Как защитить систему от условий гонки? Когда используется сложный кеш? Когда требуется глобальное состояние? Мы можем покрыть нашу систему тестами, надеяться, что мы рассмотрели все возможные крайние случаи, и молиться, чтобы в производственной среде не происходило ничего нового.
Или мы могли бы использовать формальные методы.
Мы могли бы написать абстрактный дизайн на языке спецификаций с возможностью машинной проверки, определить свойства, которые мы хотим получить от дизайна, и доказать, что он соответствует нашим требованиям. В некоторых случаях может потребоваться фактическое математическое доказательство, но гораздо удобнее предоставить проекту ряд входных данных и исчерпывающе изучить все состояния и временные рамки на предмет каких-либо признаков ошибки. Это не идеально, но почти все согласны с тем, что это чертовски эффективно… в теории. На практике люди говорят, что его слишком сложно использовать для чего-то менее важного, чем МРТ или космический корабль. Никто не приводит реальных примеров того, как это использовал средний стартап.
Итак, давайте приведем пример того, как это использовал средний стартап.
Фон
С 2012 года eSpark предлагает ученикам начальной школы индивидуальное обучение с помощью iPad. Мы проводим студентам краткую викторину, определяем их сильные и слабые стороны и даем им урок, который поможет им стать лучше. В основе этого - огромный список кураторских приложений для iPad, исследованных и отобранных внутренней командой бывших учителей, которые мы добавляем к каждому уроку. Это эффективный продукт, и я горжусь тем, что являюсь его частью.

Приложения, хотя и имеют решающее значение для эффективности продукта, также являются наиболее сложным компонентом. Каждому ученику нужен свой набор приложений, который меняется по мере прохождения уроков. Мы должны иметь возможность отслеживать и корректировать их почти в реальном времени, чтобы учащиеся не остались без следующего урока. В крайнем случае студенту может понадобиться шесть приложений утром и шесть совершенно разных приложений днем. Мы также должны учитывать школьный бюджет, поэтому у нас есть ограниченное количество платных приложений, которые мы можем перемещать между учениками. Наконец, поскольку нам нужно делать это в масштабе, вся система должна работать автоматически, без вмешательства учителя или администратора.
Помимо всего этого, есть еще одна проблема: менеджеры мобильных устройств. Эти системы контролируют все iPad в школе. Если мы хотим добавить приложения, удалить приложения или даже получить список установленных приложений, мы должны просмотреть их. MDM предоставляются третьими сторонами, каждая со своим собственным API, потоком управления и особенностями. Они также могут быть размещены в самих школах, а это значит, что нам также придется решать проблемы производительности и стабильности.

Эта проблема
Один из наших партнеров по MDM определяет, какие приложения переходят на какие устройства, используя области приложения, позволяя администраторам создавать обязательные конфигурации, такие как «это приложение должно быть на этих устройствах». Чтобы определить, какие приложения необходимо установить, мы должны проверить данные устройства. Задержка между входом устройства в область действия приложения и получением приложения может заставить нас поверить в то, что на устройстве отсутствует приложение, когда оно уже было в области действия. В этом случае мы потенциально попытаемся снова добавить его в область видимости.
Партнер попросил, чтобы мы 1) отправили как можно меньше корректировок области (массовое добавление и удаление устройств из области приложения) и 2) не вносили никаких избыточных изменений в массовую команду. Другими словами, если бы мы попросили добавить «Bluster» к пяти устройствам, ни одно из этих пяти не могло бы уже быть в области действия Bluster.
Да, также: взаимодействие с MDM требует ввода-вывода, поэтому все вызовы API - обновление области приложения, получение данных устройства и т. Д. - должны выполняться асинхронно в независимом процессе. Синхронизация устройств происходит с разной скоростью, поэтому нам нужно поддерживать работающий пул устройств для каждого приложения. И для демонстрации продаж необходимо ручное изменение. И эта система напрямую повлияет на доход более двух миллионов долларов. Это не та система, которую мы можем просто исправить в производственной среде.
Поэтому мы решили использовать формальные методы.
Наш любимый инструмент - TLA +. Во-первых, мы определяем систему как гигантский абстрактный конечный автомат и перечисляем все возможные переходы, которые она может сделать. Затем мы указываем инварианты системы, свойства, которые должно иметь каждое состояние. Наконец, мы запускаем программу проверки модели под названием TLC в спецификации. TLC исчерпывающе проверяет все возможные состояния и выдает ошибку, если какое-либо состояние нарушает инвариант. Вот наш первоначальный дизайн:
Он должен выглядеть в основном знакомым как язык программирования, но есть несколько тонких отличий. Во-первых, AppScope \in [Devices -> {0, 1}] сообщает TLC, что любое количество устройств уже может быть в области действия как часть начального состояния. Ожидания реального мира редко начинаются с чистого листа: возможно, школа предварительно загрузила некоторые приложения на устройства, или мы можем выполнить более поздний пакетный цикл. По причинам, которые станут очевидными, мы представляем это как «каждое устройство попадает в область действия либо 0 раз, либо 1 раз». Мы также могли бы использовать [Devices -> BOOLEAN], где BOOLEAN - это набор {TRUE, FALSE}.
Во-вторых, существует один процесс TimeLoop (представляющий периодические установки) и один процесс SyncDevice для каждого устройства. В каком порядке они будут работать? Для каждого начального состояния существует несколько вариантов поведения или временных шкал. TLC может выбирать, в каком порядке запускать процессы, как они чередуются во время работы, и даже если они могут привести к сбою в середине процесса. Sync(d1) -> Sync(d2) -> Add -> Clean так же действителен, как и Sync(d2) -> Add -> Sync(d1) -> Clean, и TLC проверит и то, и другое.
Наконец, Devices - это константа. Помимо того, что мы не можем изменить его во время выполнения, у констант есть дополнительное свойство в TLA +: мы можем определить их значение прямо перед запуском проверки модели. Чтобы проверить это на одном устройстве, мы объявляем Устройства набором {d1}. Если бы мы хотели протестировать с тремя устройствами, мы могли бы так же легко написать {d1, d2, d3}. Это позволяет нам сделать нашу модель настолько большой и сложной, насколько это необходимо для проверки наших инвариантов.
В остальном спецификация довольно проста. SyncDevice может добавить устройство в пакетный пул. В какой-то момент TimeLoop запускается, устройства из пула пакетов добавляются в AppScope, а затем пул пакетов очищается.
Доказательство безопасности
Инварианты - это утверждения, которые всегда должны выполняться в каждом состоянии системы. Когда мы проверяем безопасность, мы проверяем, что невозможно достичь состояния, в котором нарушается какой-либо инвариант. В нашем случае мы можем представить наш инвариант следующим образом:
\A d \in Devices:
AppScope[d] \in {0, 1}«Для всех устройств это должно быть 0 раз или 1 раз». Если область видимости была увеличена 2 раза, мы добавили устройство, которое уже находилось в области видимости. Когда мы тестируем это на одном устройстве, мы получаем ожидаемую ошибку:
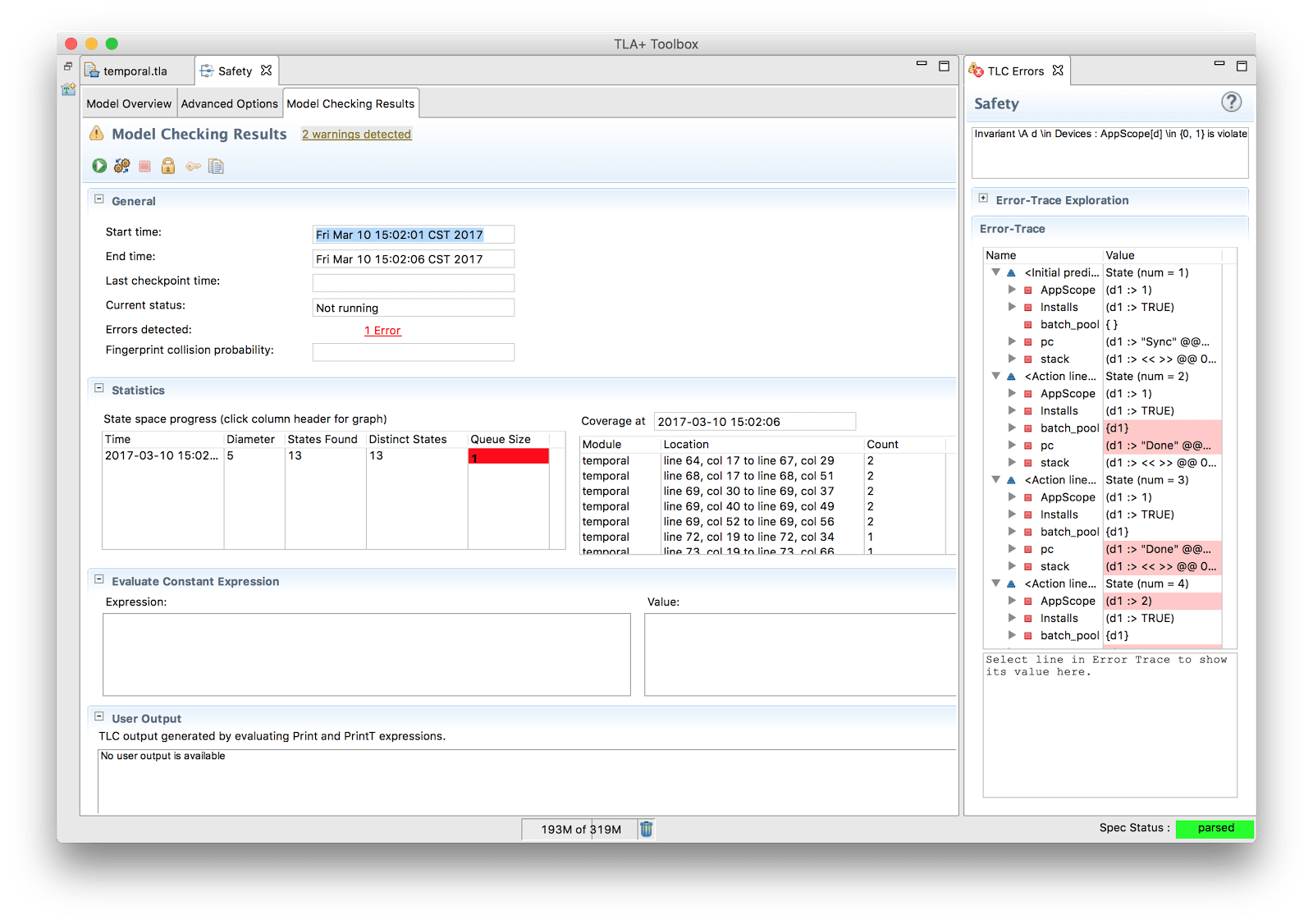

У нас нет никакой логики для обнаружения устройств, которые уже находятся в зоне действия. Простое исправление - вытащить область видимости, а затем удалить все, что уже находится в области видимости, из пула. Если мы это сделаем, это сработает.
Filter:
batch_pool := batch_pool \intersect {d \in Devices: AppScope[d] = 0};А как насчет двух устройств? Это будет сложно проверить с помощью модульных тестов. Но с TLA + это тривиально. Мы просто добавляем в модель второе устройство и наблюдаем, как оно выходит из строя.
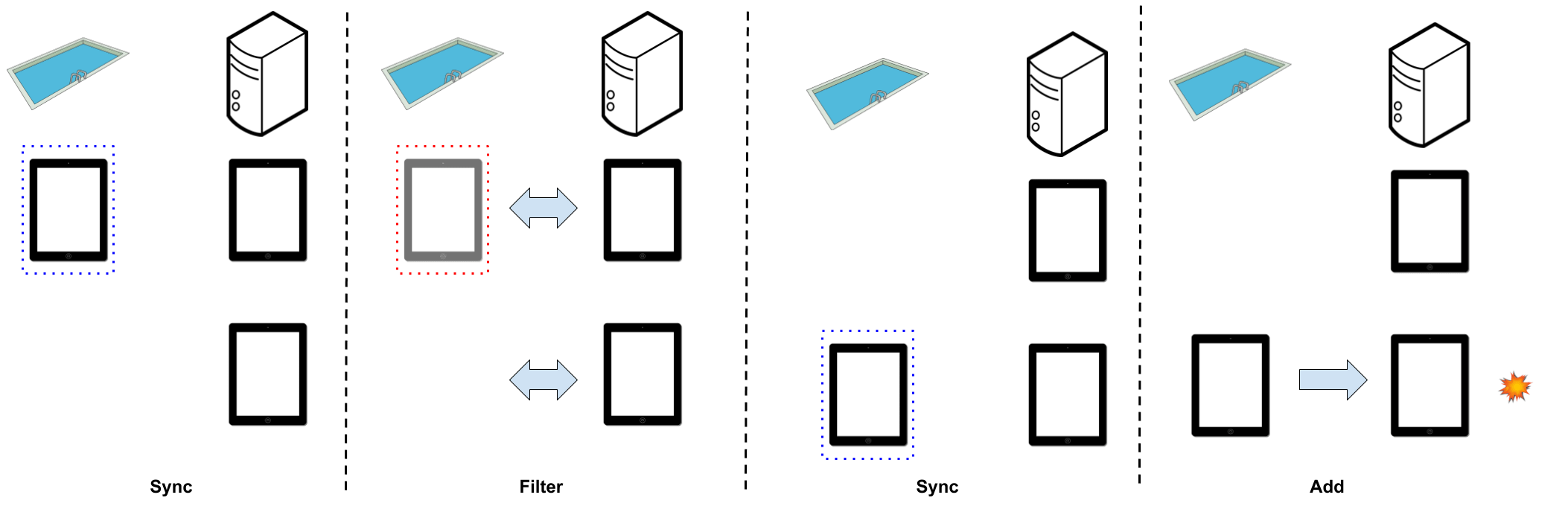
Этот сбой связан с состоянием гонки. Одно устройство синхронизируется, а это значит, что мы можем начать установку. Как только мы фильтруем пул, другое устройство синхронизируется, возвращая его обратно в пул к этапу добавления. В итоге мы исправили это, кэшировав пул во время процесса установки, а также отфильтровав и отправив кеш. Таким образом, даже если пул обновляется после запуска процесса, мы не используем новые данные в нашем вызове.
procedure ChangeAppScope()
variables cache;
begin
Cache:
cache := batch_pool;
Filter:
cache := cache \intersect {d \in Devices: AppScope[d] = 0};
Add:
AppScope := [d \in Devices |->
IF d \in cache THEN AppScope[d] + 1
ELSE AppScope[d]
];
Clean:
batch_pool := {};
return;
end procedureПоддержание безопасности
Эта система неполная: одни приложения важнее других, а некоторые приложения нужны большему количеству людей, чем другие. Лучшим компромиссом для этого является добавление «пороговых значений пула» . Если в результате синхронизации устройства размер пула превышает пороговое значение, мы должны немедленно начать процесс установки. Это означает, что если 30 ученикам понадобится одно и то же приложение, они получат его в течение следующих нескольких минут, а не всякий раз, когда закончится период TimeLoop.
Мы можем указать это с помощью оператора either. Всякий раз, когда TLC попадает в оператор, он создает отдельную временную шкалу для каждой ветви. Опять же, нас не волнует, как мы запускаем пороговую синхронизацию, просто это может произойти.
if PoolNotEmpty then
either call ChangeAppScope();
or skip;
end either;
end if;Однако когда мы добавляем это, TLC обнаруживает новую ошибку в системе.
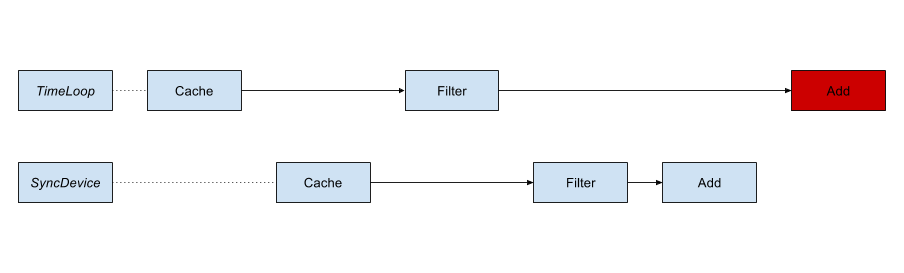
Наша система была построена на предположении, что одновременно может выполняться только один процесс установки. Когда два могут работать, они потенциально могут создать одинаковый пороговый кеш. Затем оба фильтруют кеш одновременно, оставляя оба устанавливающих одно и то же устройство, потому что оно не входит в область действия. В первом случае все будет нормально, но во втором процессе мы выполним двойную установку.
Есть несколько способов исправить это, но самым простым для нас было установить мьютекс в процессе установки. В то время как несколько источников могут запускать процесс, только один может работать в данный момент, что устранило ошибку для нас.
variables lock = FALSE;
\* ...
GetLock:
await ~lock;
lock := TRUE;
\* ...
Clean:
lock := FALSE;
Доказательство живучести
Пока что мы доказали, что система не делает плохих вещей. Однако мы еще не доказали, что он делает то, что мы хотим. В частности, мы хотим убедиться, что если мы хотим установить приложение на устройство, оно в конечном итоге окажется в области действия приложения. Безопасность - это доказательство того, что плохого не бывает. Живучесть - это доказательство того, что все хорошее случается. Вот как выглядит наше свойство liveness:
\A d \in Devices: Installs[d] ~> AppScope[d] = 1
Это просто говорит о том, что если мы захотим установить его на устройство, в какой-то момент в будущем это действительно будет. И снова TLC обнаруживает ошибку.

Мы хотим установить приложение на два устройства. Первое устройство синхронизируется и запускает процесс установки. После кэширования пула синхронизируется второе устройство. Затем, после завершения процесса, мы очищаем пул, включая второе устройство. Исправить это довольно просто: вместо того, чтобы очищать весь пул, просто удалите из него кэшированные устройства. Это означает, что весь процесс установки изолирован от внешнего мира и работает так, как мы ожидаем.
Clean:
batch_pool := batch_pool \ cache;
lock := FALSE;Вы можете увидеть полную спецификацию здесь.
Полученные результаты
Огромный успех. Мы закончили работу над системой на неделю раньше запланированного срока, и, хотя мы действительно обнаружили некоторые ошибки, все они были проблемами реализации, которые мы легко отследили. Тем не менее, с TLA + мы действительно столкнулись с несколькими болевыми точками:
- С этим очень легко стать излишне самоуверенным. Как уже упоминалось, у нас были некоторые ошибки в производстве. Одно было узким местом в производительности, которое нам нужно было исправить. Другой возник из-за требования, которое мы забыли смоделировать.
- TLA + медленный. Поскольку он осуществляет исчерпывающий поиск в пространстве состояний, очень легко увеличить время выполнения до часов или дней. После некоторой оптимизации мы получили наши спецификации меньше минуты каждая, но это потребовало определенных усилий.
- У TLA + высокая кривая обучения. Сама концепция формальных методов является новой для многих людей, плюс сам язык имеет свои недостатки и подводные камни.
Если вы заинтересованы в использовании TLA +, лучше всего начать с моего Руководства для начинающих по изучению TLA +, в котором есть упражнения, примеры из реальной жизни и практические советы. Это не связано с eSpark и является исключительно личным делом любви.
Мы хотели проверить, пригодны ли формальные методы для решения практических задач, и ответ был абсолютно. Два дня моделирования TLA + с лихвой окупились, так как мы создали более сложную систему быстрее и с меньшим количеством ошибок. Чтобы научиться, нужно время, но награда того стоит.
В eSpark Learning мы создаем инструменты следующего поколения, которые помогут учащимся добиться успеха в школе и в жизни. Мы верим в смирение, сострадание и баланс между работой и личной жизнью. Мы нанимаем!
Хиллел - старший инженер-программист в eSpark Learning. Он интересуется тестированием программного обеспечения, гражданскими технологиями и вообще противником. Найдите его в Твиттере под именем @hillelogram или на hillelwayne.com.