В этом анализе будут использоваться данные кредита для прогнозирования точности модели KNN, и мы будем использовать различные пределы соседей KNN от 1 до 10, чтобы проверить, для скольких соседей модель оптимальна. Модели KNN также очень просты в использовании и понимании, однако нам нужно настроить свойство соседа, и поэтому мы будем тестировать различные значения в диапазоне от 1 до 10, но, вообще говоря, значение от 3 до 5 работает хорошо, но мы следует проверить все значения в диапазоне от 1 до 10, что мы и будем делать в этой истории. В этом анализе мы будем использовать евклидово расстояние, однако его также можно изменить в параметрах при запуске анализа. Обучение модели происходит очень быстро, однако, если наш набор данных увеличится совсем немного, прогноз может занять много времени, и это верно для количества строк или количества признаков, когда они имеют большой размер. Это одна из моделей, которые имеют варианты использования регрессии и классификации, но из-за ее ограничений, как описано выше, она мало используется в производственных настройках, за исключением тестирования в качестве базового метода для первоначальной проверки прогнозов.
Сначала загружаем все библиотеки.
Загрузите наборы данных и посмотрите на заголовок

Затем мы подробно рассмотрим элементы данных

Посмотрите сводную статистику

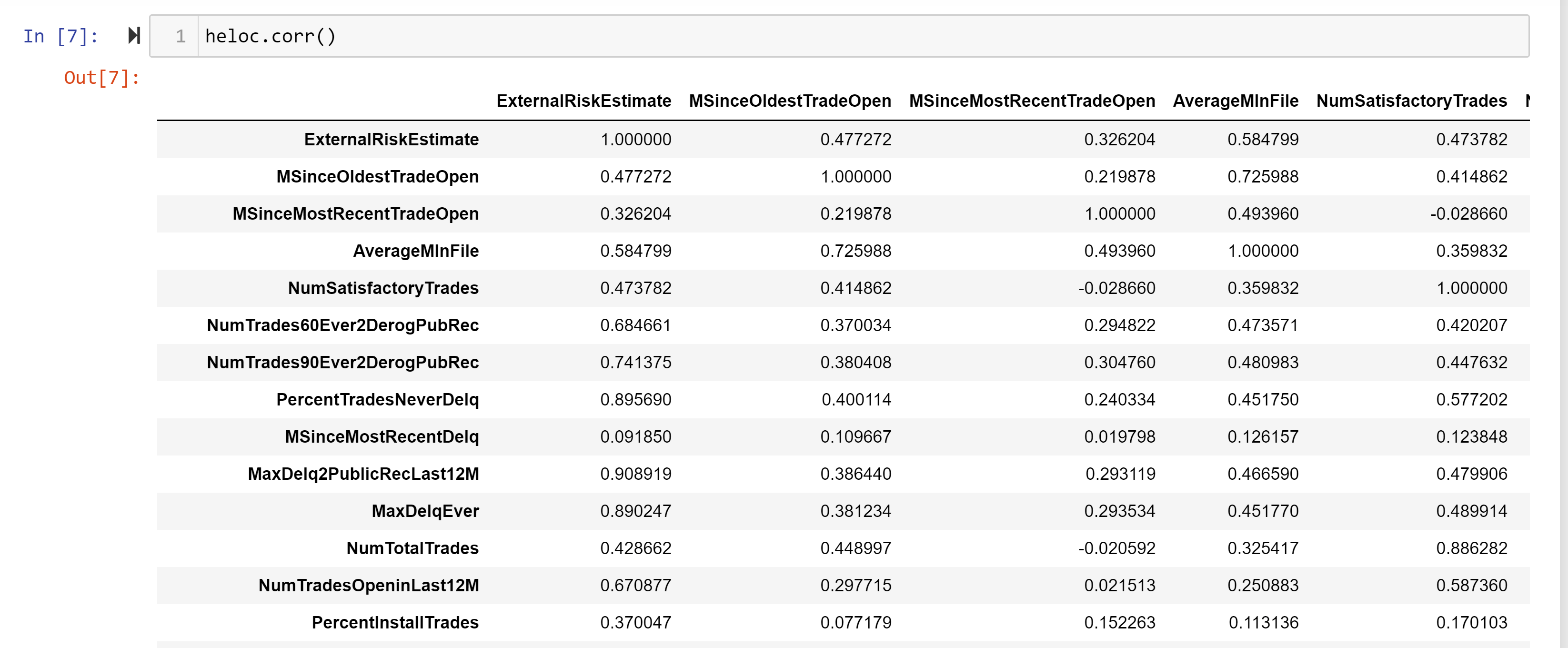
Корреляция различных признаков
Посмотрите на форму данных и разделите их между поездом и тестом.

Разделите данные и вызовите алгоритм KNN

Запустите алгоритм KNN на различном количестве соседей от 1 до 10.


Следовательно, как мы видим, наилучшая точность достигается, когда у нас есть 7 соседей, после этого точность обучения также начинает падать, а точность тестирования находится примерно на том же уровне.
Использованная литература: