Мысли и теория
Кластеризация в геопространственных приложениях - какую модель следует использовать?
Новое сравнение KMeans, DBSCAN, моделей иерархической кластеризации в машинном обучении в применении к городским сетям.

Взгляните на популярный набор инструментов машинного обучения на Python, страницу scikit-learn, посвященную различным алгоритмам кластеризации, и вы увидите сравнения между 10 различными алгоритмами. Разработчики пакетов проделали отличную работу по сравнению и визуализации различных алгоритмов кластеризации, применяемых к различным игрушечным сценариям. Сила этих визуализаций в том, что вы точно знаете основную истину - например, 3 капли должны быть 3 кластерами. Однако это явно не говорит нам, как эти алгоритмы будут работать с геопространственными данными, что может быть довольно сложным. Некоторые важные приложения геопространственной кластеризации включают уменьшение размера больших наборов данных о местоположении и понимание крупномасштабных моделей мобильности с помощью кластеризации поездок на такси для городского планирования и транспорта.
Во многих случаях в реальном мире трудно определить априори, сколько кластеров является правильным. В этом случае может быть трудно интерпретировать результаты алгоритма кластеризации при группировании ваших данных в кластеры. Добавьте 9 других алгоритмов, и вы можете в конечном итоге получить каждый алгоритм, дающий разные результаты, и почти невозможно узнать, какой из них наиболее близок к истинной действительности. Здесь я применяю 3 репрезентативных алгоритма кластеризации - kMeans, DBSCAN и иерархическую агломеративную кластеризацию на одном и том же наборе данных городской уличной сети Манхэттена в три этапа:
- Разбейте уличную сеть Манхэттена на 3 больших кластера путем случайного удаления критического количества узлов, используя критерий фазового перехода из статистической физики теории перколяции
- Применяйте различные алгоритмы кластеризации к набору данных и в процессе обнаруживайте новый метод калибровки алгоритмов кластеризации перед удалением узла
- Оцените, какие алгоритмы кластеризации работают лучше других, с помощью метрики сходства Жаккара.
Хорошо, время действовать!
Получение сети Манхэттен-стрит из OSMnx
import osmnx as ox place=’Manhattan, New York City, New York, USA’ G = ox.graph_from_place(place) ox.plot.plot_graph(G,edge_linewidth=0.1,edge_color='C0',node_size=0,bgcolor='w',save=True, filepath='Manhattan.png')

Чтобы получить уличную сеть Манхэттена, мы используем OSMnx, пакет на основе Python для сетевого анализа городских уличных сетей, который использует мощный проект совместной карты OpenStreetMap (OSM). Сеть содержит узлы, которые представляют собой перекрестки, и ребра, которые представляют собой двунаправленные дороги между перекрестками.
Основная истина из теории перколяции
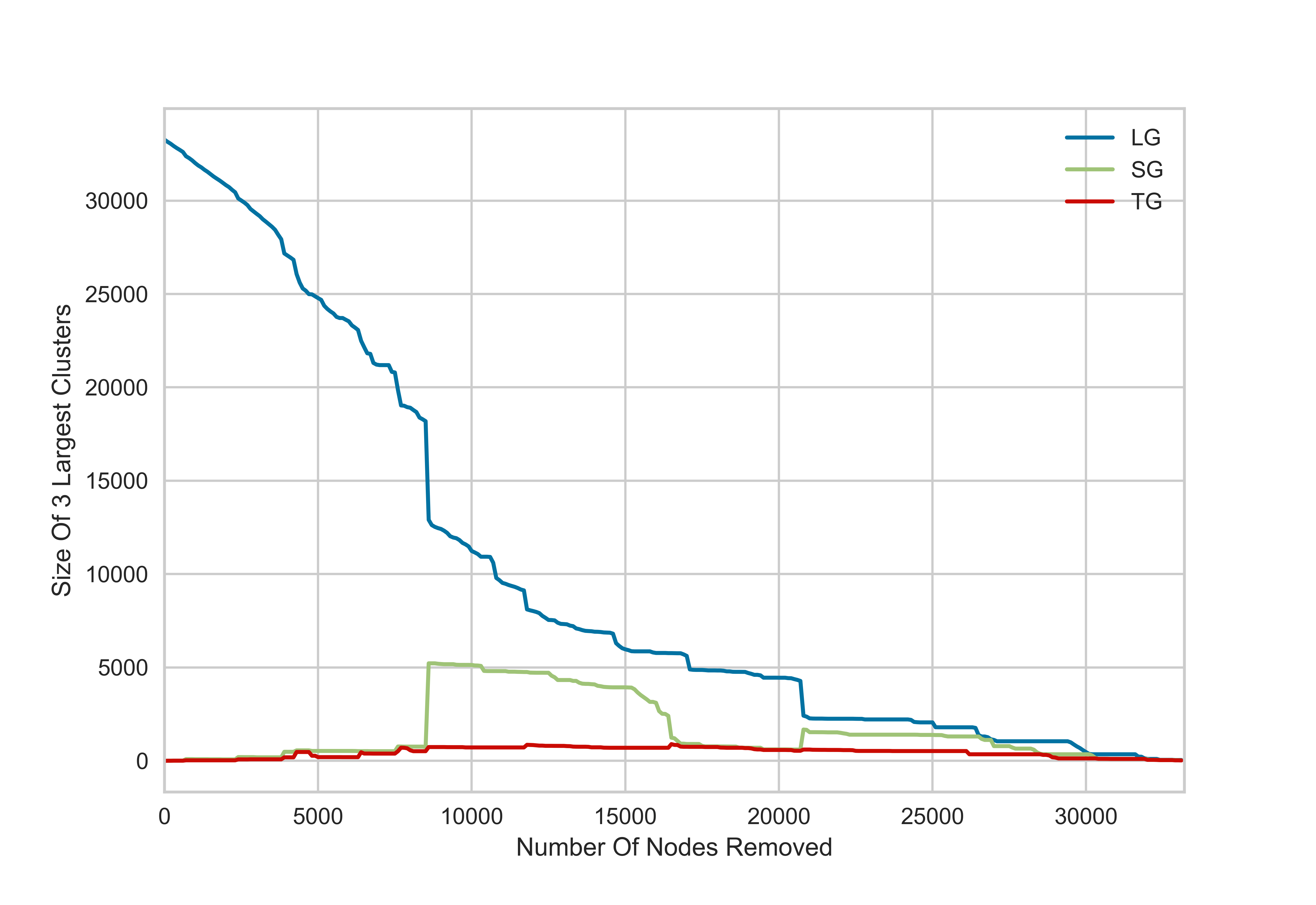
Чтобы получить достоверную информацию, нам нужно найти способ разделить сеть на небольшое количество кластеров, удалив узлы соответствующим образом. В целом это сложно для сетей, поскольку удаление всего нескольких узлов может привести к появлению нескольких небольших кластеров, отколовшихся от одного большого кластера, и это становится трудно обнаружить с помощью алгоритмов кластеризации.
Вместо этого мы используем статистическую физику теории перколяции. В ряде работ (включая нашу недавнюю работу о крупномасштабных сбоях сети в результате кибератак на подключенные транспортные средства) показано, что случайное удаление узлов в городских сетях приводит к перколяционному переходу. В этой точке перехода второй по величине кластер имеет максимальный размер. Это означает, что в точке перколяции алгоритмы кластеризации с большей вероятностью будут отличать два или три больших кластера от остального шума.
w = np.where(SG == np.max(SG))[0][0] G2 = G.copy() G2.remove_nodes_from(nodes_G[0:int(w*100)]) conn = nx.weakly_connected_components(G2) conn_list = list(conn) conn_list = sorted(conn_list, key=len, reverse=True) G3 = G2.copy() for i in range(0, len(conn_list) — 3): G3.remove_nodes_from(conn_list[i + 3]) X_G3 = [[G3.nodes[node][‘y’], G3.nodes[node][‘x’]] for node in G3.nodes] ids_G3 = [list(G3.nodes())[i] for i in range(0, len(list(G3.nodes())))] labels=np.zeros(len(ids_G3)) for i in range(0,len(ids_G3)): if(ids_G3[i] in conn_list[0]): labels[i]=0 if(ids_G3[i] in conn_list[1]): labels[i]=1 if(ids_G3[i] in conn_list[2]): labels[i]=2 nc_g,ns_g=plot1(G,ids_G3,labels,’ground_truth.png’)

3 самых больших кластера представляют собой «основную истину» для сравнения с различными алгоритмами кластеризации, которые я рассмотрю.
K означает с K = 3
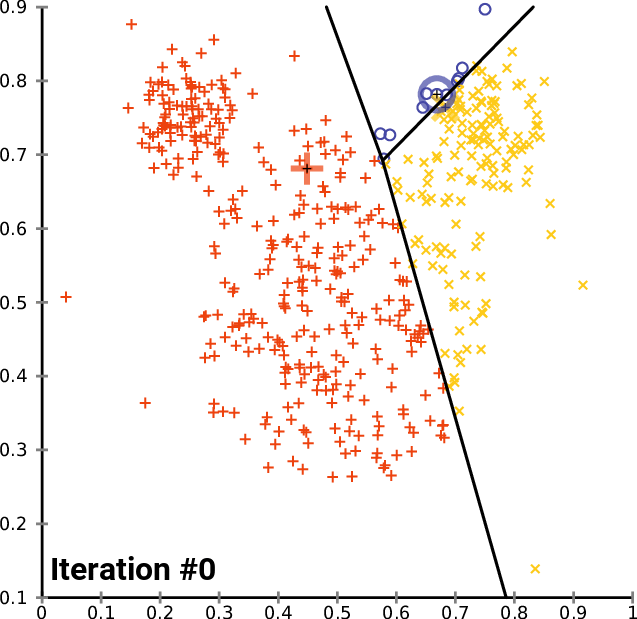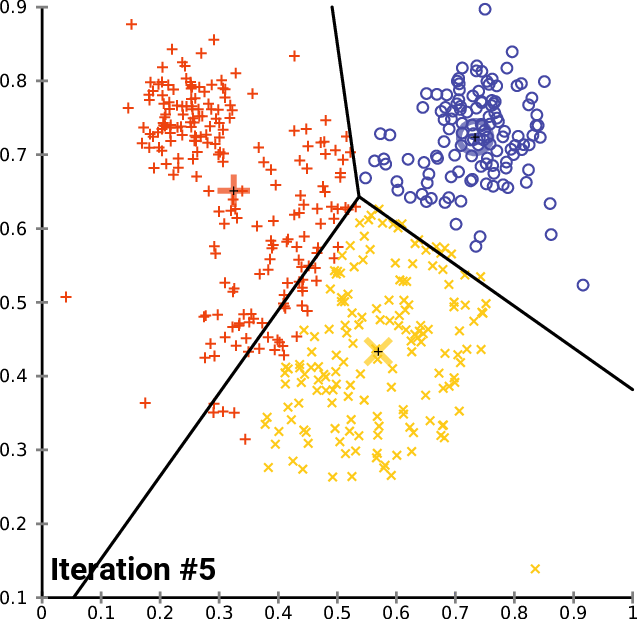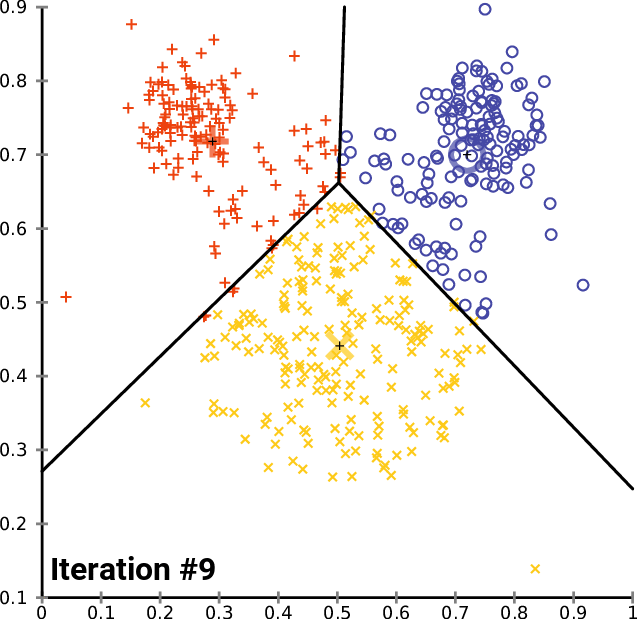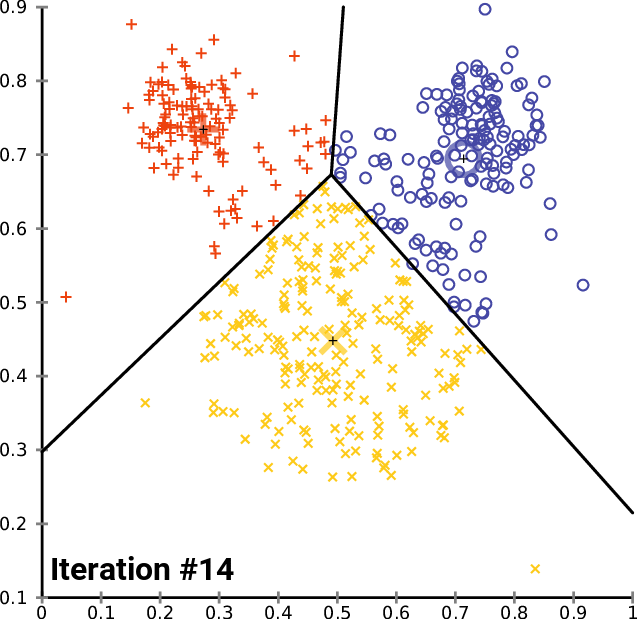
Во-первых, давайте посмотрим, как работает обычный метод KMeans. Метод KMeans разделяет данные на K кластеров с помощью итеративных уточнений, чтобы уменьшить внутрикластерные различия. Каждая наблюдаемая принадлежит кластеру с ближайшим средним значением. Очевидный выбор - K = 3, исходя из истины.
#kmeans n_clusters=3 model = KMeans(n_clusters=3, random_state=0).fit(X_G3) k3_labels = model.labels_ #kmeans_labels = np.unique(model_labels[model_labels >= 0]) nc_k3,ns_k3=plot1(G, ids_G3, k3_labels,’kmeans_3.png’)

Результаты показывают, что KMeans делит первый кластер на два и вместо этого помечает 2-й и 3-й кластеры, объединенные как отдельный кластер. Это связано с ограничениями KMeans глобальными, линейно разделяемыми данными. Имейте в виду, что в данном случае мы выбрали значение K = 3, как мы знаем из истины, что должно быть 3 кластера. Однако это не всегда так, в большинстве случаев мы не знаем, сколько кластеров присутствует, и нуждаемся в надежном алгоритме, который сообщал бы нам, сколько нужно искать. Вместо этого давайте воспользуемся методом локтя, чтобы найти оптимальное значение количества кластеров, а затем применим KMeans, используя оптимальное количество кластеров.
KMeans, метод локтя
#kmeans elbow method model = KMeans() visualizer = KElbowVisualizer(model, k=(4, 12)) visualizer.fit(np.array(X_G3)) # Fit the data to the visualizer model = KMeans(n_clusters=visualizer.elbow_value_, random_state=0).fit(X_G3) ke_labels = model.labels_ #kmeans_labels = np.unique(model_labels[model_labels >= 0]) nc_ke,ns_ke=plot1(G, ids_G3, ke_labels,’kmeans_elbow.png’)

Мы используем KEllbowVisualizer из пакета визуализации машинного обучения Yellowbrick, который реализует метод «локтя» для выбора оптимального количества кластеров путем подбора модели с диапазоном значений для K. Метод локтя дает оптимальное значение K = 7, но работает плохо, особенно по сравнению с выбором K = 3.
DBSCAN, метод локтя
Метод DBSCAN широко используется в геопространственной кластеризации. Этот метод использует два параметра, MinPts и Eps, для соответствия кластерам. MinPts - это минимальное число в пределах радиуса Eps, необходимое для того, чтобы точка считалась частью ядра кластера, включая саму точку (точки, отмеченные буквой A на рисунке ниже). Если точка достижима из базовой точки, но не содержит MinPts в радиусе Eps, она считается неосновной точкой кластера (точки B и C). Наконец, точка, недоступная из базовой точки, является точкой шума (точка N).

Выбор Eps и MinPts нетривиален, но есть несколько широко используемых эвристик. Обычно используется размер MinPts≥2 *. Мы используем MinPts = 5, поскольку Манхэттен в основном представляет собой сетку. В сетке каждое пересечение имеет 4 других соседних пересечения, что составляет 5, включая его самого. Для выбора Eps используем метод локтя.
neigh = NearestNeighbors(n_neighbors=5) nbrs = neigh.fit(np.radians(X_G3)) distances, indices = nbrs.kneighbors(np.radians(X_G3)) distances = distances[:, 1] distances = np.sort(distances, axis=0) fig=plt.figure() plt.plot(distances) plt.xlim(15000, 19000) plt.ylim(.000001, .00002) plt.ylabel(‘5-NN Distance (Radians)’) plt.xlabel(‘Points Sorted By Distance’) plt.savefig(‘dbscan_elbow’,dpi=600) model = DBSCAN(eps=0.000005, min_samples=5, algorithm=’ball_tree’, metric=’haversine’).fit(np.radians(X_G3)) dbe_labels = model.labels_ #db_labels = np.unique(model_labels[model_labels >= 0]) nc_dbe,ns_dbe=plot1(G, ids_G3, dbe_labels,’dbscan_elbow_G.png’)
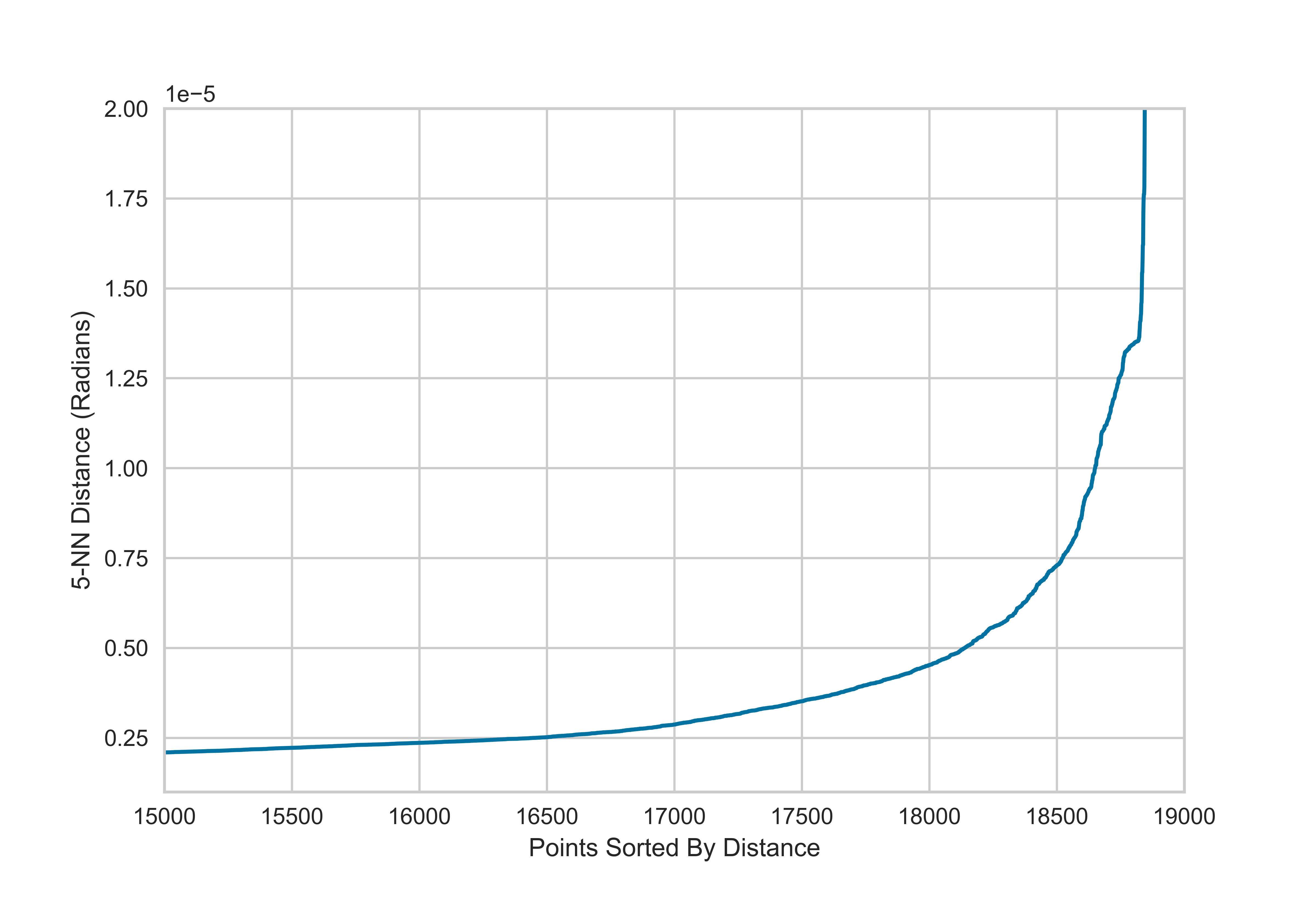

Этот метод работает довольно плохо. Кажется, что Eps = 0,000005 сильно занижено, поскольку кластеры довольно малы. Вместо этого, что, если мы посмотрим на кластер до удаления узлов для калибровки?
Откалиброванный DBSCAN
Идеальный алгоритм дает 1 большой подключенный кластер, когда узлы не удалены в уличной сети Манхэттена, и 3 кластера, когда узлы удалены. Давайте воспользуемся этой информацией для калибровки значения Eps алгоритма DBSCAN.
#dbscan calibration method # now figuring optimal epsilon for city cs = np.zeros(16) for i in range(0, 16): db = DBSCAN(eps=np.linspace(0.000005, 0.000005 * 10, 16)[i], min_samples=5, algorithm=’ball_tree’, metric=’haversine’).fit( np.radians(X_G)) cs[i] = len(np.unique(db.labels_)) # print(0.000005*(i+1)) fig=plt.figure() plt.loglog(np.linspace(0.000005, 0.000005 * 10, 16), cs) plt.ylabel(‘Number Of Clusters’) plt.xlabel(‘Eps Value (radians)’) plt.savefig(‘dbscan_calib’,dpi=600) model = DBSCAN(eps=0.00003, min_samples=5, algorithm=’ball_tree’, metric=’haversine’).fit(np.radians(X_G3)) dbc_labels = model.labels_ nc_dbc,ns_dbc=plot1(G, ids_G3, dbc_labels, ‘dbscan_calib_G.png’)

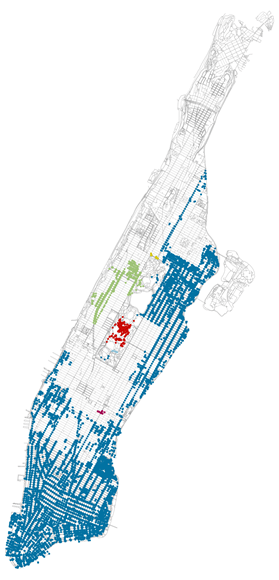
Мы выбираем наименьшее значение Eps, которое дает один кластер при отсутствии удаленных узлов, и получаем Eps = 0,00003. Это дает гораздо лучший результат, и визуально выделяются 3 кластера. Первый, кажется, охватывает кластеры наземной истины 1 и 2, а второй и третий кластеры разделяют третьи кластеры наземной истины. Так лучше, но не идеально.
Калиброванная иерархическая агломеративная кластеризация

Наконец, давайте посмотрим на алгоритм кластеризации, который строит иерархию кластеров. Иерархическая агломеративная кластеризация - это восходящий метод, при котором каждая наблюдаемая начинается в отдельном кластере, а пары кластеров объединяются по мере продвижения вверх по иерархии. В общем, это довольно медленный метод, но он имеет большое преимущество в том, что можно визуализировать все дерево кластеризации, известное как дендрограмма.
В зависимости от приложения существует несколько различных вариантов определения количества кластеров. Подобно KMeans, можно выбрать количество кластеров. Или используйте критерий расстояния, чтобы остановить кластеризацию, когда кластеры слишком далеко друг от друга для объединения, аналогично DBSCAN.
Недостаток иерархической кластеризации заключается в неинтуитивности выбора количества кластеров или критерия расстояния, что составляет визуализацию дендрограммы, как указано выше, и выполнение произвольных отсечений.
Вместо этого я делаю что-то похожее на метод калибровки DBSCAN - калибрую критерий расстояния агломеративной кластеризации от полностью подключенной манхэттенской сети без удаления узла.
#hierarchical agglomerative clustering calibration method
n_l=np.zeros(10)
for i in range(0,10):
model = AgglomerativeClustering(distance_threshold=np.linspace(0.02,.2,10)[i], n_clusters=None)
model = model.fit(np.radians(X_G))
distances = model.distances_
n_l[i]=len(np.unique(model.labels_))
print(i)
plt.plot(np.linspace(0.02,.2,10),n_l)
nc_ag,ns_ag=plot1(G, ids_G3, ag_labels, ‘hierarch_calib.png’)
model = AgglomerativeClustering(distance_threshold=.2, n_clusters=None)
model = model.fit(np.radians(X_G3))
ag_labels = model.labels_
nc_ag,ns_ag=plot1(G, ids_G3, ag_labels, 'hierarch_calib_G.png')

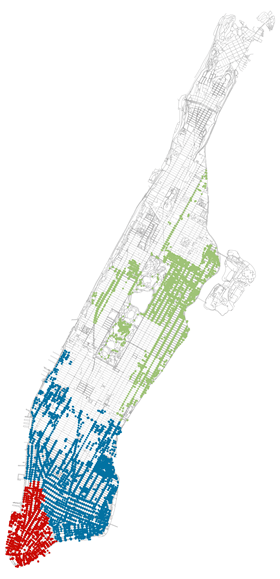
Подобно DBSCAN, я выбираю критерий расстояния, соответствующий минимальному значению порога расстояния, который дает 1 кластер, когда из уличной сети Манхэттена не удаляются никакие узлы. Агломеративная кластеризация дает только один большой кластер.

При выборе значения количества кластеров = 3 это выглядит лучше.
Какой алгоритм лучше всего подходит для геопространственных приложений?
Мы рассмотрели 3 наиболее часто используемых алгоритма пространственной кластеризации: KMeans, DBSCAN и иерархическую агломеративную кластеризацию применительно к уличной сети Манхэттена. Интересно, что ответ не так однозначен, как я думал изначально, и зависит от того, известно ли оптимальное количество кластеров априори или нет.
Чтобы сравнить яблоки с яблоками, я построил график результатов алгоритма кластеризации при отсутствии априорной информации о количестве кластеров. Визуально кажется, что DBSCAN работает лучше всего, что оправдывает его широкое использование в геопространственных приложениях. Однако это не тот случай, если мы знаем количество кластеров априори.

Чтобы количественно оценить, насколько хорошо работает каждый алгоритм, я использовал метрику сходства Жаккара для небинарных классов.

Лучшим исполнителем является алгоритм агломеративной кластеризации, использующий n_clusters = 3 (ag_3), который имеет оценку Жаккарда более 0,65. В отсутствие этой информации DBSCAN и агломеративная кластеризация посредством калибровки (db_calib, ag_calib) являются шейкой и шейкой. Однако я отдам этот раунд DBSCAN, поскольку он распознает отдельные кластеры, тогда как алгоритм агломеративной кластеризации находит только один кластер.
Выводы
Как видите, идеального алгоритма пространственной кластеризации нет. Это особенно характерно для геопространственных приложений, в которых сетевые узлы и ребра распределены неравномерно, а данные часто зашумлены. Полученные результаты алгоритма кластеризации могут быть признаком распределения улиц в Манхэттене, которые больше похожи на сетку, чем в других городских городах - было бы интересно посмотреть, как эти алгоритмы работают в других городских сетях. Мы знаем, что некоторые городские уличные сети, такие как Чикаго, Майами и Манхэттен, более похожи на сетку по сравнению с другими, такими как Сингапур, Рим и Сан-Паулу. Разработанные здесь методы в общем могут применяться для количественной оценки эффективности методов кластеризации в различных геопространственных сценариях. Если вам интересно, код Python доступен на GitHub в виде кода Python. Также есть блокнот jupyter:
Вот ссылка на руководство на YouTube:
Ссылки:
- Джефф Боинг,« Кластеризация для уменьшения размера набора пространственных данных , SocArxiv (2018)»
- Дирадж Кумар и др.,« Понимание городской мобильности с помощью кластеризации поездок в такси , 17-я Международная конференция IEEE по управлению мобильными данными (MDM) (2016)»
- Сканда Вивек и др.,« Киберфизические риски взломанных транспортных средств, подключенных к Интернету , Physical Review E (2019)»
- Джефф Боинг,« Городской пространственный порядок: ориентация, конфигурация и энтропия уличной сети , Applied Network Science (2019)»
Следуй за мной, если тебе понравилась эта статья.
Подпишитесь на мою рассылку, если вам нравится целостный взгляд на взаимосвязь между технологиями и современным обществом.