В предыдущих частях мы видели:
- как реализовать асинхронный процесс с отслеживанием состояния, сравнивая реализации Akka Actors, Akka Typed Actors, Monix и ZIO (Scalaz 8 IO).
- как можно смоделировать коммуникацию между асинхронными процессами
В этой последней части мы рассмотрим последнюю особенность, которая выделяет акторов: обработка ошибок, контроль и иерархия акторов.

О чем это все? Что-то постоянно терпит неудачу. Всякий раз, когда вы общаетесь с внешней системой, может возникнуть сетевая ошибка; в сервисе может быть ошибка; запросы могут быть искажены; серверы могут быть недоступны; и т.п.
Обработка ошибок часто является важной частью нашего приложения. Поскольку его площадь поверхности очень велика, он имеет тенденцию проникать в каждый угол нашего кода и усложнять его чтение и понимание. Вот почему предпринимаются многочисленные попытки сдержать ситуацию и отделить код обработки ошибок от бизнес-логики.
В случае успеха мы получим четкую и понятную бизнес-логику, а также понятную и удобочитаемую логику обработки ошибок. Другая часть задачи - получить определенную степень уверенности в том, что наша обработка ошибок действительно работает!
Akka заимствует философию Erlang пусть он рухнет. Ключевая идея - не пытаться обрабатывать все ошибки в процессе. Во-первых, это приводит к путанице кода ошибки с бизнес-логикой. Во-вторых, субъекту может просто не хватать контекста, чтобы исправить ошибку.
Например, если есть субъект, единственная ответственность которого - считывать данные из системы очередей, а соединение с очередью разрывается, что ему делать? Восстановить соединение? Но как, если это не ответственность актера?
Вот для чего нужны иерархии контроля в Akka (и Erlang, и других реализациях акторов). У каждого актера есть родитель; если ошибка не обрабатывается субъектом, она передается родительскому объекту. Родитель может решить, следует ли возобновить, перезапустить, остановить дочерний процесс или передать ошибку его родительскому процессу.
Родитель, прародитель и т. Д., Субъекты могут иметь все больше и больше контекста и, следовательно, могут иметь возможность запускать соответствующую логику - например, воссоздание соединения с очередью и создание нового дочернего актора, который будет читать из очереди.
Используя иерархии надзора, мы также достигаем того разделения задач, к которому мы стремились: бизнес-логика находится в актере, а логика обработки ошибок - в супервизоре.
Акка
Как и в предыдущих частях, мы начнем с примера Akka и посмотрим, как реализовать ту же логику с помощью Akka Typed, Monix и Zio. В этом примере мы:
- подключиться к внешней системе очередей через признак
QueueConnector - после получения подключенного
Queueэкземпляра читать из очереди - пересылать любые сообщения заинтересованным потребителям
- при любых ошибках попытайтесь повторно подключиться, предварительно пытаясь
close()подключиться к старой очереди.
Вот основные черты, с которыми мы будем работать:
Признаки параметризуются с помощью типа оболочки (высшего порядка) F[_], который должен быть способен отображать как успешные, так и неудачные вычисления. В примере с Akka мы будем использовать QueueConnector[Future] и Queue[Future], так как это тип контейнера, с которым Akka работает лучше всего.
Мы реализуем шаблон, который также известен как ядро ошибки. Мы сохраним важное состояние safe & protected в родительском акторе: здесь состояние будет набором зарегистрированных потребителей сообщений (которым должны пересылаться сообщения, прочитанные из очереди). Рискованные операции, которые могут привести к сбою: подключение к очереди и получение данных из очереди, будут делегированы дочернему субъекту. Таким образом, даже если дочерний актер выйдет из строя, состояние не будет потеряно.
Родительский субъект будет получать сообщения двух типов:
Subscribe, чтобы добавить субъекта к набору потребителей, заинтересованных в получении сообщений, и Received, отправляемого дочерним субъектом, когда новое сообщение было получено из очереди. Логика подписки и обработки полученных сообщений довольно проста:
Но с одним этим определением ничего действительно не произойдет, поскольку мы никогда не пытаемся подключиться к очереди. Вот почему, когда запускается вещательный (родительский) актер, мы порождаем дочернего актера:
Чем занимается ребенок-актер? Его внутреннее состояние будет состоять из подключенного в данный момент экземпляра Queue (если есть). Еще раз воспользуемся обратным вызовом preStart, чтобы попытаться подключиться к очереди сразу после запуска актера. Поскольку это асинхронная операция, мы pipeTo результат передаем актору. Таким образом, результат операции подключения будет отправлен актору в виде сообщения:
Как только подключенная очередь получена, мы можем начать читать сообщения из нее. Каждое сообщение, когда оно станет доступным, будет перенаправлено родительскому субъекту в Received. После получения сообщения мы можем получить следующее, отправив очередь self (текущий актер):
Но что, если произошла ошибка? Если либо connector.connect.pipeTo(self), либо queue.read().pipeTo(self) выйдет из строя, актер получит сообщение Failure(e). Мы действительно не знаем, что с этим делать, поэтому идем по простейшему пути: повторно генерируем ошибку, что приведет к сбою актора, и, следовательно, распространяем ошибку на родительский объект.
Какой бы ни была причина остановки дочернего актора (сбой или обычное завершение работы приложения), мы делаем последнюю попытку очистить в методе postStop:
Если есть какой-либо подключенный Queue экземпляр (его может не быть, если подключение не удалось), мы пытаемся вызвать его close() метод. Поскольку это асинхронный процесс, а метод postStop является синхронным, у нас нет другого выбора, кроме как использовать Await.result.
И это все, что касается ребенка-актера; обратите внимание, что кода обработки ошибок почти нет (за исключением повторной генерации каких-либо исключений).
Что будет делать родитель, если ребенок потерпит неудачу? Это зависит от стратегии наблюдения. По умолчанию используется Restart дочерний элемент для «нормальных» исключений. Стратегия определена в родительском акторе как переопределяемый метод:
Здесь у нас есть простая иерархия с одним дочерним актором, но в более сложных примерах, помимо перезапуска актора (один к одному), есть также возможность перезапустить все дочерние акторы, если только один из них выйдет из строя. (все для одного).
Кроме того, существует некоторая гибкость в том, как перезапускается дочерний актер. Один из вариантов - использовать отсрочку, то есть перезапуск дочернего актора не сразу, а после (растущей) задержки. Если система не работает, вполне возможно, что она выйдет из строя, если мы попробуем снова сразу после сбоя. Но если немного подождать, у него больше шансов вернуться в форму. Это возможно, заключив дочерний актер в BackoffSupervisor.
Приведенный выше пример доступен в репозитории GitHub вместе с тестами, имитирующими сбои на различных этапах работы приложения. Идет довольно много журналов, поэтому вы можете наблюдать, что происходит в каждый момент, когда и если актеры создаются и перезапускаются.
Akka Typed
Реализация Akka Typed немного отличается в двух аспектах. Прежде всего, обработка сбоев не привязана к родительскому субъекту. Вместо этого это оболочка для поведения, которое дает нам большую гибкость. Обработка сбоев может быть определена в родительском элементе или может быть предопределена поведением дочернего актора.
Во-вторых, если родительские акторы порождают несколько дочерних акторов, каждый из них может иметь разную обработку супервизора - в отличие от «глобальной» конфигурации стратегии наблюдения в «традиционном» подходе Akka.
Чтобы реализовать наш пример, мы определим broadcastBehavior, который будет описывать, как должен вести себя родительский субъект. Он будет обрабатывать те же два типа сообщений, что и раньше, но поскольку нам нужно параметризовать поведение с помощью одного типа, мы вводим общую черту:
Логика обработки сообщений не будет иметь изменяемого состояния. Вместо этого это снова будет метод, параметризованный с состоянием - набором субъектов-потребителей - который вызывается рекурсивно:
Но, прежде чем обрабатывать какие-либо BroadcastActorMessage, мы должны попытаться подключиться к очереди и начать получать сообщения. Мы сделаем это в отдельном актере, порожденном при первом создании поведения трансляции:
Мы используем Behaviors.supervise, чтобы обернуть поведение дочернего актора (connectToQueueBehavior, которое мы определим дальше), чтобы всякий раз, когда происходит RuntimeException, актор перезапускался. Обратите внимание, что supervise - это оболочка для любого Behavior, дающая новый Behavior. Мы могли бы определить его полностью отдельно и вне родительского актора. В зависимости от варианта использования может быть более логичным определить его внутри или вне супервизора.
Еще проще, чем раньше, мы также можем использовать отложенный перезапуск с отсрочкой, используя SupervisorStrategy.restartWithBackoff (и другие) вместо SupervisorStrategy.restart, как в этом случае.
Между традиционным Akka и Akka Typed есть важное различие. В предыдущем подходе мы видели, что стратегия супервизора по умолчанию для нормальных исключений заключается в перезапуске дочернего субъекта. В Akka Typed по умолчанию установлено остановить дочернего актера. Вот почему нам нужно явно указать, что делать при дочерних сбоях, используя
onFailure.
Второе отличие от предыдущей реализации состоит в том, что дочерний субъект фактически будет состоять из двух субъектов: один для подключения к очереди, другой для подключенной очереди. Причина, по которой нам нужны не только два поведения, но и два субъекта, заключается в том, что оба они будут обрабатывать разные типы сообщений. Это небольшая цена, которую нам придется заплатить за безопасность типов.
Мы не будем отправлять никаких сообщений от родительского актора дочернему актору, поэтому его тип с точки зрения родительского актора будет Behavior[Nothing]. Однако внутри актора мы отправляем сообщение, содержащее подключенную очередь, поэтому нам нужно создать поведение, которое принимает Try[Queue[Future]], а затем скрыть этот факт от родителя с помощью narrow:
Используя ссылку на себя из контекста, мы отправляем сообщение самому себе после подключения очереди (connector.connect.andThen { case result => ctx.self ! result }). Если это сбой, мы повторно генерируем ошибку, что вызывает вызов супервизора в родительском элементе. В случае успеха мы создаем дочерний субъект с поведением, потребляющим очередь (consumeQueueBehavior, определено ниже).
Обратите внимание, что вместо обратного вызова preStart в Akka Typed мы просто создаем поведение, которое запускает желаемый код при настройке актора (с использованием Behavior.setup), а затем возвращает «правильное» поведение. В этом актере нет зацикливания, он всегда получает только одно сообщение.
Но это еще не конец. Если субъект, потребляющий очередь, выходит из строя, нам нужно передать эту ошибку родительскому объекту. Это не делается автоматически, нам нужно наблюдать за новым дочерним актером (используя ctx.watch). Тогда единственное, что остается сделать в актере, - это дождаться сигнала завершения дочернего элемента (когда что-то пойдет не так) и передать его родителю.
Сигналы завершения отправляются по другому каналу, чем обычные сообщения акторов, отсюда и специальная фабрика поведения (Behavior.receiveSignal вместо обычного Behavior.receiveMessage).
Наконец, мы переходим к поведению потребителя очереди:
Подобно «традиционной» реализации Akka, мы вызываем чтение из очереди, и как только сообщение готово, мы пересылаем его себе (queue.read().andThen { case result => ctx.self ! result }). Как только сообщение получено, мы отправляем его в приемник (который будет родительским субъектом) и рекурсивно вызываем то же поведение.
В случае сбоя мы просто генерируем исключение. Это вызовет уведомление субъекта, подключающегося к очереди, который, в свою очередь, уведомит родительский субъект.
Как насчет закрытия очереди до того, как субъект-потребитель очереди закончит работу (по какой-либо причине)? Здесь нет postStop метода, который можно было бы переопределить, как раньше. Вместо этого мы модифицируем созданное поведение, добавляя обработчик receiveSignal. Если мы получаем сигнал PostStop, мы пытаемся закрыть очередь. Опять же, нам нужно синхронно вернуть новое поведение, но действие закрытия является асинхронным - отсюда и необходимость в Await.
Здесь важно отметить, что мы снова используем тот факт, что Behaviors, как и Task Моникс и IO Зио, ленивы. Это позволяет изменять (рекурсивное) поведение путем добавления дополнительных обработчиков или метаданных. Здесь мы модифицируем Behaviors.receiveMessage[Try[String]], чтобы также был установлен обработчик сигналов. Если бы поведение выполнялось с готовностью, receiveSignal никогда не вызывался бы.
Еще один случай, когда удобно отделить описание вычисления от его интерпретации.
Monix
Давайте начнем изучать реализацию Monix с конца, то есть с описания задачи, которая будет подключаться к очереди, получать сообщения из нее и закрывать ее в конце (либо из-за нормального завершения, либо из-за ошибки).
Вместо использования хуков жизненного цикла (preStart, postStop в Akka) мы просто определим процесс, который последовательно выполняет шаги подключения-потребления-закрытия.
Как и в предыдущих частях, для связи с родительским процессом мы будем использовать MVar (ограниченную очередь с одним элементом), в которой будут храниться элементы типа BroadcastMessage:
Затем мы определим три отдельных задачи, которые подключаются к очереди, потребляют элементы из очереди и, наконец, закрывают ее:
Определения задач довольно просты: они просто вызывают соответствующие методы в connector или подключенном queue экземпляре и выполняют дополнительную регистрацию. Обратите внимание, что consumeQueue никогда не завершится нормально, так как после чтения одного сообщения и отправки его родительскому процессу (с использованием inbox.put(Received(msg))) он всегда перезапускается для чтения другого сообщения (restartUntil(_ => false)).
Task[Queue[Task]]может выглядеть странно, но ... это задача, которая при запуске создаетQueue, который, в свою очередь, обертывает результаты своего метода вTask.
Как объединить эти три задачи в единое целое? Мы будем использовать bracket:
Обратите внимание, что мы используем
inboxв качестве имени канала связи между потребляющим и широковещательным процессами, чтобы избежать конфликтов имен, посколькуQueueуже используется нашим доменным классом.
bracket в операторе, который образует один из основных строительных блоков обработки ошибок в Monix (а также в ZIO). Это эквивалент хорошо известной конструкции try ... catch ... finally из Java / Scala. Задача connect должна распределять ресурсы; тогда первый параметр в скобках - это использование ресурсов. Независимо от того, как заканчивается часть использования ресурсов (либо завершение задачи, либо ошибка, либо волокно отменяется), гарантируется, что третья задача, освобождающая ресурсы, также будет оценена. .
И это именно то, что нам нужно! Используя bracket, мы можем гарантировать, что будет хотя бы попытка закрытия очереди, однако потребление очереди закончится.
Не совсем ясно, что произойдет, если части, связанные с использованием и высвобождением ресурсов, выдают ошибку. Какую ошибку получит пользователь? Это первый, а второй будет отброшен. Важная деталь, о которой нужно помнить.
Вышеупомянутое гарантирует правильное поведение при возникновении ошибки. Но что, если мы просто хотим закончить процесс изящно? Возможно, нас больше не интересует использование очереди. С Аккой этого было достаточно, чтобы остановить актера. Здесь мы должны использовать отмену.
В предыдущих частях мы также использовали Fiber.cancel для завершения разветвленного (асинхронного) процесса. Здесь логика потребления также будет выполняться асинхронно (как мы скоро увидим ниже). Если пользователь решает, что потребление очереди должно прекратиться, отмена - единственная надежда разорвать бесконечный цикл потребления.
Однако есть одна загвоздка: по умолчанию многое нельзя отменить. Например, цепочка infitite flatMap в consumeQueue (если мы развернем рекурсивные вызовы) никогда не будет отменена. Вот почему нам нужно добавить границу отмены, используя cancelable. Это приведет к тому, что цепочка плоской карты позволит остановиться на полпути.
По сути, cancelable указывает интерпретатору задачи, что, когда он получает запрос отмены для волокна (легковесный поток), и есть возможность прекратить выполнение задачи - например, потому что интерпретатор только что завершил одну flatMap операцию и вот-вот запустит еще одну - задача будет отменена.
Пока мы говорили только о подключении к очереди. А что насчет остальных? Нам все еще нужно определить процесс рассылки сообщений, который будет отправлять прочитанные сообщения заинтересованным потребителям. Для этого мы создаем задачу, которая будет обрабатывать как сообщения Subscribed, так и Received:
Ничего необычного, чего мы раньше не видели. Мы описываем нескончаемый процесс, который считывает сообщения из очереди, сопоставляет их с соответствующими задачами (при необходимости обновляет внутреннее состояние - набор consumers) и рекурсивно вызывает себя.
Нам все еще нужно определить, как и когда следует перезапустить процесс потребления:
Эта часть определения процесса вещания соответствует стратегии супервизора. Когда задача consume терпит неудачу - что может произойти только из-за ошибки - мы должны решить, что делать. Здесь мы просто регистрируем результат и перезапускаем процесс, как restart супервизора.
Хотя это и не встроено, здесь мы можем использовать механизм отсрочки или ограниченного повтора; однако нам придется кодировать это вручную.
Нам также удалось сохранить разделение между бизнес-логикой и логикой обработки ошибок, однако здесь это не обеспечивается с помощью специального механизма. Вместо этого мы разделяем Task описание на «одну» consume задачу и задачу, которая управляет перезапусками. Создание подробных описаний задач с единственной ответственностью - это один из способов создания удобочитаемого и поддерживаемого кода при использовании Monix.
Наконец, нам нужно связать все части вместе и запустить фоновые процессы:
Чтобы начать трансляцию, мы запускаем два асинхронных процесса: один потребляет из очереди в цикле, а другой обрабатывает сообщения. Два процесса взаимодействуют через inbox MVar.
Тип возвращаемого значения метода состоит как из папки «Входящие», чтобы внешние клиенты имели возможность подписывать новых потребителей, так и из задачи, которая при запуске отменяет весь процесс. Обратите внимание, как тот факт, что Task является ленивым, позволяет нам просто создать описание логики отмены: f1.cancel *> f2.cancel (*> отображает две задачи, отбрасывая результат первой), не опасаясь преждевременного запуска отмены.
Отмена f1 приведет к освобождению скобки, а отмена f2 приведет к тому, что сообщения больше не будут считываться из inbox.
ЗИО
Наконец, давайте посмотрим, как ZIO обрабатывает ошибки. Как и ожидалось, реализация очень похожа на Monix, однако временами это может быть обманчивым: есть некоторые очень важные различия, особенно в модели отмены.
Однако общая структура решения такая же, как и раньше. Мы будем использовать те же два сообщения для связи с процессом трансляции:
С той разницей, что в Subscribe потребитель возвращает IO вместо Task или Future. В том же порядке, что и в предыдущем разделе, описание того, как должно работать потребление очереди, выглядит знакомо:
Оператор bracket работает так же, как и в Monix (хотя аргументы release-resource и use-resource поменяны местами): он гарантирует, что, если действие connect завершится успешно, releaseQueue будет оценено (закрытие открытого подключение очереди), как при нормальном завершенииconsumeQueue, так и при ошибке.
Однако в коде есть два важных отличия. Прежде всего, в consumeQueue вы могли заметить, что в версии Monix мы должны были явно пометить flatMap-chain как cancelable, чтобы можно было остановить потребление очереди извне. В этом нет необходимости: flatMap цепочки по умолчанию автоматически отменяются.
Во-вторых, часть выпуска-ресурса в bracket должна обрабатывать все ошибки: и это обеспечивается системой типов, поскольку тип параметра ресурса-выпуска - A => IO[Void, Unit]. Вот почему нет проблем, что делать, если действие по выпуску приводит к ошибке: обычные ошибки невозможны (как указано в типе), и если действие действительно вызывает исключение (что всегда возможно), это считается программным дефектом, о чем будет сообщено диспетчеру волокна и / или в журнале.
Реализация процесса broadcast напрямую соответствует реализации Monix без существенных отличий:
Повторим предыдущее описание: мы создаем два процесса, один из которых пытается подключиться к очереди и потреблять сообщения из нее (consumerForever), при необходимости перезапуская всю процедуру. Второй (processMessages) поддерживает состояние - набор текущих подписчиков (и, следовательно, реализует шаблон Error Kernel). В результате всего действия мы возвращаем:
- очередь, в которую могут быть отправлены новые подписчики
- способ остановить весь процесс
Остановка процесса включает, как и раньше, прерывание волокна, которое пытается подключиться к очереди и потребляет сообщения из нее, и другого волокна, которое передает входящие сообщения.
Прерывание в ZIO и отмена в Monix
То, как прерывание и отмена работают в ZIO и Monix, является одним из их отличительных отличий, поэтому имеет смысл сравнить их бок о бок.
Создание отменяемых действий
В Monix отменяемые действия можно создавать с помощью:
Task.create, где пользователь должен предоставитьCancelableэкземпляр, который должен остановить (или попробовать) асинхронные вычисления. После отмены этот обратный вызов может выполняться одновременно с отмененным действием.- Оператор
cancelable, из-за которого цепочкиflatMapвTaskстановятся отменяемыми (по умолчанию это не так).
В ZIO у нас есть:
IO.async0, где пользователь должен предоставитьCanceler, который будет запущен при отмене действия. Отмена может быть запущена одновременно с отмененным действием.flatMapцепочки отменяются по умолчанию, нет необходимости явно отмечать их как таковые.
Обе библиотеки предлагают операторы uncancelable (Monix) / _ 121_ (ZIO), которые предотвращают отмену описанного действия, даже если оно построено на основе отменяемых операций.
Ни в одной из библиотек атомарные действия (например, одиночный flatMap шаг или завернутый синхронный код) не будут прерваны / отменены, например. используя Thread.interrupt.
Отмена волокон
Еще одним важным отличием является способ работы задач отмены / прерывания волокна. В Monix волокна можно прервать, оценив задачу, возвращаемую методом Fiber.cancel: Task[Unit]. Эта задача будет завершена после отправки сообщения об отмене.
В ZIO есть метод Fiber.interrupt(t: Throwable): IO[E, Unit]. Это похоже на то, что при оценке оно прерывает целевое волокно. Но он также отличается в двух аспектах. Во-первых, мы можем указать конкретную причину прерывания (исключение). Затем эта причина будет сообщена любому действию, которое пытается присоединиться к прерванной оптоволоконной линии, или супервизору оптоволокна, разрешая регистрацию или перезапуск.
Второе важное отличие состоит в том, что действие, возвращаемое interrupt, будет завершено только после успешного прерывания или окончания волокна. Если нам нужна семантика прерывания и забывания от Monix, это может быть достигнуто путем разветвления прерывания волокна в волокно (.interrupt(...).fork).
Что можно отменить
Когда можно отменить отмену? И Monix, и ZIO предоставляют способ отмены / прерывания работающего волокна, как описано выше.
Кроме того, когда задача Monix выполняется асинхронно, например используя runAsync, он возвращает CancelableFuture. Это расширение обычного Future, которое может дополнительно отменить текущее вычисление с помощью метода cancel() с побочными эффектами.
ZIO не имеет таких возможностей, однако тот же эффект может быть достигнут, если выполнить действие IO для волокна и получить (через синхронный unsafePerformIO) экземпляр Fiber, который затем может быть прерван.
Убираться
И в Monix, и в ZIO есть оператор bracket, который работает одинаково: при применении к действию создания ресурса он гарантирует, что действие высвобождения ресурса будет запущено после успешного завершения действия использования ресурса, с ошибкой или отменяется.
ZIO также имеет несколько удобных псевдонимов, например ensuring (соответствует finally) и bracketOnError.
Обратные вызовы при отмене
Можно ли узнать, что действие было отменено в самом действии?
У Monix есть два таких оператора. Во-первых, doOnCancel(cb: Task[Unit]) запускает данную задачу при отмене (есть также аналог, который запускается при нормальном завершении задачи, doOnFinish). Следовательно, это «частичная скобка».
Второй, onCancelRaiseError, вызывает сбой действия с данным исключением, вместо того, чтобы стать непрекращающимся при отмене. Невозможно указать причину отмены в отменяющем волокне, но можно указать ее в отмененном волокне. С другой стороны, в ZIO можно указать причину только в прерывании волокна, а прерванное волокно всегда является оконечным - за этим исключением.
ZIO не имеет операторов, которые позволили бы узнать в прерванном виде, что произошло прерывание. Вместо этого о прерывании будет сообщаться любым действиям, которые пытаются join прервать оптоволокно.
Оптоволоконные супервайзеры
ZIO имеет два дополнительных механизма для контроля оптоволокна, которые не имеют аналогов в Monix.
Первый - это контролеры оптоволокна. При разветвлении IO волокна можно указать обработчик, который будет вызываться для любых исключений, не обрабатываемых волокном: fork0[E2](handler: Throwable => Infallible[Unit]). Если это похоже на супервайзеров в актерах - должно!
Если супервизор не указан, используется супервизор по умолчанию, который регистрирует исключение.
Второй механизм - это IO.supervised(t: Throwable) метод, который заставляет любые разветвленные волокна как часть оценки данного действия прерваться с данным исключением, как только это действие завершится. Опять же, это похоже на то, что все дочерние акторы останавливаются, когда останавливается родительский актор, однако здесь это необязательно, а не обязательно.
Мы видели пример использования этой функции в части 2, где рабочие волокна были автоматически прерваны после завершения работы краулера.
Резюме
Является ли Monix или ZIO альтернативой акторам Akka? Да: инкапсуляция состояния, обмен данными и обработка ошибок / контроль могут быть реализованы с помощью Tasks или IO действий без особых усилий на в то же время сохраняя код читабельным и поддерживаемым более безопасным способом.
Тем не менее, Akka не отстает, поскольку в самой Akka есть альтернатива «традиционным» акторам Akka: типизированный Akka, который, безусловно, также является жизнеспособной альтернативой.
Какой бы подход мы ни выбрали, как мы видели в примерах, представленных в трех частях серии, общая структура решений, написанных с использованием четырех подходов, одинакова:
- все они используют асинхронную передачу сообщений
- все они общаются с помощью очередей: неявных почтовых ящиков акторов или явных очередей
- все они используют одновременно выполняющиеся независимые легковесные процессы: акторы или волокна.
Однако, как говорится, дьявол кроется в деталях: уровень безопасности типов, модель оценки, надзора, отмены и обработки ошибок существенно различаются. Ниже приводится сводка различных функций, которые мы рассмотрели в этой серии (также доступны в текстовом формате в Google Таблицах):
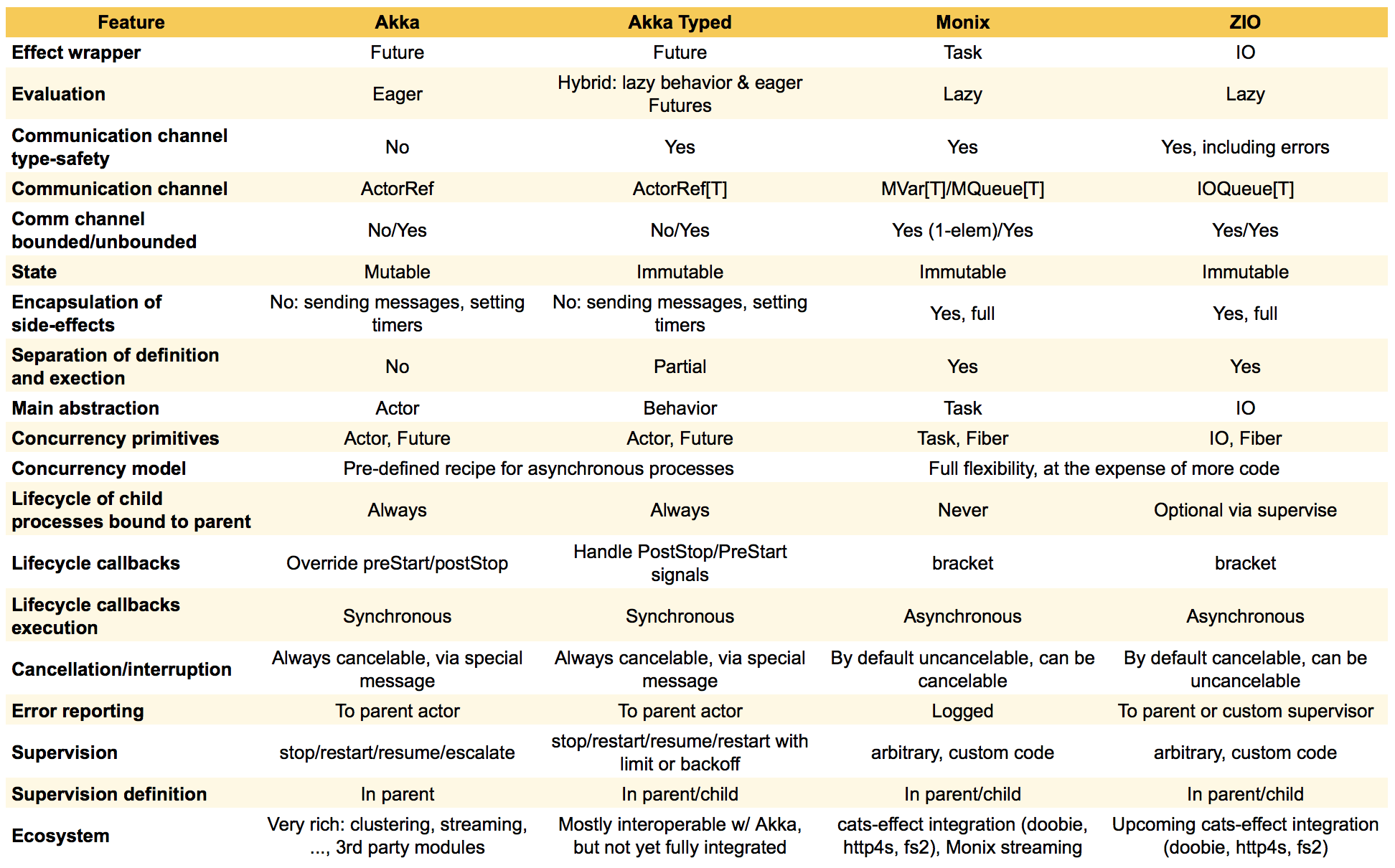
Важное отличие - выбор примитивов. В Akka основной конструкцией является актер, а в Monix / ZIO есть _148 _ / _ 149_ действия, которые являются более низкоуровневыми, но, следовательно, также более гибкими. Акторы - это предопределенный рецепт для создания асинхронного процесса.
Это ограничение Акки? В некоторой степени да, однако акторы также очень естественный способ думать о параллельных системах.
Актеры, которые:
- заниматься своим делом
- защитить свое внутреннее состояние
- общаться с другими, используя сообщения типа "запустил и забыл"
- иерархии надзора за формами
ограничить способы определения асинхронных процессов, а также предоставить отличную основу для моделирования, понимания и обсуждения параллельных систем, что всегда является сложной задачей. Стоит обратить внимание на все, что помогает уменьшить сложность, присущую распределенной системе.
Вот почему даже при описании процесса с помощью Monix или ZIO, в дополнение ко многим другим «получателям», которые можно определить с помощью Tasks / IOs, понятие актера все еще очень полезно, и поэтому мы стараемся подражать этому.
Если вы хотите продолжить исследовать и поэкспериментировать с примерами или взять Akka / ZIO / Monix в качестве тестового диска, используя примеры в качестве скелета, код доступен вместе с тестами на GitHub. . Просто импортируйте в свою любимую среду IDE и попробуйте реализовать свой вариант использования, используя четыре подхода!
Резюме: краткая версия
- Akka: наиболее зрелое и популярное решение с большой экосистемой. Однако основной конструкции - акторам - не хватает типобезопасности, что, помимо ошибок программирования, может затруднить понимание того, как организована связь в системе.
- Типизированный Akka: новый подход к определению и запуску субъектов, использующий типобезопасную, компонуемую и ленивую конструкцию - поведения. Шаблоны общения легче просматривать. Хорошо интегрируется с экосистемой Akka. Некоторые побочные операции остаются, такие как планирование или отправка сообщений.
- Monix: довольно хорошо зарекомендовавшая себя библиотека, которая обеспечивает безопасный для типов способ описания и управления ленивыми параллельными процессами с использованием богатого набора комбинаторов. Помимо полной инкапсуляции побочных эффектов, также есть модуль, реализующий реактивную потоковую передачу.
- ZIO: новейший претендент, который развивает подход Monix к описанию ленивых вычислений, предлагая типобезопасные ошибки и контроль. Делает упор на корректное прерывание, волокна и конструкции безопасности ресурсов.
Код, который мы пишем, становится все более параллельным, что создает новые проблемы и поднимает важность удобочитаемости кода на новый уровень. Экосистема Scala предлагает широкий спектр решений, которые различаются выбором примитивных конструкций, стилями программирования и типобезопасностью. Приятно иметь выбор, и, как показали недавние разработки в ZIO, Monix и Akka Typed, конкуренция действительно способствует развитию инноваций.
Хорошее время, чтобы стать программистом на Scala :)

Ищете экспертов по Scala и Java?
Мы заставим технологии работать на ваш бизнес. Посмотреть проекты, которые мы успешно реализовали.