Учебник о том, как собирать данные с веб-сайта с помощью Python и Google Colaboratory.
В этой статье я буду использовать веб-сайт Springeropen.com в качестве примера. Здесь я не буду устанавливать какое-либо приложение, потому что в этом руководстве будет использоваться облачный сервис Google Colaboratory, к которому мы можем получить доступ по адресу http://colab.research.google.com/.

Что такое SpringerOpen?
Прежде чем идти дальше, давайте сначала узнаем, что такое SpringerOpen. SpringerOpen — это портфель журналов и книг Springer с полностью открытым доступом, охватывающий все области науки. Весь контент, опубликованный с помощью SpringerOpen, становится бесплатным онлайн сразу после публикации. SpringerOpen считает, что открытый доступ к исследованиям необходим для обеспечения быстрой и эффективной передачи результатов исследований. (Источник: https://www.springeropen.com/about/what-is-springeropen)

Процесс
Сначала мне нужно открыть веб-сайт Google Colab, а затем импортировать все необходимые библиотеки.

В этом уроке я буду использовать некоторые библиотеки: BeautifulSoup, Requests, OS и Pandas. Библиотека, которая служит для парсинга данных со страницы сайта — BeautifulSoup, чтобы узнать больше об этой библиотеке, вы можете посмотреть по следующей ссылке.
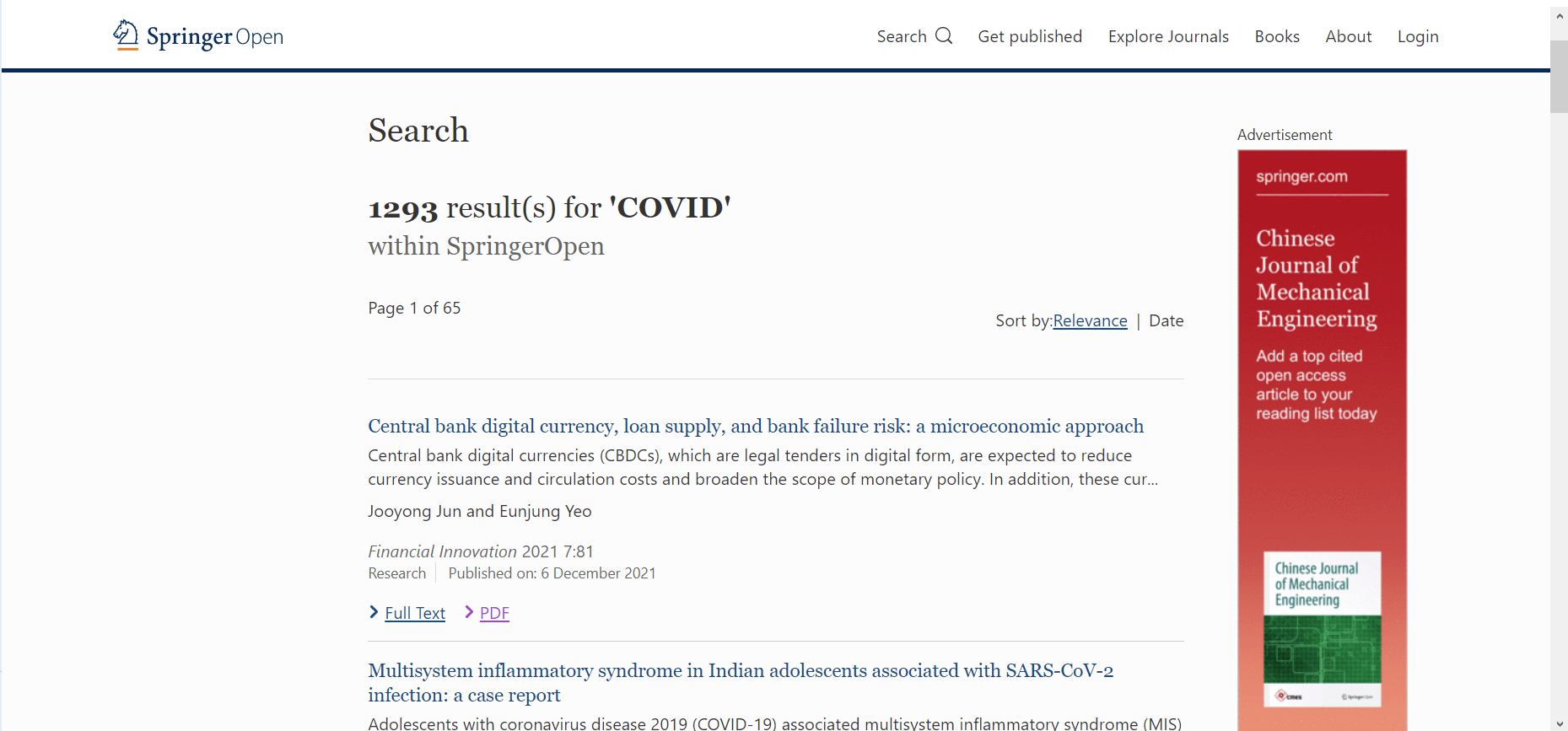
Затем я попытался найти журнал, используя Covid в качестве ключевого слова в https://www.springeropen.com/search?searchType=publisherSearch&sort=PubDate&page=1&query=COVID. Если я нажму CTRL + U, то я смогу увидеть исходный код этой страницы вот так.

Я буду собирать данные на основе исходного кода HTML, используя следующий код Python.
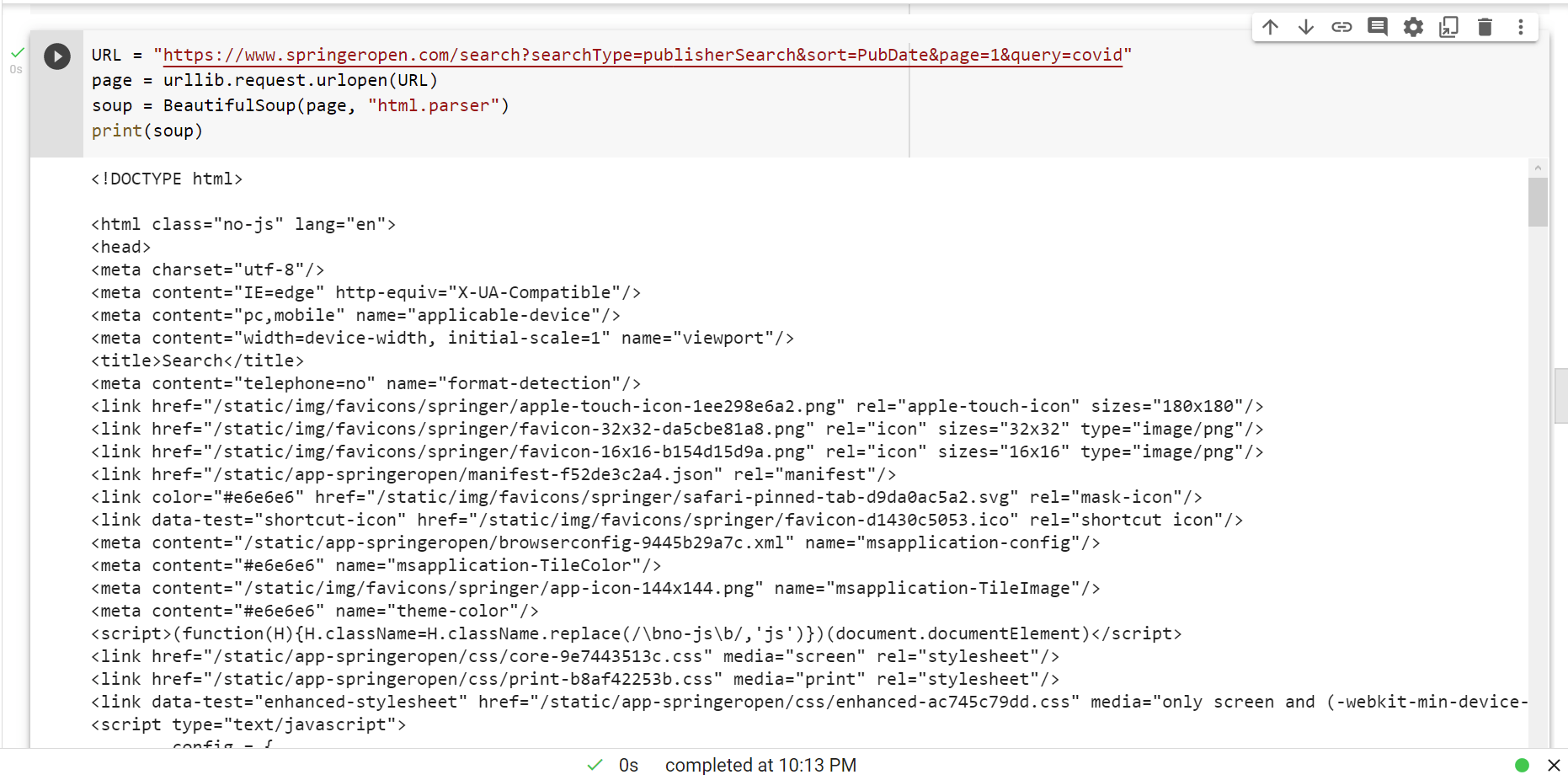
Это изображение является примером кода и результатов. Перед получением данных я должен подготовить три списка, которые будут получать результаты очистки данных с веб-сайта, а именно listTitle, listAuthor и listDocument.

В дополнение к получению данных заголовков и ссылок мне приходится использовать теги ‹a› в качестве помощника, существующего в HTML-коде. Я использую следующий код:

А для получения данных об авторе я буду использовать теги ‹p› в качестве помощника, который существует в HTML-коде. Я использую следующий код:

После результат можно увидеть с помощью следующего кода:

В приведенном выше коде показаны первые 5 строк данных результатов очистки данных журнала с использованием ключевых слов covid, полученных с Springeropen.com. Что делать, если я хочу использовать другое ключевое слово? Давайте внесем небольшое изменение, чтобы сделать код таким:

И теперь я могу использовать его, например, если я хочу найти журнал, связанный с "интеллектуальным анализом данных", тогда мне нужно ввести scrapJournal (“data mining”) и ВОИЛЯ!, я получу информацию о журнале вместе со ссылками, которые предоставляют мне прямой доступ к документу PDF бесплатным и законным способом.

Полный код
def scrapJournal(theKeyword):
keyword = theKeyword.replace(' ','%20')
URL = "https://www.springeropen.com/search?searchType=publisherSearch&sort=PubDate&page=1&query="+keyword
page = urllib.request.urlopen(URL)
soup = BeautifulSoup(page, "html.parser")
listTitle = []
listAuthor = []
listDocument = []
for link in soup.findAll('a'):
if "data-test=" in str(link) and "title-link" in str(link) and " href=" in str(link):
theTitle = link.string
listTitle.append(theTitle)
if "data-track=\"click\"" in str(link) and "pdf" in str(link):
link = link.get('href')
link = link.replace("""//""","")
listDocument.append("""https://"""+link)
for link in soup.findAll('p'):
if "-listing__authors" in str(link):
theAuthor = str(link).replace("</p>","")
theAuthor = theAuthor.split("</span>")[1]
listAuthor.append(theAuthor)
data = {'Title': listTitle,
'Author': listAuthor,
'DocumentLink': listDocument}
df = pd.DataFrame(data)
return df.head()
scrapJournal('data mining')
Заключение
Мы можем использовать библиотеку BeautifulSoup для сбора данных с веб-сайта. Преимущество этого метода в том, что нет необходимости устанавливать какие-либо инструменты, поскольку все вышеперечисленные шаги можно выполнить в облаке с помощью Google Colaboratory. Это все от меня, надеюсь будет полезно. Спасибо!
Больше контента на plainenglish.io. Подпишитесь на нашу бесплатную еженедельную рассылку здесь.