Если вы ищете похожие темы, вы можете получить некоторую информацию в этом посте, не стесняйтесь общаться и обсуждать со мной, чтобы учиться вместе. Полные коды будут предоставлены по запросу. Эта статья написана для обобщения моего собственного мини-проекта. Мои основные цели — продемонстрировать результаты и кратко обобщить концептуальный поток, чтобы закрепить мое обучение. Это не учебное пособие для людей с нулевым опытом. Я не буду вдаваться в подробности о КАЖДОЙ технике, которую я использовал, потому что существует МНОЖЕСТВО хорошо документированных руководств. Я не хочу создавать руководство, перефразируя и обобщая их шедевры без дополнительных значений.

Я лично предпочитаю Pytorch Keras при создании моделей, связанных с CNN, из-за его более высокой гибкости в настройке. Кроме того, создание модели pytorch требует более глубокого понимания архитектуры модели, что полезно для понимания концепции. Keras очень прост в использовании и удобен, иногда мы можем пропустить некоторые важные концепции обучения.
Сверточная база CNN может извлекать признаки из тензора входного изображения. У нас нет контроля над тем, какие функции будут выбраны, поскольку это решает CNN, как операция черного ящика. Эти функции включают функции содержимого (которые говорят вам о содержании изображения) и функции стиля (например, цвет/текстура) изображения. Что произойдет, если мы возьмем элемент содержания изображения А и объединим его со стилем изображения Б? Будет ли он создавать изображение с содержанием A, но отображать стиль B?
Думать о:
- Как извлечь функции контента и функции стиля по сверточной основе? Будут ли ранние слои извлекать ту же информацию, что и более поздние слои? Какой слой выбрать?
- Как определить метрики потерь и обратное распространение?
Обычно есть два основных подхода к переносу стиля: мы можем обновить тензор входного изображения или параметры модели. Сначала я пробую подход, изложенный в вводном курсе Udacity pytorch, который заключается в обновлении тензора изображения.
1. Загрузите изображение
Цель состоит в том, чтобы преобразовать изображение содержимого и изображение стиля в тензор для подачи в нашу CNN. Зависит от ваших предпочтений, чтобы решить, какое преобразование необходимо. Я предлагаю использовать модуль преобразования PIL и pytorch.
2. Создайте средство извлечения признаков
Я использую предварительно обученную модель vgg19, которая соответствует оригинальной статье. Мы выбираем только сверточную базу и устанавливаем для require_grad значение False, потому что нам нужна только часть извлечения признаков, и мы не собираемся обновлять значения веса фильтра.

3. Извлеките карту объектов в определенные слои
Создайте функцию для извлечения конкретных карт функций, передающих vgg19, можно рассмотреть возможность использования цикла и метода model._modules.items(). Я учусь создавать словарь для хранения значений карты объектов для более удобного сопоставления позже. Здесь мы должны решить, какие слои использовать для нашей модели переноса стиля. Я следую оригинальной бумаге и фиксирую эти слои
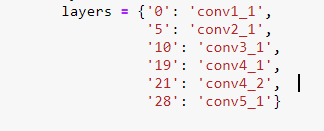
Передайте наш контент img тензор и стиль img тензор в функцию, чтобы получить вышеуказанные слои объектов в форме dict. Сопоставьте определенные слои из векторных слоев стиля img с другим словарем для последующего расчета матрицы Грама.
4. Матрица Грамма
Ничего особенного, просто torch.mm(tensor, tensor.t()).
5. Подготовьте выходное изображение
Мы можем считать, что просто клонируем тензор содержимого img в качестве исходного выходного img, поскольку наша цель — изменить стиль изображения, но сохранить содержимое. Конечно, мы можем использовать случайный тензор в качестве выходного изображения, но потребуется гораздо больше времени, чтобы обучить его от шума к содержанию.
6. Определите потерю
Выберите слой карты объектов для расчета потери контента. В оригинальной статье был выбран [‘conv4_2’], поэтому мы можем следовать его подходу. Для потери стиля это немного сложно. Каждая карта объектов по-разному вносит свой вклад в окончательную матрицу граммов, поэтому мы должны создать весовой коэффициент для каждого слоя при расчете окончательной матрицы граммов. Опять же, мы можем поместить всю эту информацию в словарь для упрощения отображения.

Полная потеря = потеря контента + потеря стиля
Вообще говоря, поскольку потери контента и потери стиля рассчитываются в разных режимах, их абсолютное значение потерь может быть в разных масштабах. Мы не хотим, чтобы в убытке преобладал один фактор, поэтому обычно добавляют весовой коэффициент. В зависимости от того, хотите ли вы, чтобы на выходе img hv было больше или меньше контента, вы можете выбрать другое соотношение. В документах нам сообщалось, что соотношение потери контента к потере стиля составляет 1:1e6.
7. Оптимизатор и обучение
Я выбираю Адама, так как это всегда мой первый оптимизатор. Мы можем рассмотреть оптимизатор LBGFS, потому что, согласно статье, он кажется лучшим оптимизатором в этой ситуации. Важно отметить, что мы оптимизируем output_img вместо model.parameters(). Первоначально я не знал об этом и привел к некоторой концептуальной ошибке.
Выберите гиперпараметры, которые вам нравятся. Я выбираю шаг=4000, lr=0,003. На самом деле около шага = 2xxx целевой img уже «преобразован», более поздний шаг не внес большого вклада.
8. Вот результаты






Исходное изображение имитирует the_scream. Давайте еще немного подтолкнем его

Некоторые моменты, на которые следует обратить внимание:
- Этот подход тренирует выходной тензор изображения, а не параметры модели. Первоначально после обучения передаче в стиле starry_night я сохраняю модель факела и ожидаю, что она может дать мне немедленный результат при применении того же исходного входного тензора, но этого никогда не происходит. Я пытаюсь сравнить значение веса до и после тренировки, много сохранять и загружать, но все равно не получается. Позже я, наконец, понял, что концептуальная ошибка заключается в том, что я просто обновляю выходное изображение в оптимизаторе, сохраняя модель факела, сохраняя только значение параметра модели. Поэтому, что бы я ни делал, я не могу сохранить результат и повторно использовать его в этой архитектуре модели.
- Чтобы иметь возможность повторно использовать модель и применить мгновенный перенос стиля к входному изображению, мы должны построить модель, оптимизирующую параметры модели. Для этого модель и обучающая часть усложняются, а не являются одним изображением контента. Нам нужно подготовить набор данных, хорошим выбором будет набор данных COCO. Тогда модель является не только частью извлечения признаков VGG, но также имеет часть преобразования изображения. На этот раз мы оптимизируем параметры модели. Интуитивно говоря, мы извлекаем функции с помощью vgg, а затем также узнаем, как изображение преобразуется из шума в наше целевое изображение. Как только модель узнает, как выполнять преобразование, ее можно применить к любому новому входному тензору, чтобы получить результат, имеющий тот же стиль.
- Я обязательно построю вышеуказанную модель и попробую этот подход. Я уже нашел несколько руководств и кодов, но на данный момент не хватает времени, так как меня больше интересует GAN. Надеемся, что к концу этого месяца этот подход будет обновлен.