KNN (K-Nearest Neighbor) - это простой алгоритм контролируемой классификации, который мы можем использовать для присвоения класса новой точке данных. Его также можно использовать для регрессии, KNN не делает никаких предположений о распределении данных, следовательно, он непараметрический. Он сохраняет все обучающие данные, чтобы делать будущие прогнозы, вычисляя сходство между входной выборкой и каждым обучающим экземпляром.
KNN можно резюмировать следующим образом:
- Вычисляет расстояние между новой точкой данных для каждого обучающего примера.
- Для вычисления расстояния будут использоваться такие меры, как евклидово расстояние, расстояние Хэмминга или манхэттенское расстояние.
- Модель выбирает K записей в базе данных, которые наиболее близки к новой точке данных.
- Затем он принимает большинство голосов, т.е. наиболее распространенным классом / меткой среди этих K записей будет класс новой точки данных.

Подробная документация по KNN доступна здесь.
В примере ниже показана реализация KNN на наборе данных радужной оболочки глаза с использованием библиотеки scikit-learn. Набор данных ириса содержит 50 образцов для каждого вида цветка ириса (всего 150). Для каждого образца у нас есть длина чашелистика, ширина, длина и ширина лепестка, а также название вида (класс / этикетка).


- 150 наблюдений
- 4 характеристики (длина чашелистика, ширина чашелистика, длина лепестка, ширина лепестка)
- Переменная ответа - это вид ириса.
- Классификация проблема, поскольку ответ категоричен.
Наша задача - построить модель KNN, которая классифицирует новые виды на основе размеров чашелистиков и лепестков. Набор данных Iris доступен в scikit-learn, и мы можем использовать его для построения нашей KNN.
Полный код можно найти в Git Repo.
Шаг 1. Импортируйте необходимые данные и проверьте функции.
Импортируйте функцию load_iris из модуля наборов данных scikit-learen и создайте объект iris Bunch (bunch - это специальный тип объекта scikitlearn для хранения наборов данных и их атрибутов).

Каждое наблюдение представляет собой один цветок, а 4 столбца представляют 4 измерения. Мы можем видеть характеристики (меры) в атрибуте «данные», а в виде ярлыков в разделе «имена_компонентов». Как мы можем видеть ниже, метки / ответы кодируются как 0,1 и 2. Поскольку функции и отдых должны быть числовыми (массивы Numpy) для моделей scikit-learn, и они должны иметь определенную форму.

Шаг 2. Разделите данные и обучите модель.
Обучение и тестирование на одних и тех же данных не является оптимальным подходом, поэтому мы разделяем данные на две части: набор для обучения и набор для тестирования. Мы используем функцию train_test_split для разделения данных. Необязательный параметр test-size определяет процент разделения. Параметр random_state заставляет данные разделяться одинаково при каждом запуске. Поскольку мы обучаем и тестируем разные наборы данных, полученная точность тестирования будет лучшей оценкой того, насколько хорошо модель может работать с невидимыми данными.

Scikit-learn тщательно организован в модули, чтобы мы могли легко импортировать соответствующие классы. Импортируйте класс «KNeighborsClassifer» из модуля «соседи» и создайте экземпляр оценщика («оценщик» - это термин scikit-learn для модели). Мы называем модель оценкой, потому что их основная роль заключается в оценке неизвестных величин.
В нашем примере мы создаем экземпляр («knn») класса «KNeighborsClassifer», другими словами, мы создали объект с именем «knn», который знает, как выполнять классификацию KNN после того, как мы предоставим данные. Параметр «n_neighbors» - это параметр настройки / гиперпараметр (k). Для всех остальных параметров установлены значения по умолчанию.
Метод «подгонки» используется для обучения модели на данных обучения (X_train, y_train) и метод «прогнозирования» для проведения тестирования на данных тестирования (X_test). Выбор оптимального значения K имеет решающее значение, поэтому мы подбираем и тестируем модель для различных значений K (от 1 до 25) с помощью цикла for и записываем точность тестирования KNN в переменную (оценки).
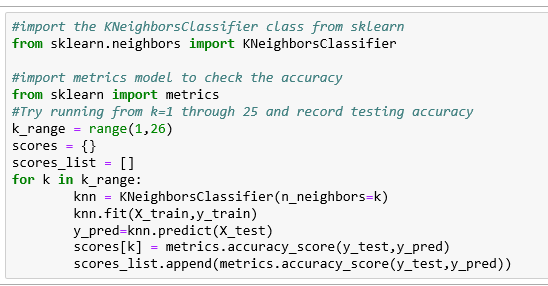
Постройте взаимосвязь между значениями K и соответствующей точностью тестирования с помощью библиотеки matplotlib. Как мы видим, точность увеличивается и уменьшается, что вполне типично при рассмотрении сложности модели с точностью. Как правило, по мере увеличения значения K точность увеличивается и снова падает.
В целом точность обучения повышается с увеличением сложности модели, для KNN сложность модели определяется значением K. Чем больше значение K, тем более гладкая граница принятия решения (менее сложная модель). Меньший K приводит к более сложной модели (может привести к переобучению). Точность тестирования наказывает слишком сложные модели (чрезмерная подгонка) или недостаточно сложные (недостаточная подгонка). Мы получаем максимальную точность тестирования, когда модель имеет правильный уровень сложности, в нашем случае мы видим, что для значения K от 3 до 19 точность нашей модели составляет 96,6%.

Для нашей окончательной модели мы можем выбрать оптимальное значение K как 5 (которое находится между 3 и 19) и повторно обучить модель со всеми доступными данными. И это будет наша последняя модель, которая готова делать прогнозы.

Спасибо за чтение и дайте нам знать свои предложения / исправления, если таковые имеются.