Первоначально опубликовано на dominixschmidt.xyz.
Большинство руководств по тензорному потоку для начинающих знакомят читателя с feed_dict методом загрузки данных в вашу модель, когда данные передаются в тензорный поток через вызовы функций tf.Session.run() или tf.Tensor.eval(). Однако есть гораздо лучший и почти более простой способ сделать это. Используя tf.data API, вы можете создавать высокопроизводительные конвейеры данных, написав всего несколько строк кода.
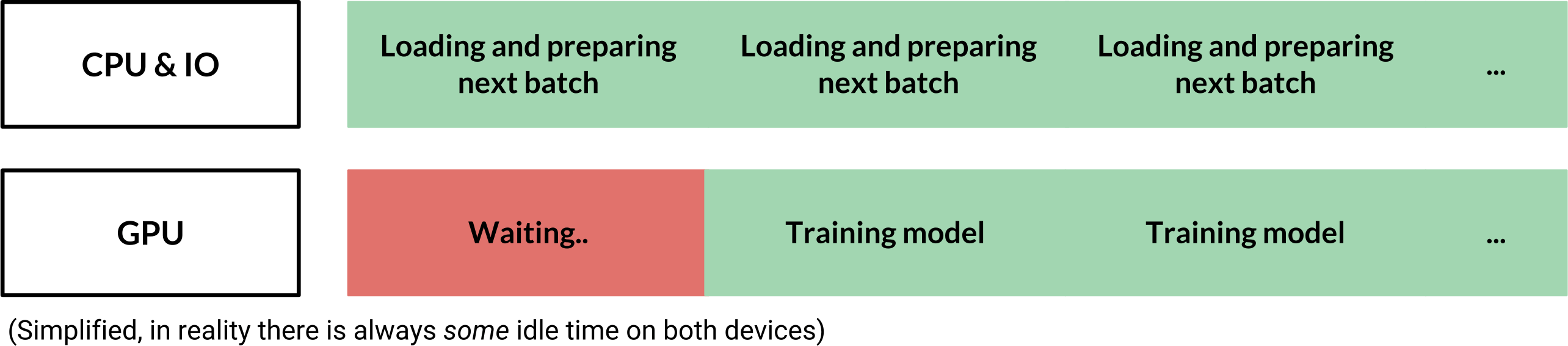
В наивном feed_dict конвейере GPU всегда бездействует всякий раз, когда ему приходится ждать, пока CPU предоставит ему следующий пакет данных.

Однако конвейер tf.data может выполнять предварительную выборку следующих пакетов асинхронно, чтобы свести к минимуму общее время простоя. Вы можете еще больше ускорить конвейер, распараллелив операции загрузки и предварительной обработки.
Внедрение минимального конвейера изображений за 5 минут
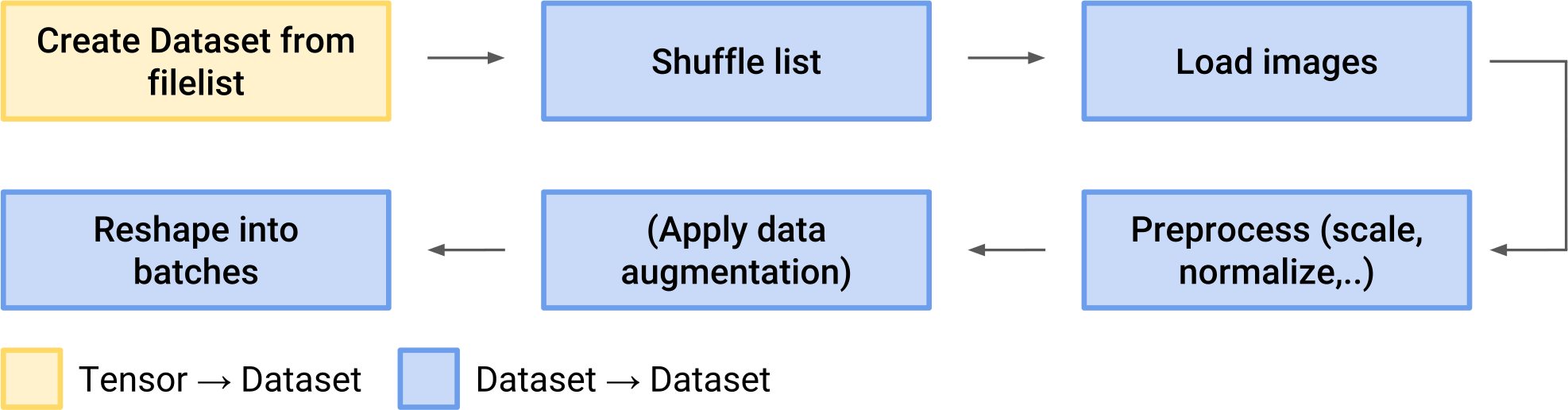
Чтобы построить простой конвейер данных, вам нужны два объекта. tf.data.Dataset хранит ваш набор данных, а tf.data.Iterator позволяет извлекать элементы из вашего набора данных один за другим.tf.data.Dataset для конвейера изображений может (схематически) выглядеть так:
[
[Tensor(image), Tensor(label)],
[Tensor(image), Tensor(label)],
...
]Затем вы можете использовать tf.data.Iterator для извлечения пар изображения-метки одну за другой. На практике несколько пар «изображение-метка» должны быть объединены вместе, так что итератор извлекает по одному пакету за раз. Набор данных можно создать либо из источника (например, списка имен файлов в Python), либо путем применения преобразования к существующему набору данных. Вот несколько примеров возможных трансформаций:
Dataset(list of image files)→Dataset(actual images)Dataset(6400 images)→Dataset(64 batches with 100 images each)Dataset(list of audio files)→Dataset(shuffled list of audio files)
Определение графа вычислений
Минимальный конвейер данных для изображений может выглядеть так:

Весь следующий код помещается в определение графа вычислений вместе с моделью, потерями, оптимизатором и т. д. Сначала создайте тензор из списка файлов.
Теперь определите функцию для загрузки изображения (как тензора) из его пути и используйте tf.data.Dataset.map(), чтобы применить эту функцию ко всем элементам (путям к файлам) в наборе данных. [1] Вы также можете добавить аргумент num_parallel_calls=n к map() для распараллеливания. вызывает функция.
Затем используйте tf.data.Dataset.batch() для создания пакетов:
# Create batches of 64 images each dataset = dataset.batch(64)
Вы также можете добавить tf.data.Dataset.prefetch(buffer_size) в конец конвейера. Это гарантирует, что следующий пакет всегда будет немедленно доступен для графического процессора, и уменьшает голодание графического процессора, как упоминалось выше. buffer_size — это количество пакетов, которые должны быть предварительно загружены. buffer_size=1 обычно достаточно, хотя в некоторых случаях, особенно когда время обработки партии варьируется, его можно увеличить.
dataset = dataset.prefetch(buffer_size=1)Наконец, создайте итератор, чтобы мы могли перебирать набор данных. Доступны различные типы итераторов. Для большинства целей рекомендуется инициализируемый итератор.
iterator = dataset.make_initializable_iterator()Теперь вызовите tf.data.Iterator.get_next(), чтобы создать тензор-заполнитель, который tensorflow заполняет следующим пакетом изображений каждый раз при его оценке.
batch_of_images = iterator.get_next()Если вы переходите с feed_dict, batch_of_images заменяет вашу предыдущую переменную-заполнитель.
Запуск сеанса
Теперь запустите свою модель как обычно, но обязательно оценивайте iterator.initializer операцию до каждой эпохи и перехватывайте tf.errors.OutOfRangeError исключение после каждой эпохи.
Программа nvidia-smi позволяет вам контролировать использование графического процессора и может помочь вам понять узкие места в вашем конвейере данных. Средняя загрузка графического процессора обычно должна быть выше 70-80%.
Более полный конвейер данных
Перемешать
Используйте tf.data.Dataset.shuffle() для перемешивания имен файлов. Аргумент указывает, сколько элементов следует перемешивать за раз. В общем, рекомендуется перетасовать весь список сразу. Посмотрите этот ответ на Stackoverflow
dataset = tf.data.Dataset.from_tensor_slices(files) dataset = dataset.shuffle(len(files))Увеличение данных
Вы можете использовать функции tf.image.random_flip_left_right(), tf.image.random_brightness(), tf.image.random_saturation() для выполнения простой аугментации данных на ваших изображениях. [1]
Этикетки
Чтобы загрузить метки (или другие метаданные) вместе с вашими изображениями, просто включите их при создании исходного набора данных:
# files is a python list of image filenames
# labels is a numpy array with label data for each image
dataset = tf.data.Dataset.from_tensor_slices((files, labels))Убедитесь, что любые функции, которые вы применяете к своему набору данных с помощью .map(), разрешают передачу данных этикетки:
def load_image(path, label): # load image ... return image, labeldataset = dataset.map(load_image)
Первоначально опубликовано на dominixschmidt.xyz.