Основным этапом обучения и применения нейронных сетей в реальном проекте является понимание различных слоев нейронной сети: различных слоев свертки, слоев пула, деконволюционных слоев, полносвязных слоев или полносвязных слоев свертки. Чтобы понять это, нам нужно не только понимать визуализированные операции, нам важно понимать математику, лежащую в основе этого. Обладая такими знаниями, мы можем дополнительно проанализировать достоинства и недостатки каждого типа слоя.
Любая нейронная сеть в области компьютерного зрения, применяемая к двумерным изображениям, состоит из двух частей: слои действуют как средство извлечения признаков, а слои предназначены для конкретных задач, либо классификация, либо сегментация. Экстрактор признаков обычно включает сверточный слой и слой объединения. Что касается слоев для конкретных задач: (1) для задачи классификации обычно полностью связанный слой прикрепляется за экстрактором признаков, чтобы он мог преобразовать двухмерный экстрактор признаков в вектор признаков. (2) для задачи сегментации полностью связанный слой обычно заменяется полностью связанным сверточным слоем, чтобы сохранить больше информации, зависящей от местоположения.
Затем применяется конкретная функция активации и функция затрат / потерь. Для мультиклассовой классификации / сегментации используется кросс-энтропия, о которой мы поговорим в следующем посте. Теперь давайте сосредоточимся на понимании различных слоев нейронной сети.
Слой свертки
Роль сверточного слоя состоит в том, чтобы обнаруживать локальные объекты в различных положениях на входных картах признаков с помощью обучаемых «фильтров» / «ядер».
Операция свертки
Для обработки изображений оператор свертки обычно обозначается звездочкой:
s(t) = (x*w) (t),
где x (t) называется входом, а w - весами ядра. Интуитивно он работает, добавляя соседние элементы в матрицу, взвешенную ядром. Эти операции аналогичны обычным фильтрам: гауссовский фильтр, двухсторонняя фильтрация и так далее.
Операции свертки выражаются математикой, как показано ниже:


Есть три гиперпараметра, определяющие пространственное пространство выходной карты признаков:
- Шаг (S) - это шаг при каждом перемещении фильтра. Когда шаг равен 1, мы перемещаем фильтры по одному пикселю за раз. Когда шаг равен 2 (или, как правило, 3 или больше, хотя на практике это редко), тогда фильтры перескакивают на 2 пикселя за раз, когда мы их перемещаем. Это будет производить меньшие объемы вывода в пространстве.
- Заполнение (P): Как видно из уравнения. 1, когда i = 0, j = 0 и предполагая m = -2, n = -2, тогда нам нужна позиция во входных данных с индексом как (-2, -2), которой не существует. Чаще всего для заполнения этих мест используется заполнение нулями. В структурах нейронных сетей (caffe, tensorflow, pytorch, mxnet) размер этого нулевого заполнения является гиперпараметром. Размер нулевого заполнения также можно использовать для управления пространственным размером выходных томов.
- Глубина (D): глубина выходного объема также является гиперпараметром, она соответствует количеству фильтров, которые мы используем для сверточного слоя. В уравнении 1 глубина = 1, и у входа также есть канал 1.
Определитесь с размером вывода
Учитывая w как ширину ввода, а F - ширину фильтра, с P и S как заполнение, ширина вывода будет:
(W + 2P-F)/S+1
Обычно устанавливается P = (F −1) / 2, когда шаг равен S = 1. гарантирует, что входной и выходной объем будут иметь одинаковый пространственный размер.
Недопустимая конфигурация: если размер входных данных W = 10, нулевое заполнение не используется P = 0, а размер фильтра F = 3, то было бы невозможно использовать шаг S = 2, поскольку (W - F +2 P ) / S + 1 = (10−3 + 0) /2+1=4.5, т.е. не целое число, что указывает на то, что нейроны не «вписываются» аккуратно и симметрично по входу.
Расширенные извилины
Недавняя разработка (например, см. Статью Фишера Ю и Владлена Колтуна) заключается в том, чтобы ввести еще один гиперпараметр в слой CONV, называемый расширением. До сих пор мы обсуждали только смежные фильтры CONV. Однако можно использовать фильтры с промежутками между ячейками, что называется расширением. Например, в одном измерении фильтр w размера 3 будет вычислять над входом x следующее: w[0]*x[0] + w[1]*x[1] + w[2]*x[2]. Это расширение 0. Для расширения 1 фильтр вместо этого вычислит w[0]*x[0] + w[1]*x[2] + w[2]*x[4]; Другими словами, между приложениями есть разрыв в 1. Это может быть очень полезно в некоторых настройках для использования в сочетании с фильтрами с нулевым расширением, поскольку это позволяет объединять пространственную информацию по входам гораздо более агрессивно с меньшим количеством слоев. Например, если вы складываете два слоя 3x3 CONV друг на друга, вы можете убедить себя, что нейроны на 2-м слое являются функцией участка ввода 5x5 (мы бы сказали, что эффективное рецептивное поле этих нейронов 5x5). Если мы будем использовать расширенные извилины, то это эффективное рецептивное поле будет расти намного быстрее.
Теперь давайте посмотрим на разные типы сверточного слоя:
Стандартный сверточный слой:


Обычно при вводе размера W 1 × H 1 × D 1 фильтры будут иметь вид F1 × F2 × D1 × D2. Как показано выше, сначала каждый канал на входе выполняет свертку с соответствующим ему каналом в i-м наборе фильтров, затем мы получаем набор карт характеристик того же размера, и размер этого набора такой же, как и у входного канала D1. . Затем мы суммируем этот набор карт характеристик всех каналов и получаем одну выходную карту характеристик. Затем проделываем D2 наборы таких же операций, получаем выходной канал D2.
количество параметров = (F1 × F2 × D1 + 1) × D2
Мы можем видеть в этом процессе, как сумма разных каналов смешивает сигналы между разными каналами. Существует еще один слой свертки, называемый слоем свертки с разделением по глубине, он не выполняет этих операций суммирования.
Слой свертки с разделением по глубине [1]
В разделяемом по глубине сверточном слое вместо фильтра с набором D2 F1 × F2 × D1 используется только один набор как F1 × F2 × D1. Как и при обычной свертке, мы получаем карты характеристик D1 размером W2 × H2, но вместо того, чтобы суммировать их, чтобы получить только один канал, мы выполняем обычную свертку D1 × W2 × H2 с другой сверткой 1 × 1 для D1 × D2, тогда мы получим тот же размер вывода D2 × W2 × H2. Эти два процесса резюмируются как:
- Глубинная свертка, то есть пространственная свертка, выполняемая независимо по каждому входному каналу.
- Точечная свертка, то есть свертка 1x1, проецирующая каналы, выводимые глубинной сверткой, на новое пространство каналов.
Используемые параметры:
количество параметров = (F1 × F2 × D1 + 1) + (1 × 1 × D1 + 1) × D2
Теперь, используя pytorch, давайте сравним, как мы определяем свертку и разделяемую по глубине свертку:
# normal convolution normal_layer = nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2) # 16 is input channel, and 32 is the output channel # depthwise separable convolution layer_1 = nn.Conv2d(16, 1, kernel_size=5, stride=1, padding=2) depthwise_layer = nn.Conv2d(16, 32, kernel_size=1, stride=1, padding=0) out = layer_1(x) out = depthwise_layer(out)
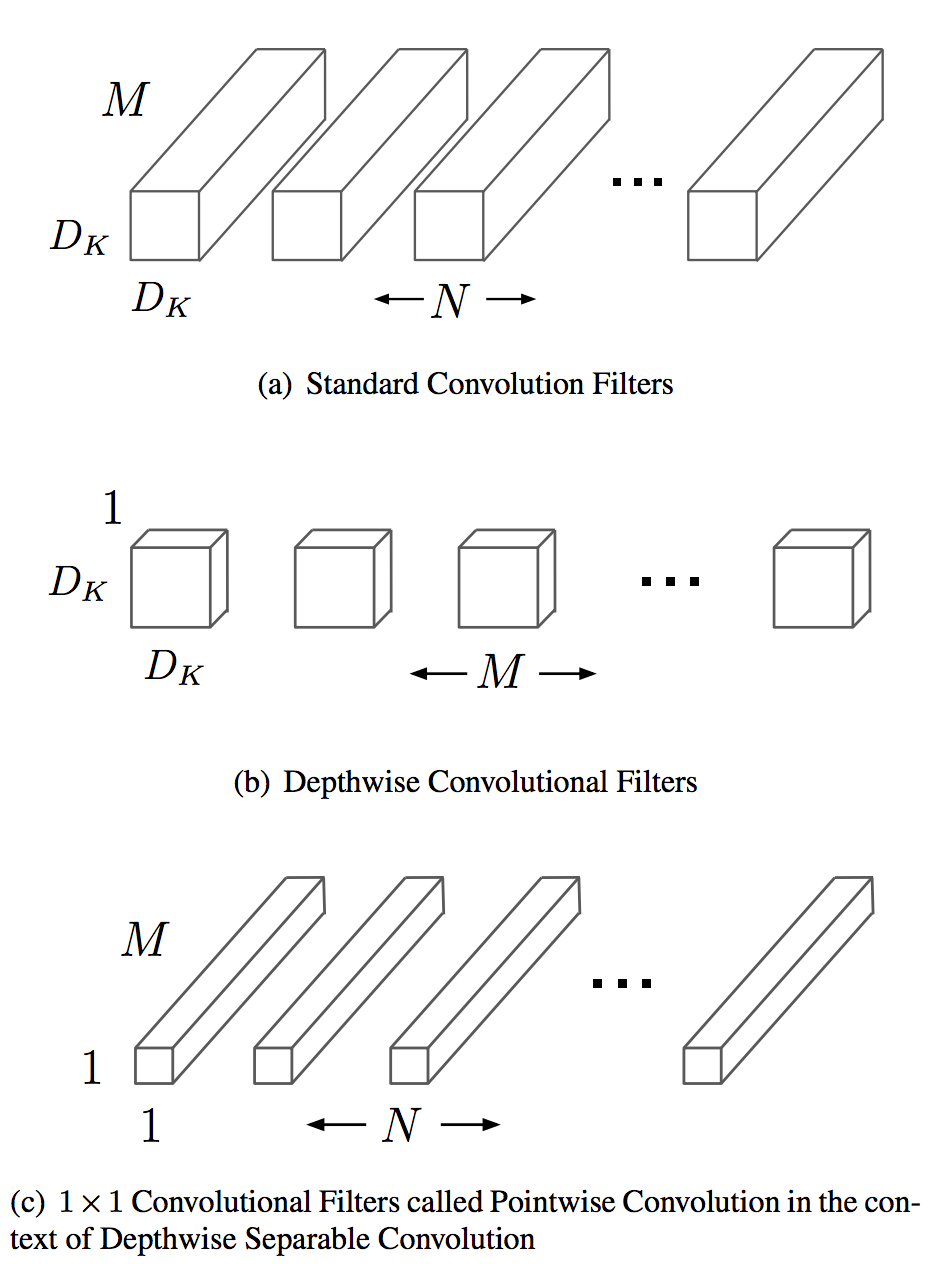
Сглаженные свертки [2]


Пространственные и кросс-канальные свертки
Уровень объединения
В настоящее время CNN всегда использует широкое разделение веса, чтобы уменьшить степень свободы моделей. Слой объединения помогает сократить время вычислений и постепенно наращивать пространственную и конфигурационную инвариантность. Для понимания изображения слой объединения помогает извлечь больше семантического значения.
Хорошо знать
Знайте, что вы знаете, как работает сверточный слой, пора затронуть некоторые полезные детали:
- Количество параметров. При проектировании сети большое значение имеет количество обучаемых параметров. Поэтому хорошо знать, сколько параметров сверточный слой добавит к вашей сети. То, что вы тренируете в сверточном слое, - это его фильтры и смещения. Затем вы можете легко рассчитать количество его параметров, используя следующее уравнение:
количество параметров = (Fw × Fh × di + 1) × do
где di и do - глубина (количество каналов) входа и глубина выхода соответственно. Обратите внимание, что цифра в скобках предназначена для подсчета смещений.
- Локально подключенный слой: этот тип слоя очень похож на сверточный слой, описанный в этой публикации, но с одним (важным) отличием. В сверточном слое фильтр был общим для всех выходных нейронов (пикселей). Другими словами, мы использовали один фильтр для вычисления всех нейронов (пикселей) выходных каналов. Однако в слое с локальным подключением каждый нейрон (пиксель) имеет свой собственный фильтр. Это означает, что количество параметров будет умножено на количество выходных нейронов. Это может резко увеличить количество параметров, и если у вас недостаточно данных, вы можете столкнуться с проблемой чрезмерной подгонки. Однако этот тип слоя позволяет вашей сети изучать различные типы объектов для разных областей входа. Исследователи получили преимущество этого полезного свойства локально подключенных слоев, особенно при проверке лиц, таких как DeepFace и DeepID3. Тем не менее, некоторые другие исследователи используют отдельный фильтр для каждой области входа вместо каждого нейрона (пикселя), чтобы получить преимущества локально связанных слоев с меньшим количеством параметров.
- Слои свертки с размером фильтра 1X1: хотя использование фильтра 1X1 на первый взгляд не имеет смысла с точки зрения обработки изображений, он может помочь, добавив нелинейности в вашу сеть. Фактически, фильтр 1X1 вычисляет линейную комбинацию всех соответствующих пикселей (нюэронов) входных каналов и выводит результат через функцию активации, которая суммирует нелинейность.
Нормальная свертка:
Если у нас есть 3 входных канала I3, нам нужно 5 выходных каналов O5, тогда фильтры имеют размер 5, каждый имеет 3 канала. Мы можем представить их как W с размером O * I. Таким образом, для каждого входного канала I_i мы можем выполнять свертку одновременно с W1_i, W2_i, W3_i, W4_i и W5_i. Разные входные каналы не разделяли веса между собой.
Количество параметров: (Fw * Wh * do + 1) * d1
Деконволюция
Уровень с локальным подключением:
В сверточном слое фильтр был общим для всех выходных нейронов (пикселей). Другими словами, мы использовали один фильтр для вычисления всех нейронов (пикселей) выходных каналов. Однако в слое с локальным подключением каждый нейрон (пиксель) имеет свой собственный фильтр. Это означает, что количество параметров будет умножено на количество выходных нейронов. Это может резко увеличить количество параметров, и если у вас недостаточно данных, вы можете столкнуться с проблемой чрезмерной подгонки. Однако этот тип слоя позволяет вашей сети изучать различные типы объектов для разных областей входа. Исследователи получили преимущество этого полезного свойства локально подключенных слоев, особенно при проверке лиц, таких как DeepFace и DeepID3. Тем не менее некоторые другие исследователи используют отдельный фильтр для каждой области входа вместо каждого нейрона (пикселя), чтобы получить преимущества локально связанных слоев с меньшим количеством параметров.
Слои свертки с размером фильтра 1X1: хотя использование фильтра 1X1 на первый взгляд не имеет смысла с точки зрения обработки изображений, он может помочь, добавив нелинейности в вашу сеть. Фактически, фильтр 1X1 вычисляет линейную комбинацию всех соответствующих пикселей (нюэронов) входных каналов и выводит результат через функцию активации, которая суммирует нелинейность.
Деформируемая свертка (Примечания отсюда)
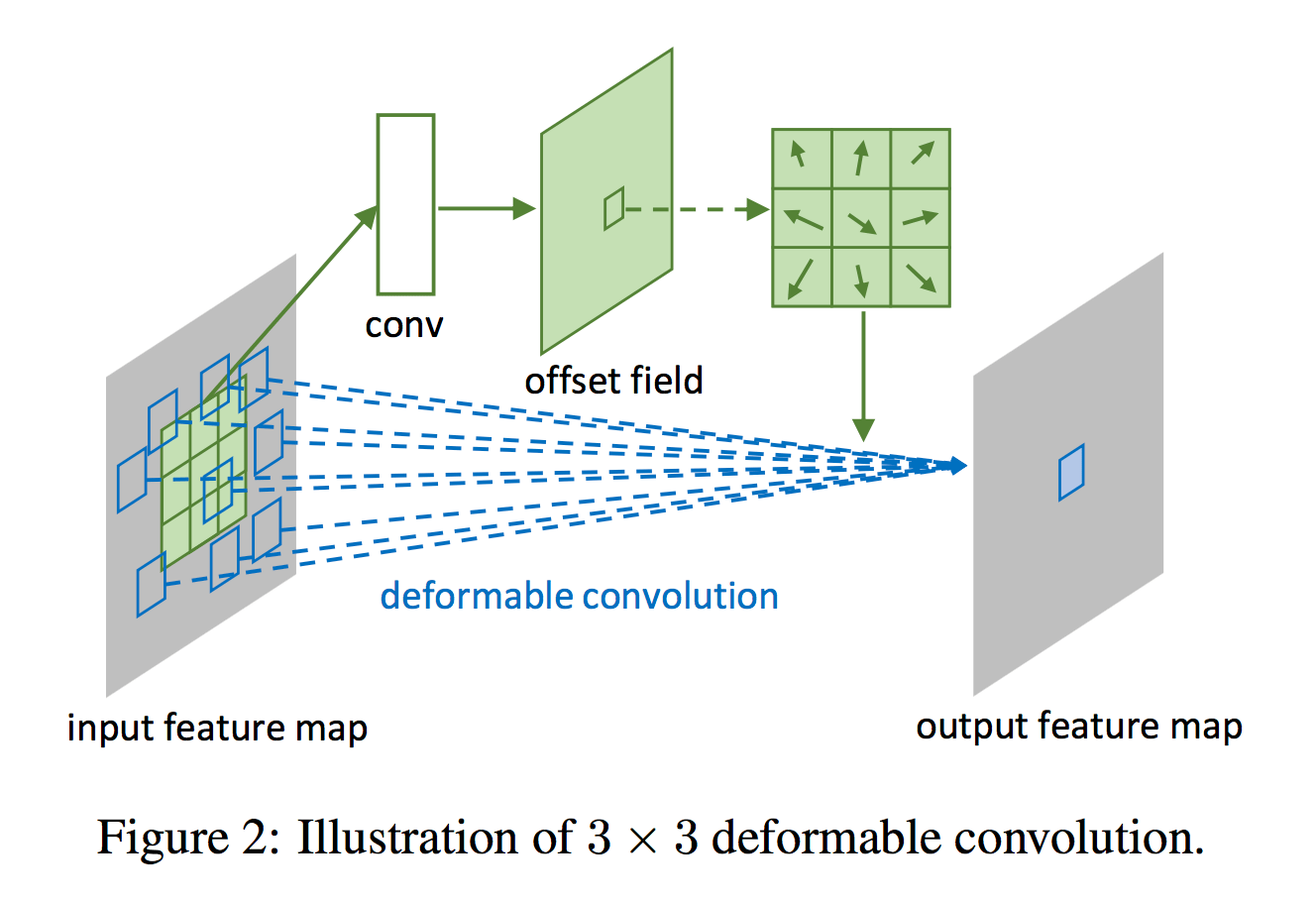
- Деформируемая свертка состоит из 2 частей: регулярной свертки. слой и еще один конв. слой, чтобы узнать 2D-смещение для каждого входа. На этой диаграмме обычная конв. слой подается в синих квадратах вместо зеленых квадратов.
- Если вы запутались (как и я), вы можете думать о деформируемой свертке как о «обучаемой» расширенной (атрозной) свертке, скорость которой изучается и может быть разной для каждого ввода. Раздел 3 будет отличным чтением, если вы узнаете больше о взаимосвязи деформируемой свертки с другими методами.
- Поскольку смещения не являются целыми (дробными), для выборки из входной карты объектов используется билинейная интерполяция. Автор указывает, что это можно эффективно вычислить. (время прямого прохождения см. в таблице 4)
- Двухмерные смещения кодируются в размерности канала (например, сверточный слой из
nканалов соединен со смещенным сверточным слоем из2nканалов) - Обратите внимание, что смещения инициализируются на
0, и скорость обучения для этих слоев смещения не обязательно такая же, как у обычного сверточного слоя (но они по умолчанию в этой статье) - Авторы эмпирически показывают, что деформируемая свертка способна «расширить» рецептивное поле для более крупного объекта. Они измеряют «эффективное расширение», которое представляет собой среднее расстояние между каждым смещением (т.е. синие квадраты на рис. 2). Они обнаружили, что деформируемые фильтры, которые сосредоточены на более крупных объектах, имеют большее «воспринимающее поле». Увидеть ниже.

Деформируемый пул ROI

- Деформируемый пул RoI также состоит из 2 частей: обычного уровня пула RoI и еще одного полностью связанного слоя для изучения смещения.
- Вместо того, чтобы прогнозировать необработанное смещение (в пикселях), смещения нормализуются (т. Е. Делятся) на ширину и высоту области RoI, так что она инвариантна к размеру RoI.
- Существует любопытный постоянный скаляр
gamma, который дополнительно масштабирует нормализованное смещение. (?)
Свертка с разделением по глубине (более подробную информацию можно найти здесь)
В нейронных сетях мы обычно используем то, что называется разделимой по глубине сверткой. Это выполнит пространственную свертку, при этом каналы будут разделены, а затем последует свертка по глубине. На мой взгляд, это лучше всего можно понять на примере.
Допустим, у нас есть сверточный слой 3x3 на 16 входных и 32 выходных каналах. Что происходит в деталях, так это то, что каждый из 16 каналов проходит через 32 ядра 3x3, в результате чего получается 512 (16x32) функциональных карт. Затем мы объединяем 1 карту функций из каждого входного канала, складывая их. Так как мы можем сделать это 32 раза, мы получаем 32 выходных канала, которые нам нужны.
Для разделимой по глубине свертки в том же примере мы просматриваем 16 каналов с 1 ядром 3x3 в каждом, что дает нам 16 карт характеристик. Теперь, прежде чем что-либо объединять, мы просматриваем эти 16 карт функций с 32 свертками 1x1 каждая и только затем начинаем их складывать. В результате получается 656 (16x3x3 + 16x32x1x1) параметров, а не 4608 (16x32x3x3) параметров, указанных выше.
Пример представляет собой конкретную реализацию разделимой по глубине свертки, где так называемый множитель глубины равен 1. Это, безусловно, наиболее распространенная настройка для таких слоев.
Мы делаем это из-за гипотезы о том, что пространственная и глубинная информация может быть разделена. Если посмотреть на производительность модели Xception, кажется, что эта теория работает. Разделимые по глубине свертки также используются для мобильных устройств из-за эффективного использования параметров.
Обычная свертка
Свертка KxK с шагом S - это обычная операция скользящего окна, но на каждом шаге вы перемещаете окно на S элементов. Элементы в окне всегда являются смежными элементами входной матрицы. Для S = 1 у вас есть стандартная свертка. Для S ›1 вы получаете эффект понижающей дискретизации. Вы также можете обобщить эту операцию до 0 ‹S‹ 1 (свертка с дробным шагом); в этом случае вы получаете эффект повышающей дискретизации.
Эта свертка является инвариантным переводом (инвариантным к местоположению), см. Подробности.

Совместное использование параметров:
Кросс-корреляция
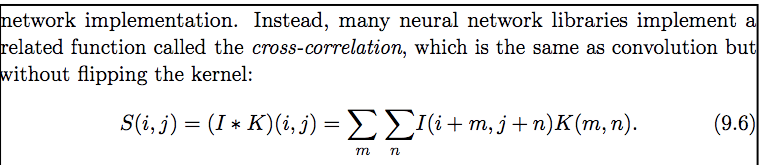
Дилатационная свёртка, также называемая атрозной свёрткой
D-расширенная свертка KxK отличается. Это даже называется «свертка с расширенным фильтром», потому что это эквивалентно расширению фильтра перед выполнением обычной свертки. Расширение фильтра означает увеличение его размера, заполняя пустые позиции нулями. На практике расширенный фильтр не создается; вместо этого фильтрующие элементы (веса) сопоставляются с удаленными (не соседними) элементами во входной матрице. Расстояние определяется коэффициентом расширения D. На изображении ниже показано, как элементы ядра сопоставляются с входными элементами в D-расширенной свертке 3x3.


Для простой старой свертки это будет ft - τ. В расширенной свертке ядро касается сигнала только при каждой l-й записи. Эта формула применяется к одномерному сигналу, но ее можно напрямую расширить до двухмерных сверток.
Продукт Кронекера
Пропустить соединение
ResNet и составляющие его остаточные блоки получают свои названия от «остатка» - разницы между прогнозируемыми и целевыми значениями. Авторы ResNet использовали остаточное обучение в форме H (x) = F (x) + x. Просто это означает, что даже в случае отсутствия остатка, F (x) = 0, мы все равно сохраним тождественное отображение входа x. Полученный в результате выученный остаток позволяет нашей сети теоретически работать не хуже (чем без него).
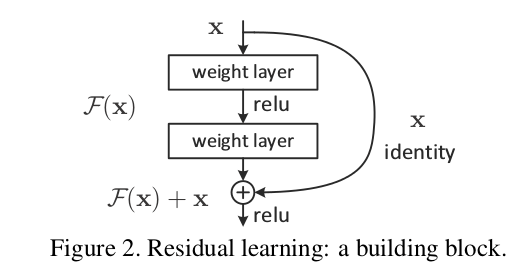
Остаточные соединения и пропущенные соединения используются взаимозаменяемо. Эти типы соединений могут пропускать несколько слоев (см. Стр. 4 оригинального документа ResNet), а не только один. Короче говоря, остаточные соединения используются для упрощения оптимизации более глубоких сетей. [1]
Глазок подключения
Соединения с глазком перенаправляют состояние ячейки как вход на вход, выход LSTM и ворота забвения. Вы можете изучить их подробно, прочитав оригинальные статьи профессора Феликса Жерса [2] [3]. Эти соединения используются для определения точного времени.
Ссылка:
[1] Кайзер, Лукаш, Эйдан Н. Гомес и Франсуа Шоле. «Глубоко разделимые свертки для нейронного машинного перевода». Препринт arXiv arXiv: 1706.03059 (2017).
[2] Джин, Джонхун, Айсегуль Дундар и Эухенио Кулурчелло. «Сглаженные сверточные нейронные сети для ускорения с прямой связью». Препринт arXiv arXiv: 1412.5474 (2014).