Логистическая регрессия в алгоритме контролируемого машинного обучения, который используется, когда переменная ответа является категориальной.
Содержимое таблицы:-
- Определение
- Типы логистической регрессии
- Допущения логистической регрессии
- Почему логистика важнее линейной?
- Отношение шансов и логит
- Модель логистической регрессии
- Функция стоимости
- Показатели оценки
- Ссылки
Определение
Логистическая регрессия использует функцию логита, которая помогает найти взаимосвязь между независимой переменной и зависимыми переменными, предсказывая вероятность их результата.
Различные типы логистической регрессии:
- Биномиальная логистическая регрессия:- В этой целевой переменной может быть только два возможных результата. пример:- Да/Нет или Пройдено/Не пройдено и т. д.
- Мультиномиальная логистическая регрессия: - В этой целевой переменной может быть три или более возможных результата (результаты не имеют количественного значения). ex:-заболевания A, заболевания B и заболевания C и т. д.
- Порядковая логистическая регрессия: она имеет дело с целевыми переменными с упорядоченными категориями. пример:- «плохо», «хорошо», «очень хорошо» и т. д.
Предположения логистической регрессии: -
Логистическая регрессия не делает никаких ключевых предположений линейной регрессии, таких как линейность, нормальность, гомоскедастичность и т. д.
Но следующие предположения по-прежнему применимы: -
- Бинарная логистическая регрессия требует, чтобы зависимые переменные были бинарными, в то время как порядковая логистическая регрессия требует, чтобы зависимые переменные были порядковыми.
- Наблюдения не должны основываться на повторных измерениях или согласованных данных.
- Он не требует мультиколлинеарности или требует небольшой мультиколлинеарности в независимых переменных, что означает, что независимые переменные не должны слишком сильно коррелировать друг с другом.
- Он предполагает линейность независимых переменных и логарифмических шансов.
- Логистическая регрессия обычно требует большого размера выборки.
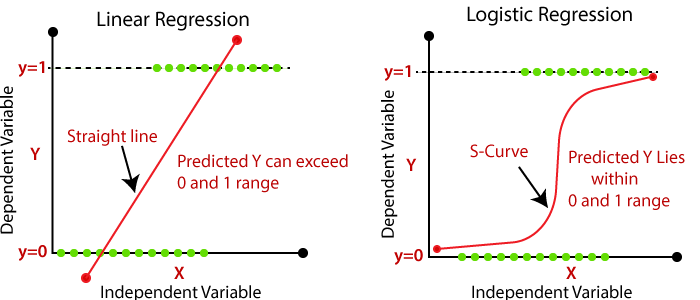
Причина, по которой линейная регрессия не подходит для задачи классификации: -
- В линейной регрессии прогнозируемое значение является непрерывным, они не являются вероятностными, как логистическая регрессия.
- Линейная регрессия чувствительна к выбросам или дисбалансу данных.
- Линейная регрессия может предсказать вероятность от отрицательной до положительной бесконечности, но вероятность может лежать только между 0 и 1. Для решения этой проблемы мы используем логит-функцию или логарифмическую функцию шансов. .
Отношение шансов и логит
Логит-функция отображает вероятности из диапазона (0,1) во весь диапазон действительных чисел (−∞,∞). Это написано как
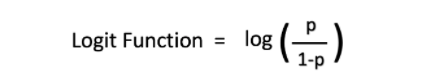

Здесь у нас есть L.H.S как логит-функция и R.H.S как шансы.
Обратная форма логит-функции также называется логистической функцией, и, как мы знаем, эта логистическая функция также называетсясигмоидальной функцией. из-за его характеристики S-образной кривой.

Это всегда дает вероятность от 0 до 1 в качестве результата.
Логистическая модель
Как и все другие регрессионные анализы, логистическая регрессия является прогностическим анализом.
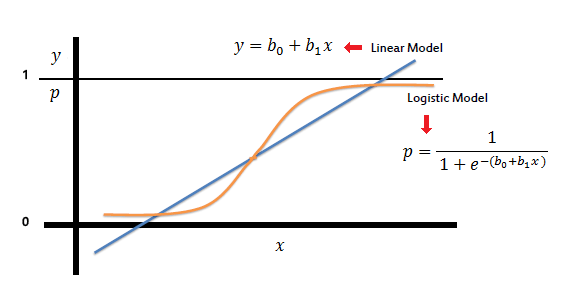
Логистическая регрессия использует сигмовидную функцию, которая ограничивает значение логистической регрессии между 0 и 1.
В логистической регрессии у нас есть пороговое значение, и значение логистической регрессии выше этого порогового значения считается равным 1, а ниже этого значения ниже этого порогового значения будет рассматриваться как 0.
Функция стоимости в логистической регрессии
Функция стоимости количественно определяет ошибку между прогнозируемым значением и ожидаемым значением. Это также помогает нам оценить производительность модели машинного обучения для данного набора данных.

Функция стоимости, используемая в логистической регрессии, называется Log Loss.
Оценка модели логистической регрессии
Ниже приведены несколько основных показателей, с помощью которых мы можем оценить эффективность логистической регрессии:
- Информационные критерии Акаике (AIC): -AIC – это мера соответствия, которая наказывает модель за количество коэффициентов модели. Поэтому всегда следует рассматривать модель с минимальным значением AIC.
- Матрица путаницы:Матрица путаницы показывает нам табличное представление фактического и прогнозируемого значения. Используя это, мы можем найти точность, и это также помогает нам избежать переобучения.
- Рабочая характеристика приемника (Кривая ROC): — чем выше площадь под кривой, тем лучше прогнозирующая способность модели.
Ссылки:-
- Википедия
- Аналитика Видья Блоги
- Несколько других источников