Панды против Даска против Ваекса

Вы когда-нибудь задумывались, сколько данных наша планета может создавать каждый день?
Что ж, в 2020 году эта цифра составляла 2,5 квинтиллиона байт в день.
В квинтиллионе 18 нулей. Просто к вашему сведению.
Статистика роста объемов данных предоставила некоторые большие цифры. И они будут только больше. Как энтузиаст данных, наша цель - всегда выполнять какие-либо вычисления или обрабатывать их как можно быстрее. В сегодняшнем блоге мы сравним некоторые из лучших библиотек для загрузки и обработки больших наборов данных.
- Панды
- Даск
- Vaex
Примечание.
1. The dataset we are going to use in this blog post has been taken from NYC Taxi Record Data — Jan-2020. That can be downloaded from here. 2. The size of the CSV file is around 600MB. 3. The script I am running on the system has 16GB RAM.
Панды

В Python Pandas - самая популярная библиотека, используемая для инженерии данных. Даже каждый Pythonista в области Data Science использует его. Пока данные, с которыми мы работаем, достаточно малы (чтобы поместиться в ОЗУ), Pandas великолепен. Но часто в действительности нам приходится иметь дело с гораздо большими наборами данных, размером в несколько гигабайт или больше.

В таких случаях не стоит использовать панд. Потому что он на самом деле не создан для скорости. Pandas предназначен для работы только на одном ядре. Несмотря на то, что большинство наших машин имеют несколько ядер ЦП, pandas не может использовать доступные многоядерные ядра.
Проведем небольшой эксперимент. Аааааааааааааааааааааааааа ... быстро! Давайте посмотрим.
Загрузите набор данных с помощью Pandas:
import pandas as pd df = pd.read_csv(‘yellow_tripdata_2020–01.csv’) df.head()

%%time - волшебная команда. Это часть IPython. %%time печатает время стены для всей ячейки. Я использовал %%time, чтобы узнать, сколько времени требуется для загрузки файла, и, как и ожидалось, загрузка файла размером 600 МБ заняла около 10 секунд.
Создайте новую функцию с помощью Pandas:
Давайте сделаем шаг вперед и посмотрим, сколько времени потребуется, чтобы создать новый объект или столбец в наборе данных. В этом тестовом примере я умножу 2 столбца, чтобы создать новый.
df[‘new_column’] = df.PULocationID * df.DOLocationID
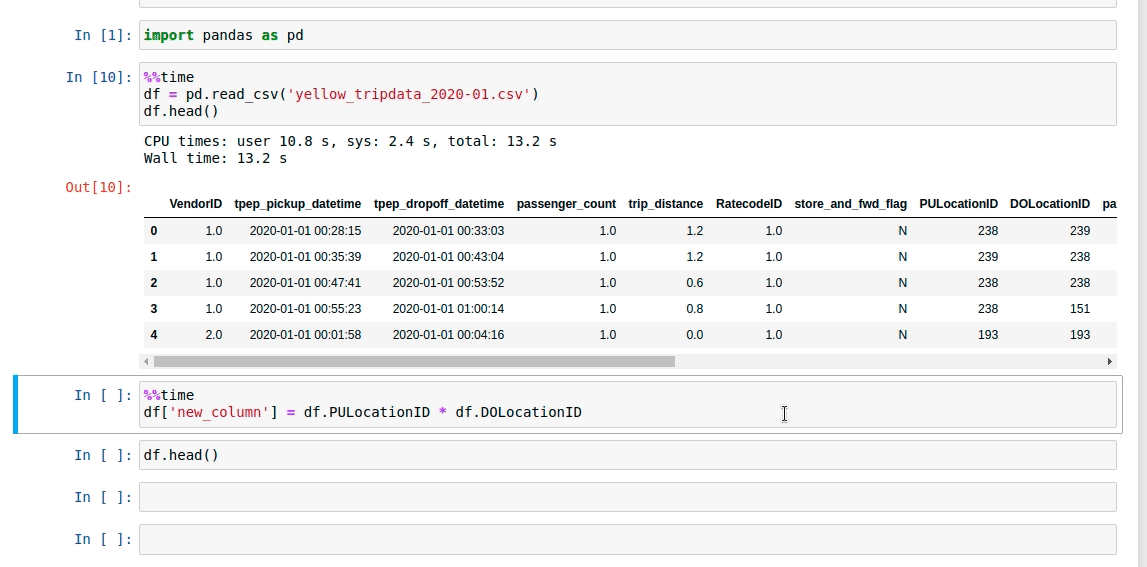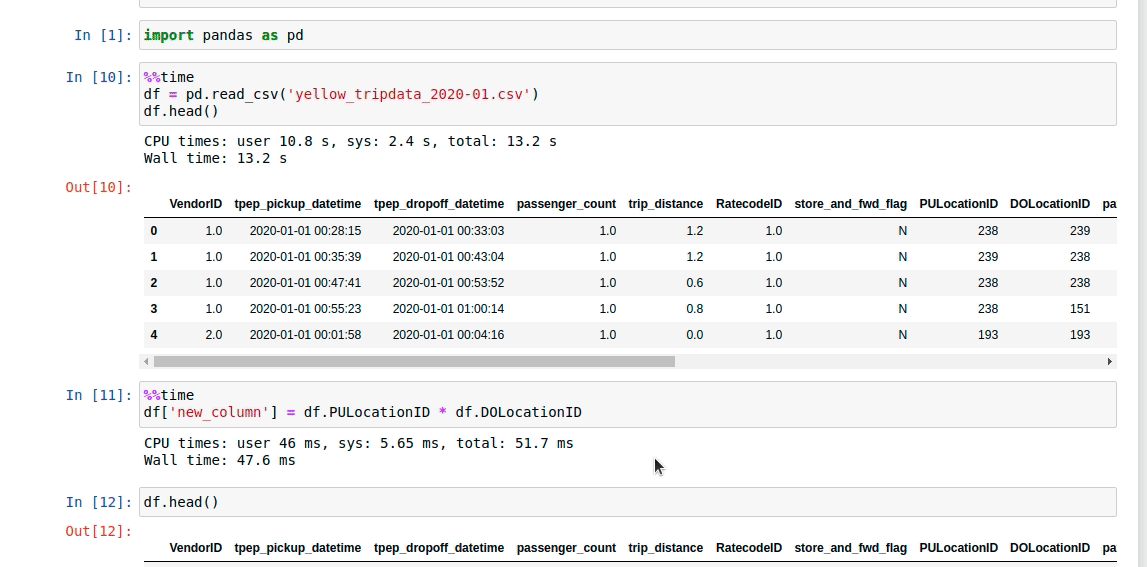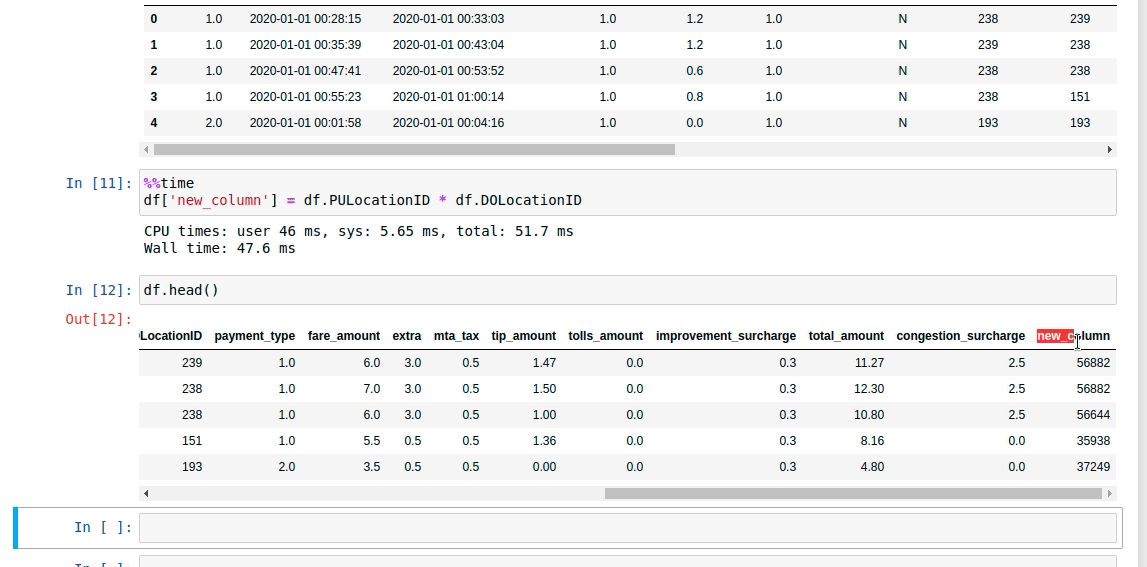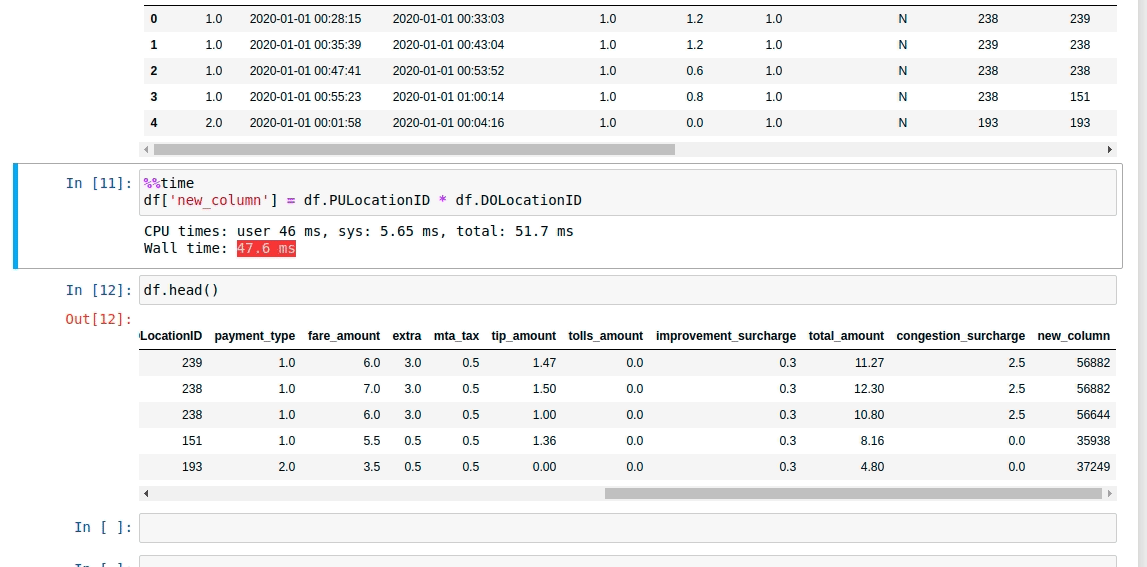
Отметим наши наблюдения из эксперимента, чтобы сравнить с Даском и Вэйксом. Это заняло около 47,6 миллисекунд.
Даск

Dask известен параллельными вычислениями на отдельных машинах за счет использования многоядерных процессоров и эффективной потоковой передачи данных с диска. Это один из самых сложных конкурентов Pandas. Параллельное программирование предлагает множество преимуществ, но оно также довольно сложно, независимо от того, используете ли вы потоки, ядра ЦП, графические процессоры или кластеры.

Параллельная обработка не всегда работает так аккуратно, как вы ожидаете. Иногда для выполнения тяжелых задач требуется больше аппаратных ресурсов.
Давайте проверим производительность с помощью Dask. Ядро Jupyter было перезапущено перед запуском команд Dask.
Загрузите набор данных с помощью Dask
import dask.dataframe as dd %%time dask_df = dd.read_csv(‘yellow_tripdata_2020–01.csv’) dask_df.head()

Как видите, с помощью параллельных вычислений можно выполнить ту же задачу за 1,37 секунды.
Давайте посмотрим, сколько времени уйдет на создание новой функции.
Создайте новую функцию с помощью Dask
%%time dask_df[‘new_column’] = dask_df.PULocationID * dask_df.DOLocationID

10.9 миллисекунд! Занял половину времени по сравнению с Pandas.
Vaex

Vaex - это высокопроизводительная библиотека Python для ленивых фреймов данных Out-of-Core, предназначенная для изучения больших наборов табличных данных. Он может вычислять базовую статистику для более чем миллиарда строк в секунду. Он поддерживает несколько визуализаций, позволяющих интерактивно исследовать большие данные. Vaex в значительной степени полагается на ленивую оценку и отображение памяти.
- ленивая оценка: не производить никаких вычислений, пока не будет уверенности в том, что результаты необходимы.
- отображение памяти: обработка файлов на жестких дисках так, как если бы они были загружены в оперативную память.
Vaex требует преобразования CSV в формат HDF5 (формат иерархических данных версии 5), что меня не беспокоит, так как вы можете сделать небольшой перерыв, вернуться, и данные будут преобразованы. Кроме того, вы можете передавать существующие данные прямо из S3.
Создание файлов Hdf5
import vaex vaex_df = vaex.from_csv(‘yellow_tripdata_2020–01.csv’, convert=True, chunk_size=5_000_000)
Теперь давайте повторим описанные выше операции, но с Vaex.
Загрузите набор данных с помощью Vaex

Ух ты! Ты это видел? Это заняло всего 16,9 миллисекунды.
Создайте новую функцию с помощью Vaex
Теперь посмотрим на результат нашей дальнейшей работы, т. Е. Создания новой функции,
%%time vaex_dff[‘new_column’] = vaex_dff.PULocationID * vaex_dff.DOLocationID
![]()
Vaex потребовалось всего 751 микросекунду для создания новой функции.
Полученные результаты
В таблице ниже показано время выполнения эксперимента Pandas vs Dask vs Vaex.

Победитель эксперимента очевиден. Vaex может обрабатывать большие наборы данных за доли миллисекунд, а Pandas и Dask - нет. Этот эксперимент специфичен, поскольку я тестирую производительность на небольшом наборе данных. Вы можете увидеть резкие изменения в результате, когда размер файла станет больше.
Спасибо за чтение!
Следуй за мной на Medium, чтобы быть в курсе последних обновлений. 😃