
Недавно я заинтересовался тем, как ядра изображений и операции свертки участвуют в обработке изображений. По общему признанию, это связано с его популярностью на веб-сайтах социальных сетей и в таких приложениях, как Snapchat и Instagram. Многие из фотографий, которые находятся в ранее упомянутых приложениях, используют эффекты, которые стали возможными благодаря изменению значений пикселей изображения, и операции используются для внесения желаемых изменений в изображение.
Обработка изображений имеет множество различных приложений, включая дополненную реальность, классификацию текста, обнаружение объектов и т. д. Причина огромного взрыва количества возможных приложений для обработки изображений связана с последними разработками, которые были представлены исследователями в области глубокого анализа. обучение. Нейронные сети способны обрабатывать широкий спектр различных входных данных и представлять прогноз на основе серии вычислений.
Что такое операции свертки?

Прежде чем обсуждать операции свертки, необходимо упомянуть аффинные преобразования, поскольку они обеспечивают основу для операций свертки (Дюмулен, 2018). Аффинные преобразования используются для изменения значения вектора через матрицу, называемую ядром, набор значений которой может быть либо предопределен, либо получен. Эти преобразования полезны при изменении ориентации или положения вектора. Однако ограничение аффинных преобразований заключается в том, что они не используют преимущества определенных свойств, доступных ядру во входных данных, таких как цветовые или направленные каналы. Используя ранее упомянутые свойства, операции могут помочь решить задачу более эффективно, уменьшив объем необходимой обработки.
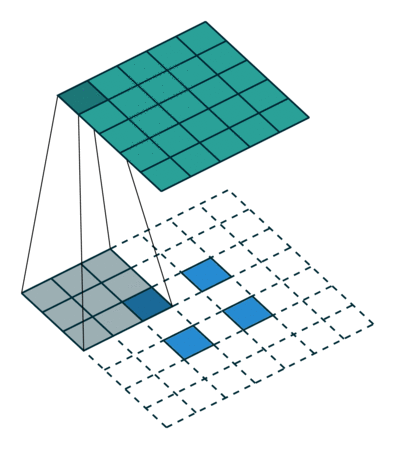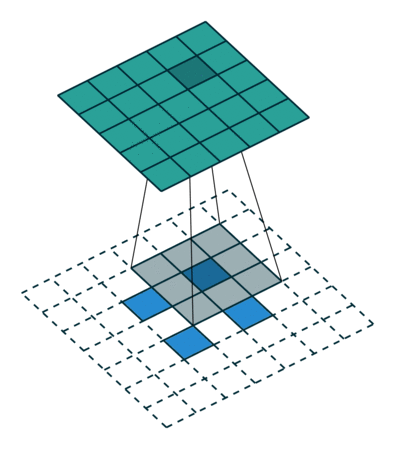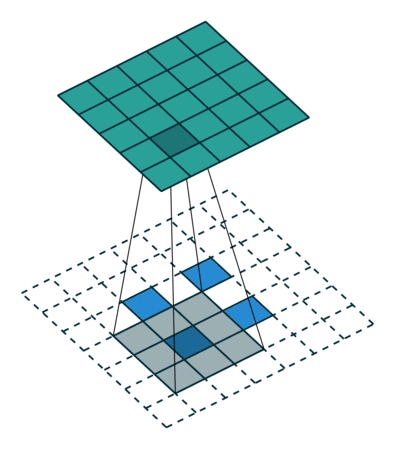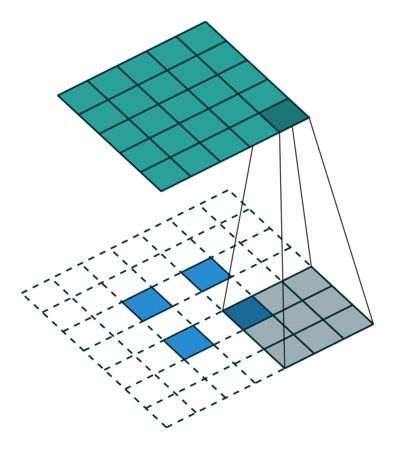
Здесь в игру вступают операции свертки. Операции свертки требуют аффинных преобразований и позволяют эффективно применять их к входным данным с высокой степенью размерности или большим разнообразием, таким как изображения, видео и звуковые байты. Как показано на рисунке 2, операции свертки используются для упрощения больших наборов данных путем сжатия входных данных с помощью ряда операций (серии умножений и сложений). Как и в случае с аффинными преобразованиями, операции свертки используют ядро для изменения входных данных. Это достигается путем умножения значений ввода на значения ядра. Сумма получается путем сложения значений серии умножений, выполненных на первом шаге операции. При последовательном выполнении эти вычисления приводят к меньшему набору значений, которые все содержат набор входных значений в сжатом наборе.
Связаны ли сверточные нейронные сети (CNN) и операции свертки?

При обсуждении операций свертки невозможно не упомянуть CNN. CNN использовались еще в начале 90-х для распознавания рукописных символов. Группа исследователей смогла обучить нейронную сеть распознавать рукописные символы, сначала разделив их, а затем пометив (Le Cun, 1995). Возможности нейронной сети резко расширились, когда CNN была использована для победы над системой классификации ImageNet в конкурсе (Крижевский, 2014). Причина, по которой CNN являются одной из наиболее желанных сетей для использования специалистами по машинному обучению, заключается в том, что действие, подобное сжатию, выполняется серией операций свертки. Это позволяет модели делать прогнозы на основе сжатых входных данных. В результате на обучающие модели тратится меньше времени, поскольку входные данные были упрощены или сжаты.
На рис. 3 показана типичная конструкция CNN. Во-первых, в качестве входных данных может использоваться изображение или аудиофайл, имеющие несколько измерений (желтые кружки). Затем будет выполнен ряд операций свертки, чтобы упростить или «свернуть» входные данные по ряду слоев (розовые кружки) и передать выходные данные серии операций свертки в нейронную сеть. Нейронная сеть, которая анализирует свернутые выходные данные, обычно представляет собой нейронную сеть с прямой связью согласно Ван Вину (зеленые кружки).
Как вы оцениваете эффективность CNN?
После того, как модель нейронной сети построена, она использует большой набор данных для прямого и обратного распространения по нему и изменения связей между каждым узлом сети, чтобы приблизиться к максимально возможной точности. Модель оценивает точность прогнозов с помощью метода, называемого матрицей путаницы.
Четыре раздела матрицы путаницы:
Матрица путаницы представляет собой матрицу 2 x 2, которая используется для расчета точности прогноза модели. Четыре части матрицы — это истинные и ложноположительные и истинные и ложноотрицательные результаты. Из этих четырех значений; точность, точность, а также охват положительных и отрицательных случаев могут быть возвращены. Значения получаются путем взятия значений из матрицы и использования формул.
Как обучается модель.
Входные данные разбиваются на два разных набора: тестовый и обучающий. Для обучения модели можно использовать любое соотношение, но использование 80% набора данных в качестве обучающего набора является наиболее популярным подходом. Это можно выполнить с помощью API-вызова train_test_split() из библиотеки Python sklearn. Разделение набора данных позволяет сети использовать данные, которые она ранее не видела, чтобы повысить точность своих прогнозов и предотвратить переоснащение. Переобучение — это проблема, вызванная обучением узлов в нейронной сети одними и теми же данными, что приведет к потере точности при столкновении с незнакомыми проблемами.
Как еще больше повысить точность сети:
это можно сделать с помощью перекрестной проверки, методологии разделения набора данных, позволяющей проводить обучение и тестирование по всему набору. Эта методология позволяет использовать все данные как в качестве обучающих, так и в качестве тестовых наборов, что повысит точность предсказания модели неизвестных или невидимых данных. Существует два метода перекрестной проверки: исключение p-меток и k-кратное тестирование.
Уберите p-метки.
Чтобы повысить точность, можно использовать тест, чтобы забыть о p количестве меток во время тестирования, чтобы «перетренировать» предпочтительные метки. Во время тестирования этикетки, которые были «упущены», возвращаются и используются.
K-кратное тестирование.
Это наиболее часто используемый тип перекрестной проверки. Это включает в себя взятие тестового набора и «перемещение» региона по всему набору данных, чтобы убедиться, что все данные были использованы для тестирования.
Итак, давайте поговорим о ядре.

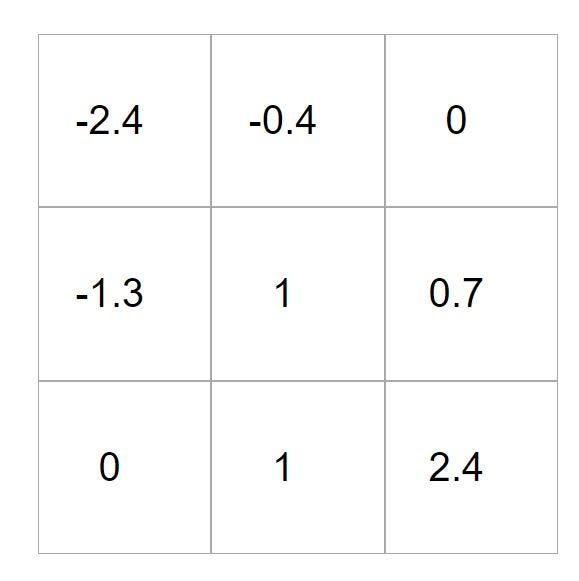
Несмотря на то, что показанное выше изображение представляет собой матрицу 3x 3, ядро может быть любого размера. Размер ядра определяется входным размером. Имея это в виду, размер ядра должен быть достаточно большим, чтобы охватить достаточно данных в его вычислениях, но также и достаточно маленьким, чтобы предотвратить перекрытие обрабатываемой информации. Кроме того, ядро содержит константы, которые затем используются в серии операций свертки. Существует множество различных типов пользовательских эффектов, которые можно реализовать, манипулируя значениями, хранящимися в ядре. Например, ядро идентичности сохраняет изображение как оно есть, устанавливая центр ядра nx n равным 1, а окружающие ячейки равными 0. Это сохранит требуемое значение. пиксель, при этом «забывая» другие нежелательные значения во время умножения операции свертки. Благодаря этому легко предположить, что сетки с нулевым значением в ядре будут «забыты» или не будут учитываться в операции свертки по сравнению с 1, которая сохранит пиксель как есть. Увеличивая размер входных данных (значение ядра больше 1), можно выполнить размытие, а прямо противоположный эффект (резкость) можно выполнить, уменьшив размер.
Существуют ли другие части обработки изображений?
Ядро изображения — не единственная важная часть обработки изображения. Если бы мы обратились к рисунку 2, ядро, похоже, перемещалось по входу. Степень движения называется шагом и может быть настроена для увеличения количества пикселей, которые пропускает ядро. Увеличение шага гарантирует, что области, исследуемые ядром изображения, не перекрываются.
Заполнение — еще одна важная часть обработки изображения, когда ядро начинает двигаться вдоль границы ввода. Это можно настроить на nколичество слоев, в зависимости от размера входных данных и размера ядра. На рис. 4 показана операция свертки, в которой используется слой заполнения и шаг, равный единице.
Различные типы отступов
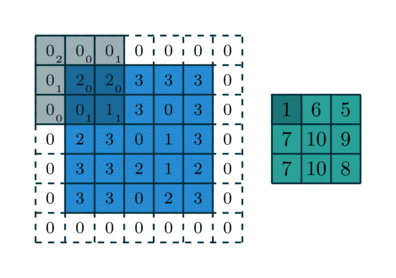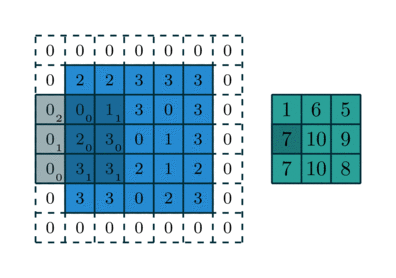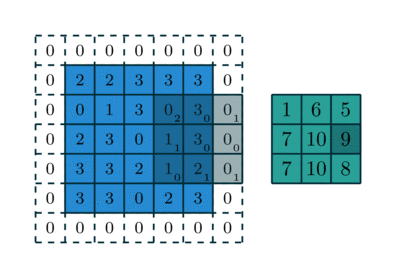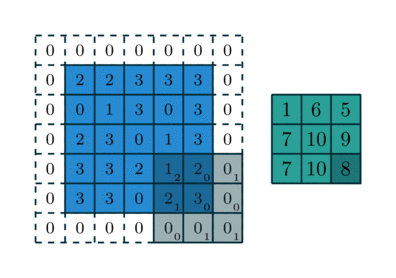
Хотя на приведенном выше рисунке в качестве используемого значения показаны нули, значения могут быть любыми. Существуют и другие типы заполнения, которые можно использовать, например, отражающее заполнение, но для простоты основное внимание будет уделено заполнению нулями, как показано на рисунке 4.
Без заполнения:
Это требует от ядра обработки каждого пикселя ввода, где нет слоев нулей. Это приводит к тому, что фронты входных данных не обрабатываются полностью всем ядром, как показано на рисунке 1.
Половинное заполнение:
Половинное заполнение используется для сохранения размера ввода. Это может быть необходимо, когда в сети задействовано несколько слоев заполнения. Операции свертки уменьшают размер входных данных, как показано на рисунке 4. Половинное заполнение получило свое название от формулы, которая использовалась для его выполнения. Размер ядра был разделен пополам, а затем пол деления был удвоен, а затем добавлено значение на единицу меньше, чем размер ядра.
Полное заполнение:
Это позволяет увеличить размер входных данных, что может быть полезно для нейронных сетей с большим количеством сверток. Это может восстановить слои, которые были удалены операцией свертки.
Какие виды операций свертки существуют?
Есть две основные операции свертки, которые можно использовать при обработке ввода. Детали операции можно настроить по своему вкусу, изменив ранее упомянутые свойства, чтобы увеличить объем информации, представляемой в каждой операции свертки. Изменяя отступы, вы позволяете ядру обрабатывать края входных данных и сохранять или увеличивать размер.
Различные типы операций свертки
Нет заполнения нулями с неединичными шагами:
Это приведет к выводу, равному количеству шагов плюс один, включая начальную позицию ядра, которые были приняты ядром. Шаги, отличные от единиц, можно использовать для ограничения количества перекрывающихся областей анализа.
Нулевое заполнение с неединичными шагами:
Включив заполнение вокруг входных данных и настроив ядро на использование неединичных шагов, можно выполнить еще одну операцию свертки для обработки входных данных и включения пограничных случаев входных данных. .
Операции транспонированной свертки
Транспонирование операции свертки означает изменение направления свертки. Это означает, что когда ядро используется для изменения значений и обработки ввода, прямая и обратная перестановка меняются местами. Шаги и отступы используются для достижения той же цели, которая заключается в улучшении обработки данных. Однако, поскольку ранее упомянутые операции теперь работают в противоположном направлении, результаты шагов и заполнения не совпадают с тем, как они используются во время стандартных операций свертки.
На рисунке 5 показана транспонированная операция свертки. Добавляя заполнение к входным данным, можно рассмотреть каждую интересующую область, а на выходе можно получить более полные данные по сравнению с тем, чтобы позволить ядру исследовать только четыре заштрихованные области. Операции транспонированной свертки обычно используются для улучшения разрешения изображения. Применение этого бесконечно, включая улучшение зернистых кадров видеонаблюдения, снятых в бизнесе, или добавление лиц или кадров, которые могут быть размытыми или закрытыми.
Настройка эффекта изображения
Как упоминалось ранее, существует множество различных параметров, которые мы можем использовать для настройки при использовании ядра изображения для выполнения определенных эффектов на изображениях, таких как размытие, поворот и обрезка. Таким образом, с помощью настройщика изображений, который доступен на http://setosa.io/ev/image-kernels/, можно создать пользовательское ядро, такое как показано на рисунке 7, и мы можем применить ядро к изображение.


Внедрение пользовательских фильтров
Реализацию пользовательских фильтров можно найти в Интернете на таких сайтах, как GitHub и GitLab, причем Python является одним из самых популярных языков выбора. Я не обязательно утверждаю, что Python обеспечит наилучшую производительность для вашей задачи, но для этой цели в языке есть множество библиотек, а также доступная документация для справки.
Гораздо раньше, в 2004 году, Apple предоставила эту часть кода, которую можно использовать для настройки эффектов изображения. Значения для вектора и поплавков могут быть изменены для достижения любого желаемого эффекта.

Приведенный выше код может быть лишь отправной точкой для реализации на Java, Python, C++/C и даже в Matlab!
Операции свертки стали очень полезным инструментом, который в настоящее время имеет множество различных приложений. Вы можете изменять изображения, упрощать изображения для решения проблем с классификацией изображений и настраивать эффекты для загрузки на любой веб-сайт социальной сети, который вы хотите использовать, с помощью сверток! Надеемся, что после прочтения этого поста вы так же заинтересовались основой этих эффектов, которые набирают популярность среди пользователей приложений и веб-сайтов социальных сетей.
Ссылки
- Ле Кун, Ю., Боту, Л., и Бенжио, Ю. (1997). Чтение проверяется многослойными графотрансформаторными сетями. В Акустике, речи и обработке сигналов, 1997 г. ICASSP-97., 1997 г. Международная конференция IEEE, том 1, стр. 151–154. . IEEE.
- Крижевский А., Суцкевер И. и Хинтон Г. Э. (2012). Классификация Imagenet с помощью глубоких сверточных нейронных сетей. В Достижения в области нейронных систем обработки информации, страницы 1097–1105.