Если вы новичок в анализе данных или науке о данных в целом, как и я, вы, вероятно, уже где-то слышали или читали о чем-то под названием Pandas.
Pandas — это библиотека Python с открытым исходным кодом, используемая для хранения, создания и анализа данных. В нем есть несколько отличных и действительно полезных инструментов, которые помогут вам правильно манипулировать данными.
В этой статье я постараюсь познакомить вас с основами Pandas. Моя цель — дать представление о том, каково работать с этой библиотекой, и объяснить некоторые инструменты, которые вы уже можете использовать полезным образом.
Как начать
Как и в любой другой библиотеке Python, вам придется импортировать Pandas. Соглашение состоит в том, чтобы импортировать его так:
import pandas as pd
Импорт его как «pd» может упростить задачу, поэтому вы можете просто вызвать метод, используя синтаксис «pd». вместо «панды».
Ряд
В Pandas серия — это, по сути, столбец значений с индексом.
Скажем, у вас есть список чисел Python. Вы можете создать из него серию pandas. Для этого вам понадобится список индексов, которые будут соответствовать этим значениям, почти как словарь Python:
my_list = [10, 20, 30, 40, 50] labels = ["a", "b", "c", "d", "e"] series = pd.Series(data = my_list, index = labels) print(series) Output: a 10 b 20 c 30 d 40 e 50 dtype: int64
Как вы можете видеть на выходе, Series взяла в качестве данных элементы списка, и каждый элемент имеет индекс, в данном случае метки.
Вы можете получить доступ к любому элементу Series по его индексу:
series["b"] Output: 20
Вы также можете выполнять операции между двумя сериями, но у этого есть особенность. Начнем с двух следующих серий:
series1 = pd.Series([1, 2, 3], ["NY", "NJ", "CA"]) series2 = pd.Series([1, 2, 3], ["NY", "AZ", "CA"])
Обратите внимание, что на этот раз я передал списки непосредственно в качестве аргументов. Вы можете сделать это, если делаете это в правильном порядке.
Если мы добавим эти две серии, поскольку они имеют только два индекса, «NY» и «CA», будут суммироваться только значения этих индексов.
print(series1 + series2) Output: AZ NaN CA 6.0 NJ NaN NY 2.0 dtype: float64
Как видите, поскольку «AZ» и «NJ» уникальны только для одной из двух серий, результат получается как NaN (не число).
кадры данных
Pandas DataFrames можно рассматривать как группу серий или таблицу данных. DataFrames организованы по столбцам и строкам, как электронная таблица Excel. Фактически, вы можете легко импортировать файлы Excel в pandas DataFrames, а также файлы csv, SQL, HTML и pickle.
Давайте прочитаем электронную таблицу Excel с именем «tests_table.xls»:

Как видите, DataFrame на самом деле представляет собой таблицу с именами столбцов и индексами строк. Здесь индексы строк — это просто числа, начинающиеся с 0, но это может быть что угодно. То же и с самими данными. Обратите внимание, что столбец «Имя» содержит строки, а остальные содержат числовые значения.
Вы можете получить доступ к любому конкретному столбцу или даже к набору столбцов. Для этого мы будем использовать обозначение квадратных скобок:

Если вы заметили, вывод похож на серию.
Вы также можете передать список имен столбцов:

Чтобы получить доступ к определенным значениям данных, вы можете использовать метод «loc»:
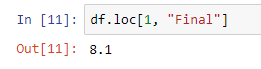
1 для строки с индексом 1 (строка, соответствующая розе), а затем столбцы с именем «Final». Выходом является соответствующее значение в этой позиции.
Вы также можете использовать метод «iloc». «i» означает индекс, и вместо имен вы передаете только индексы:

Здесь я продемонстрировал два способа получить тот же результат, что и раньше. В первом я передал сначала индекс для строки, к которой я хочу получить доступ, как и раньше, а затем индекс для «конечного» столбца. Помните, что счет начинается с 0, поэтому индекс для этого столбца равен 4. Второй способ, вместо 4, я просто передал -1, что указывает на последний столбец, независимо от того, сколько их.
Так же, как списки Python, вы можете использовать срезы:

Для строк 1:3 означает от строки с индексом 1 до 3, не включая последнюю. Для столбцов 2: означает от столбца с индексом 2 до конца.
Вы также можете проверить условные выражения, например, когда данные больше 7. Он возвращает логические значения:

Чтобы добавить новый столбец, вы можете сделать следующее:

Если вы хотите изменить индексы строк на что-то более значимое, вы можете использовать метод «set_index»:

В следующей части мы увидим еще несколько полезных функций, которые предоставляет нам библиотека.