Эухенио Кулурсьелло, псевдоним Заиди и Винаяк Гохале
Пропускную способность памяти и повторное использование данных при вычислениях глубокой нейронной сети можно оценить с помощью нескольких простых симуляций и вычислений.
Вычисление глубокой нейронной сети требует использования данных веса и входных данных. Веса - это параметры нейронной сети, а входные данные (карты, активации) - это данные, которые вы хотите обрабатывать от одного слоя к другому.
В общем, если в вычислении повторно используются данные, потребуется меньшая пропускная способность памяти. Повторное использование может быть достигнуто:
- отправка большего количества входных данных для обработки с теми же весами
- отправка большего количества весов для обработки тех же входных данных
Если нет повторного использования входных или весовых данных, то пропускная способность максимальна для данного приложения. Приведем несколько примеров:
Линейные слои: здесь весовая матрица M на M используется для обработки вектора из M значений с битами b. Общий объем переданных данных: b (M + M²) или ~ bM²
Если линейный слой используется только для одного вектора, потребуется отправить всю матрицу весов M² по мере выполнения вычислений. Если ваша система имеет T операций в секунду производительности, то время для выполнения вычислений составляет bM² / T. Учитывая, что пропускная способность BW = общее количество переданных данных / время, в случае линейных слоев BW = T.
Это означает, что если ваша система имеет производительность 128 Гбит / с, вам потребуется пропускная способность более 128 ГБ / с для выполнения операции с полной эффективностью системы (при условии, конечно, что система может это сделать!).
Конечно, если у вас есть несколько входов для одного и того же линейного слоя (несколько векторов, которые необходимо умножить на одну и ту же матрицу), тогда: BW = T / B, где B - количество векторов или пакета.
Свертки: для операции свертки требования к полосе пропускания обычно ниже, поскольку данные входной карты могут использоваться в нескольких параллельных операциях свертки, а веса свертки относительно малы.
Например: для карты 13 x 13 пикселей в операции свертки 3x3 от 192 входных карт до 192 выходных карт (как, например, в слое Alexnet 3) требуется: ~ 4 МБ данных веса и ~ 0,1 МБ входных данных из памяти. Для этого может потребоваться около 3,2 ГБ / с для системы со скоростью 128 Гбит / с с эффективностью ~ 99% (версия SnowFlake Spring 2017). Низкое использование полосы пропускания связано с тем, что одни и те же входные данные используются для вычисления 192 выходных данных, хотя и с разными матрицами малых весов.
RNN: пропускная способность памяти для рекуррентных нейронных сетей - одна из самых высоких. В системе Deep Speech 2 или аналогичной используется 4 слоя RNN размером 400 (см. Здесь и здесь). Каждый уровень использует эквивалент 3-х линейно-слоистых матричных умножений в модели ГРУ. Во время логического вывода входной пакет составляет только 1 или небольшое количество, и, таким образом, для работы этой нейронной сети требуется наибольшая пропускная способность памяти, настолько высокая, что обычно невозможно полностью использовать даже эффективное оборудование при полном использовании.
Чтобы наглядно представить эти концепции, обратитесь к этому рисунку:
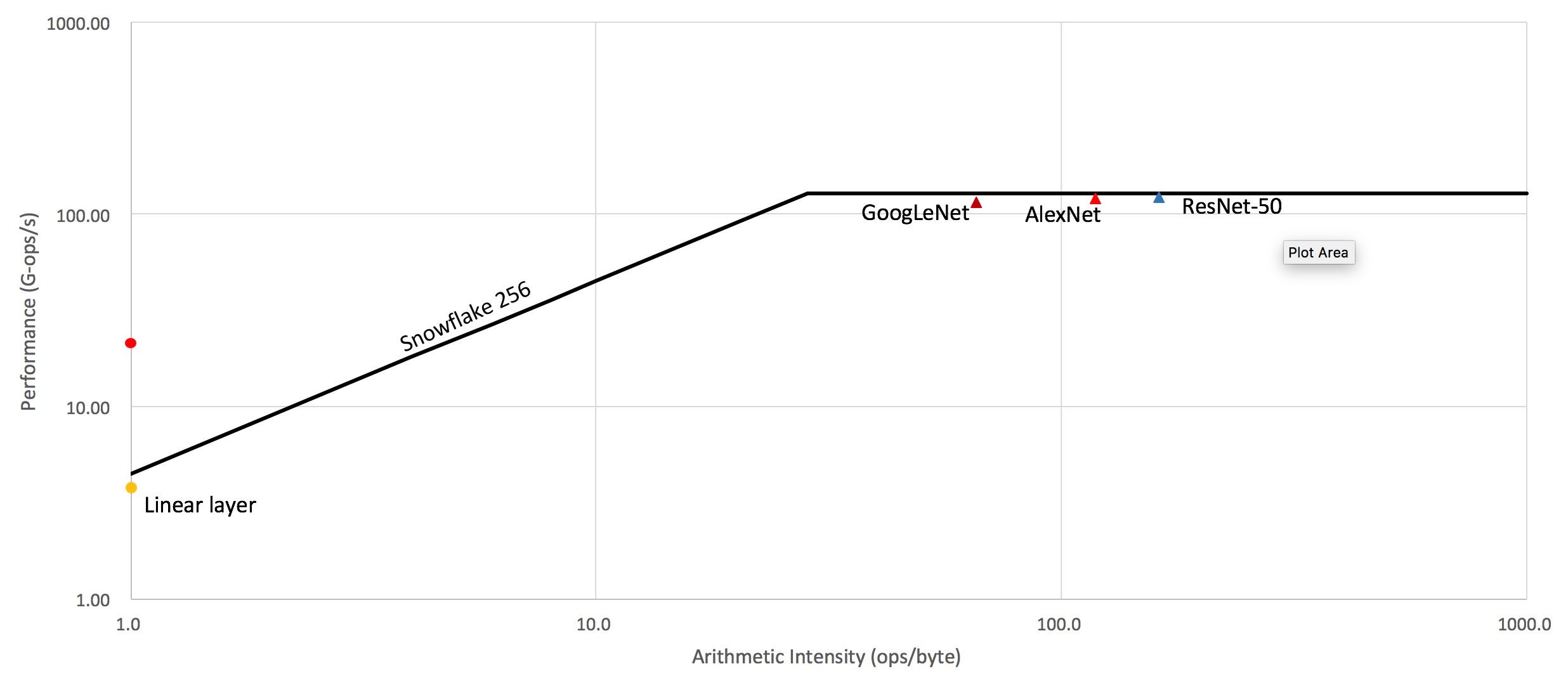
Это арифметическая интенсивность для нашего ускорителя Snowflake. Арифметическая интенсивность - это количество операций, выполненных с байтом данных. Как видите, все протестированные модели нейронных сетей работают с максимальной эффективностью устройства. С другой стороны, линейные слои имеют очень мало повторного использования данных и ограничены пропускной способностью памяти.
PS .: Подробнее о производительности, графиках крыш и пропускной способности здесь.
Об авторе
У меня почти 20-летний опыт работы с нейронными сетями как в аппаратном, так и в программном обеспечении (редкое сочетание). См. Обо мне здесь: Medium, webpage, Scholar, LinkedIn и т. Д.