет, и известен победитель каждого хоккейного матча. Затем, основываясь на экземплярах и функциях в нашем наборе данных, мы пытаемся различать классы. Формально этот процесс называется построением классификационной модели. Получив модель классификатора, мы тестируем ее на новых экземплярах, чтобы предсказать цель (т.е. попытаться классифицировать будущие хоккейные игры по их исходу). Таким образом, мы можем оценить, насколько правильно и неверно модель предсказывала игры (подробнее об этом в разделе «Результаты»).
Для этого проекта я выбрал комбинацию из 15 прогнозируемых хоккейных статистик для своего набора функций. Включенные функции для каждой соответствующей команды:
- идентификатор команды,
- цели для,
- голы против,
- разница мячей,
- победную серию,
- дивизия стоя,
- конференц-стоя,
- положение в лиге,
- коэффициент успешной игры в большинстве,
- уровень успеха power kill,
- процент выстрелов,
- сохранить процент,
- процент побед вбрасываний,
- Фенвик закрывает процент и,
- PDO
Для тех, кто интересуется, процент закрытия Фенвика, возможно, является одним из лучших приближений для измерения владения шайбой. Современная НХЛ - это гораздо больше игры с владением шайбой, чем это было пару десятилетий назад. Таким образом, очевидно, что команда, у которой шайба чаще всего, будет направлять больше ударов по воротам соперника, чем наоборот. PDO рассчитывает процент попаданий плюс процент спасбросков и, как известно, является адекватной мерой удачи в игре. Согласно хоккейным статьям, эта статистика сильнее коррелирует с выигранными хоккейными играми по сравнению с другой статистикой.

Обработка данных
Все использованные данные были получены через NHL API и NHL.com. Я перенес матчи с 2005–06 до начала сезона 2018–2019 и исключил предсезонки и игры плей-офф. Во время предсезонных игр игроки должны наладить отношения с новыми товарищами по команде и одноклубниками, принять новую командную стратегию и набраться выносливости. С другой стороны, плей-офф создает нерепрезентативную совокупность команд, что искажает распределение статистики команд. В играх плей-офф ставки также выше, чем в играх регулярного сезона (да!).
Машинное обучение
Обычно обучающие данные делятся на наборы: обучающий набор и тестовый набор, который не используется для обучения. Возьмем, к примеру, ребенка, который учится различать модели автомобилей. Если повторять одни и те же картинки, ребенок добьется нереально хороших результатов! Ребенок может только классифицировать модели автомобилей на изображениях и совершенно не справится с новыми моделями автомобилей. Вместо этого изображения разбиты на две стопки. Ребенку дается одна стопка для разборки. Пока ребенок подбирает коллекцию изображений, он обучает мысленный классификатор тому, как предсказывать модели автомобилей. Как только первая стопка собрана, ребенок использует то, что они выучили, для обозначения другой «новой» коллекции изображений. Выполнив эту задачу, мы можем проверить, насколько хорошо ребенок классифицирует модели автомобилей и предоставляет новые изображения, что позволит ребенку построить лучший классификатор.
Перед построением классификатора хорошо обеспечить равномерное распределение классов. В нашем случае примерно 50%. Напомним, что классы 0 представляют проигранную команду хозяев, а 1 - победу команды хозяев. Затем я проверил, нет ли недостающих значений. Их необходимо решать, поскольку некоторые классификаторы по-разному обрабатывают пропущенные значения. К счастью, в наших хоккейных данных нет недостающих данных. Еще одна хорошая проверка - это независимость между независимыми переменными. На этом шаге отображаются любые статистические данные, которые могут быть ненужными. Например, разница между целями, целями и противостоянием зависят друг от друга. Тем не менее, я решил оставить их, потому что необработанные данные иногда дают больше информации. Последняя проверка - убедиться, что размер набора данных достаточен. У нас есть 30 прогнозных функций (по 15 на каждую команду). Эмпирическое правило - 50 записей на объект; следовательно, нам нужно иметь как минимум 1500 записей в наборе данных, что верно. Теперь мы можем двигаться дальше, чтобы подогнать наши модели.
Модели

Я решил проверить шесть алгоритмов классификации.
Логистическая регрессия
Определение: в этом алгоритме вероятности, описывающие возможные результаты одного испытания, моделируются с использованием логистической функции.
Преимущества: логистическая регрессия предназначена для этой цели (классификации) и наиболее полезна для понимания влияния нескольких независимых переменных на одну переменную результата.
Недостатки: работает только тогда, когда прогнозируемая переменная является двоичной, предполагает, что все предикторы независимы друг от друга, и предполагает, что данные не содержат пропущенных значений (удачно для нас!).
Наивный байесовский
Определение: Наивный алгоритм Байеса основан на теореме Байеса с предположением независимости между каждой парой функций. Наивные байесовские классификаторы хорошо работают во многих реальных ситуациях, таких как классификация документов и фильтрация спама.
Преимущества: для этого алгоритма требуется небольшой объем обучающих данных для оценки необходимых параметров. Наивные байесовские классификаторы чрезвычайно быстры по сравнению с более сложными методами.
Недостатки: известно, что наивный байесовский метод плохой оценки.
K-Ближайшие соседи
Определение: Классификация на основе соседей - это тип пассивного обучения, поскольку он не пытается построить общую внутреннюю модель, а сохраняет только экземпляры обучающих данных. Классификация вычисляется простым большинством голосов k ближайших соседей каждой точки.
Преимущества: этот алгоритм прост в реализации, устойчив к зашумленным обучающим данным и полезен, если обучающие данные значительны.
Недостатки: необходимо определить значение K, а стоимость вычислений высока, так как необходимо вычислить расстояние от каждого экземпляра до всех обучающих выборок.
Деревья решений
Определение: учитывая набор атрибутов вместе с их классами, дерево решений создает последовательность правил, которые могут использоваться для классификации данных.
Преимущества: дерево решений просто для понимания и визуализации, требует небольшой подготовки данных и может обрабатывать как числовые, так и категориальные данные.
Недостатки: дерево решений может создавать сложные деревья, которые плохо обобщаются, а деревья решений могут быть нестабильными, поскольку небольшие изменения в данных могут привести к созданию совершенно другого дерева.
Случайный лес
Определение: Классификатор случайного леса - это метаоценка, которая соответствует некоторым деревьям решений на различных подвыборках наборов данных и использует среднее значение для повышения точности прогноза модели и контроля избыточной подгонки. Размер подвыборки всегда совпадает с размером исходной входной выборки, но выборки отбираются с заменой.
Преимущества: Сокращение избыточной подгонки и случайного классификатора лесов в большинстве случаев более точное, чем деревья решений.
Недостатки: медленное прогнозирование в реальном времени, сложность в реализации и сложный алгоритм.
Машина опорных векторов
Определение: машина опорных векторов - это представление обучающих данных в виде точек в пространстве, разделенных на категории очевидным зазором, который является как можно более широким. Затем новые примеры отображаются в том же пространстве и предсказываются как принадлежащие к классу в зависимости от того, с какой стороны пропасти они попадают.
Преимущества: эффективен в пространствах большой размерности и использует подмножество обучающих точек в функции принятия решения, поэтому он также эффективен с точки зрения памяти.
Недостатки: алгоритм не дает напрямую оценок вероятностей, они рассчитываются с использованием дорогостоящей пятикратной перекрестной проверки.
Полученные результаты

Есть два способа измерить, насколько хорошо работает наша модель: точность и F1-Score. Чтобы лучше объяснить эти концепции, я воспользуюсь классификатором SeeFood Цзянь Яна, который он построил на основе Кремниевой долины HBO.
Точность: (истинно положительный + истинно отрицательный) / (истинный положительный + ложноположительный + истинно отрицательный + ложноотрицательный)
- Точность - это отношение правильно спрогнозированных наблюдений к общему количеству наблюдений. Это наиболее интуитивно понятный способ измерения производительности.
- Истинный минус: классификатор изображений «хот-дог» и «не хот-дог» правильно классифицировал изображение автомобиля как не «хот-дог».
- Ложноотрицательные результаты: классификатор изображений «хот-дог» и «не хот-дог» неправильно классифицировал изображение испорченного «хот-дога» как не «хот-дог».
- Истинные плюсы: классификатор «хот-дог» и «не хот-дог» правильно классифицирует «хот-дог» как «хот-дог».
- Ложные срабатывания: классификатор «хот-дог» и «не хот-дог» неправильно классифицирует гамбургер как «хот-дог».

F1-Score: (2 x точность x отзыв) / (точность + отзыв)
- F1-Score - это средневзвешенное значение точности и отзыва. Таким образом, эта оценка учитывает как ложные срабатывания, так и ложные отрицательные результаты. Обычно это более полезно, чем точность, особенно если у нас неравномерное распределение классов.
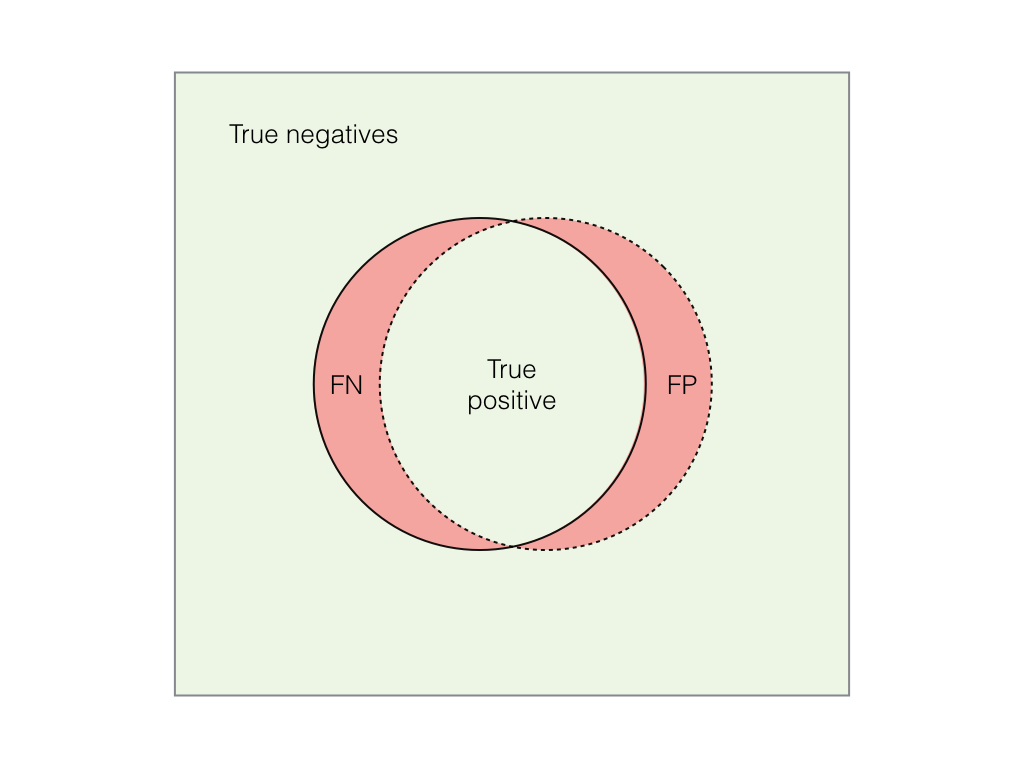
- Высокая степень запоминания, низкая точность: классификатор считает многие вещи «хот-догами»; ноги на пляжах, картошка фри и еще много чего. Однако он также считает, что многие «хот-доги» - это «хот-доги». Итак, из набора изображений есть много изображений, классифицированных как «хот-доги», многие из них входили в набор настоящих «хот-догов», однако многие из них также были «не хот-догами».
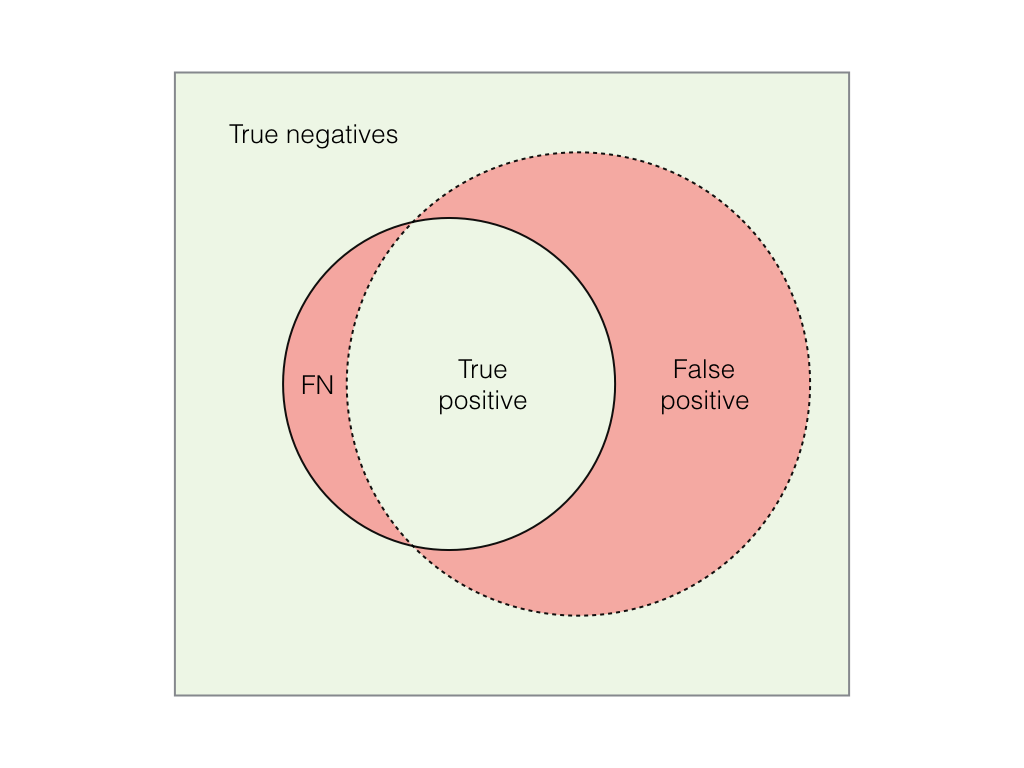
- Низкая запоминаемость, высокая точность: классификатор очень разборчив и не считает многие вещи хот-догами. Все изображения, которые он считает «хот-догами», на самом деле являются «хот-догами». Однако он также пропускает много настоящих «хот-догов», потому что он очень разборчивый. Низкий уровень отзыва, но очень высокая точность.

- Высокая запоминаемость, высокая точность: классификатор отличный, он очень разборчивый, но все же почти все изображения «хот-догов», которые являются «хот-догами», корректны. Мы счастливы!
После того, как вы усвоили вышеуказанное, вот краткое представление о том, как работает каждый классификатор.
- Логистическая регрессия достигла наивысшего F1-Score 67% с точностью 67%.
- Наивный Байес получил оценку F1 в 65% при соответствующей точности
- KNN имел 58% F1-Score и показатель точности.
- Деревья решений имели показатель F1 62% при точности 58%.
- Random Forest дал 65% F1-Score и 64% точности.
- SVM получил жалкий F1-Score 41% с оценкой точности 56%.
И еще немного удобоваримой статистики.
- Логистическая регрессия:
When home team wins, classifier predicts they win 71.62% of the time When home team loses, classifier predicts they win 39.40% of the time When home team loses, classifier predicts they lose 60.60% of the time When classifer predicts home team wins, home team actually wins 70.07% of the time When classifer predicts home team loses, home team actually loses 62.38% of the time
- Наивный байесовский
When home team wins, classifier predicts they win 64.50% of the time When home team loses, classifier predicts they win 34.49% of the time When home team loses, classifier predicts they lose 65.51% of the time When classifer predicts home team wins, home team actually wins 70.66% of the time When classifer predicts home team loses, home team actually loses 58.89% of the time
- KNN
When home team wins, classifier predicts they win 61.30% of the time When home team loses, classifier predicts they win 47.31% of the time When home team loses, classifier predicts they lose 52.69% of the time When classifer predicts home team wins, home team actually wins 62.53% of the time When classifer predicts home team loses, home team actually loses 51.39% of the time
- Древо решений
When home team wins, classifier predicts they win 64.25% of the time When home team loses, classifier predicts they win 40.19% of the time When home team loses, classifier predicts they lose 59.81% of the time When classifer predicts home team wins, home team actually wins 67.31% of the time When classifer predicts home team loses, home team actually loses 56.50% of the time
- Случайный лес
When home team wins, classifier predicts they win 64.37% of the time When home team loses, classifier predicts they win 35.60% of the time When home team loses, classifier predicts they lose 64.40% of the time When classifer predicts home team wins, home team actually wins 69.96% of the time When classifer predicts home team loses, home team actually loses 58.39% of the time
Для более детального ознакомления с результатами посетите репозиторий проекта на Github.
Будущая работа
Когда я начинал этот проект, у меня была цель предсказать исход игры НХЛ с вероятностью выше 50%. Я достиг этой цели. Однако я уверен, что опытные хоккейные аналитики могут с большей уверенностью предсказать результат хоккейного матча. С учетом сказанного, в мой текущий классификатор можно внести улучшения и дополнения, которые я могу добавить к нему.
Сначала я бы оптимизировал набор функций. Выбор функций перед моделированием данных дает множество преимуществ, в том числе:
- Уменьшение переобучения: меньше избыточных данных означает меньше возможностей для принятия решений на основе шума.
- Повышение точности: уменьшение количества вводящих в заблуждение данных означает повышение точности моделирования.
- Сокращение времени обучения: меньше данных означает, что алгоритмы обучаются быстрее.
Другие улучшения, которые должны быть включены в мой классификатор, - это более продвинутая статистика и качественные функции. Например, включение сырых данных о последних десяти играх команды, чтобы оценить, насколько хорошо они играли в последнее время. Используя предыдущие десять игр команды (например, 7–3–0), мы пренебрегаем ценной информацией о том, как команда выступила. Возьмем, к примеру, команду, которая играла хорошо, но проиграла в сверхурочное время, команду, которая играла против сильной команды и проиграла, или команду, которая играла плохую команду и выиграла из-за удачного отскока.
Последнее улучшение, над которым я сейчас работаю, - это включение прогнозов веб-сайтов по ставкам на спорт. Для тех, кто заинтересован, веб-сайт сравнивает свои результаты со спортивными книгами Вегаса за весь сезон, используя метрику Log Loss. Эти веб-сайты являются отличной базой для использования при размещении ставок, что позволяет им работать ближе к Вегасу. К факторам, которые они включают, относятся: фактор заправки в конце сезона, расширенный анализ травм (влияние нападения / защиты), индивидуальные результаты, химия линий и погода. Включение этих статистических данных должно обеспечить более высокий результат в Формуле 1 и, возможно, появление в качестве гостя на Hockey Night в канадском антракте, эфирное время в Prime Time Sports с Бобом Маккауном или в Gambling Corner RA на Spittin ’Chiclets.
В конце концов, я хотел бы предсказать потенциальные перспективы и их успех в НХЛ. Однако прогнозировать перспективы сложно, поскольку многие факторы играют роль в их прогрессе, включая их выступления, где они играли, с кем играли, кто их тренировал и когда они родились. Кроме того, мы должны определить, что такое успешная перспектива. Есть ли хорошие перспективы у тех, кого призывают в армию? К исключениям относятся Мартин Сент-Луис, который не был призван, но сделал легендарную карьеру, и те, кто был призван, но не играл в матчах НХЛ. Должны ли успешные игроки НХЛ сыграть определенное количество игр НХЛ, забить минимальное количество голов или подписать многолетний многомиллионный контракт? Без сомнения, прогнозировать перспективы, как это делают скауты, сложно, учитывая, что мы не обладаем тем же опытом, который они приобрели за время своей работы.
ЛИСТЫ ИДТИ!
Спасибо тем, кто дочитал до этого места, или тем, кто прокрутил статью до конца, чтобы узнать, сколько она длится. Мир на востоке!

Особая благодарность журналу Analytics India Magazine и @klintcho за их полезные объяснения.