
Расходы на основе личности
Команда: Охюн Квон, Яш Уорти, Шон Калиш, Джейкоб Раймс, Эмили Маккалоу
Абстрактный
Этот анализ направлен на то, чтобы предоставить обзор многочисленных моделей и их соответствующую точность при прогнозировании склонности человека тратить деньги на внешний вид. Следующее призвано помочь брендам в творческой сегментации клиентов на основе личностных качеств и в определении наиболее полезных моделей для будущих проектов сегментации.
Введение
В условиях все более конкурентной маркетинговой среды бренды нуждаются в креативной и дифференцированной сегментации клиентов. Кроме того, социальные сети и все более ограничительные стандарты красоты (среди прочего) увеличили размер рынка косметических брендов с постоянной скоростью 5% в год. В рамках этого проекта мы стремимся определить, могут ли эти бренды использовать личностные качества для лучшего сегментирования и таргетинга клиентов потенциально новыми и все более эффективными способами.
Для этого мы выполнили пять шагов предварительной обработки, что особенно заметно сократило количество переменных ответа с пяти до трех. Затем мы запустили регрессию Лассо и определили переменные, наиболее коррелирующие с расходами на внешний вид.
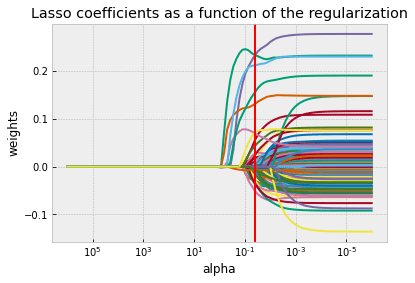
Эти результаты (корреляция и лассо) помогли нам выбрать наиболее важные признаки, которые мы использовали для уменьшения размерности этой проблемы. Мы решили значительно уменьшить нашу размерность, потому что точность наших прогнозов была неизменно низкой при 150+ независимых переменных. Наконец, было запущено девять моделей, чтобы определить лучшую и наиболее точную модель для креативной сегментации клиентов.
Обзор набора данных
Наш набор данных взят из Kaggle. Он был составлен на основе опроса 1010 студентов-статистиков в Словакии, проведенного в 2013 году. Каждый студент в возрасте от 15 до 30 лет ответил на 150 вопросов в электронной или письменной форме. Вопросы охватывали широкий спектр личных характеристик и состояли из запросов, касающихся музыкальных предпочтений (19 вопросов), предпочтений в кино (12 вопросов), хобби и интересов (32 вопроса), фобий (10 вопросов), привычек в отношении здоровья (3 вопроса). Черты личности, взгляды на жизнь и мнения (57 вопросов), привычки к расходам (7 вопросов) и демографические данные (10 вопросов). Наши респонденты ответили на каждый вопрос по шкале самооценки от 1 до 5.
Предварительная обработка данных
Поскольку это был добровольный опрос, полученные нами необработанные ответы содержали несколько отсутствующих значений. Прежде чем данные можно было использовать, мы должны были обеспечить согласованность и удобство использования всего набора данных. Для этого мы использовали вменитель KNN, который заполнил отсутствующие числовые значения, поскольку это повысило бы надежность нашего анализа. Наш набор данных также содержит 11 категориальных столбцов, которые мы намеревались использовать для нашего анализа. Мы использовали One Hot Encoder для категориальных данных, чтобы затем использовать полученные подмножества для анализа.
При первоначальном запуске моделей мы получили чрезвычайно низкую точность обучения и тестирования. Для дальнейшего изучения этой аномалии мы решили визуализировать распределение ответов в наших данных. Используя Seaborn и связанные с ним функции построения графиков, мы построили распределение ответов. Пример графика между расходами на развлечения и расходами на внешний вид показан ниже на рисунке 0:
Рисунок 0
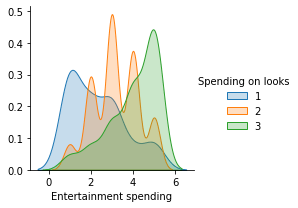
Как видно из вышеприведенной модели, ответы в одинаковых промежуточных категориях (2, 3, 4) частично совпадают, поскольку люди могут по-разному отвечать на разные вопросы по одной и той же теме. Проще говоря, средние ответы имеют тенденцию смешиваться, когда люди отвечают на опросы. По мнению респондентов, 1 и 5 очень разные, высокие и низкие показатели, но 2, 3 и 4 представляют схожие настроения. Такое смешение ответов приводит к снижению точности модели. Чтобы решить эту проблему, мы решили уменьшить количество сегментов (классов) до 3 с исходных 5. Самые высокие и самые низкие оценки были закодированы как категории 3 и 1 соответственно, однако промежуточные ответы (2,3 и 4) были закодированы как категории 3 и 1 соответственно. кодируются вместе в одном классе 2.
Очистив наши данные и успешно сократив классы, мы повторно запустили модели и на этот раз получили значительно более высокую точность. Наконец, чтобы устранить мультиколлинеарность между переменными, мы обнаружили самые сильные корреляции и подмножили набор данных, чтобы использовать для нашего анализа только 10 лучших и 10 самых низких коррелированных переменных.
Исследовательский анализ данных
После полной предварительной обработки нашего набора данных мы начали работу над нашим EDA.
Во-первых, мы исследовали демографические характеристики, такие как возраст, уровень образования, пол, религиозность и алкоголизм. Эти графики EDA показаны ниже:
Рисунок 1
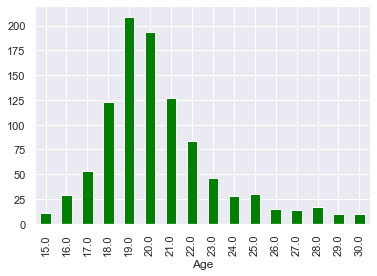
Возрастная переменная нашего набора данных колеблется от 15 до 30 лет и имеет приблизительно нормальное распределение с очень незначительным отклонением вправо. Дата-центры в возрасте от 19 до 20 лет.
Рисунок 2
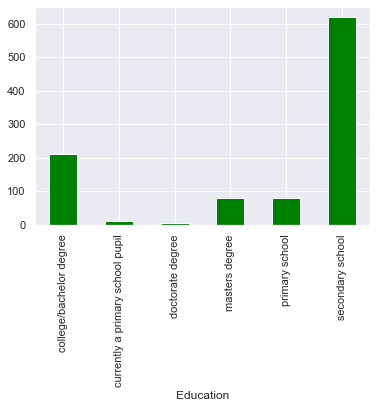
Уровень образования в нашем наборе данных варьируется от текущего ученика начальной школы (около 5–13 лет) до выпускника докторской степени. Эти данные в подавляющем большинстве относятся к учащимся средней школы (около 12–18 лет), а также к некоторым учащимся со степенью бакалавра, магистра и начальной школы.
Рисунок 3
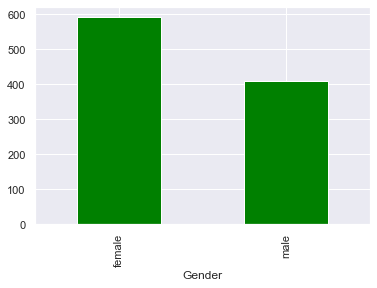
В нашем наборе данных около 60% женщин и около 40% мужчин.
Рисунок 4
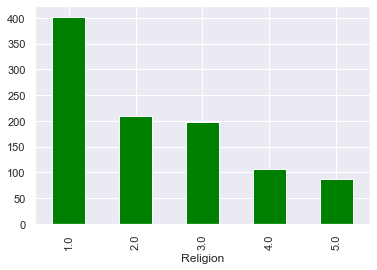
Функция религиозности нашего набора данных показывает, что большинство наших респондентов нерелигиозны.
Рисунок 5
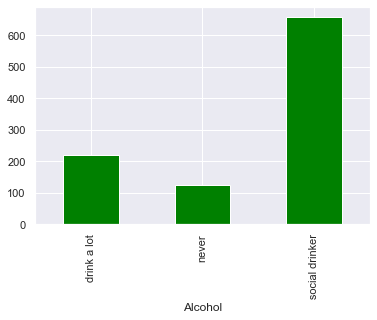
Наш набор данных показывает, что большинство наших респондентов пьют в социальных сетях, и две небольшие, но значимые порции пьют много и никогда не пьют.
Обозначив основные демографические характеристики, мы продолжили работу с EDA для нашей переменной ответа «Расходы на внешний вид». Мы сгруппировали расходы на внешний вид по многочисленным переменным и попытались найти значимые корреляции. Эта часть нашего EDA предназначена не для получения результатов, а для информирования будущих моделей нашего исследования и предоставления нам общего представления о том, какое отношение расходы на внешний вид имеют к остальной части нашего набора данных, если таковые имеются.
Рисунок 6
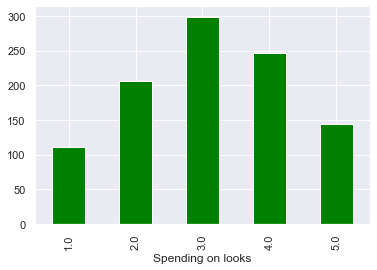
Расходы на внешний вид распределены приблизительно нормально, с центром в районе 3.
Рисунок 7
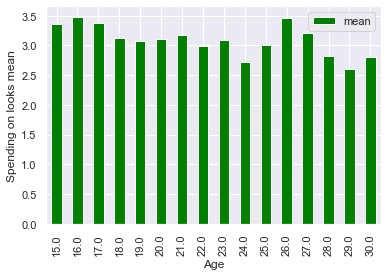
Расходы на внешность, кажется, не сильно меняются с возрастом. Он немного ниже в старшем возрасте, но определенно недостаточно, чтобы сделать вывод о значимости.
Рис. 8
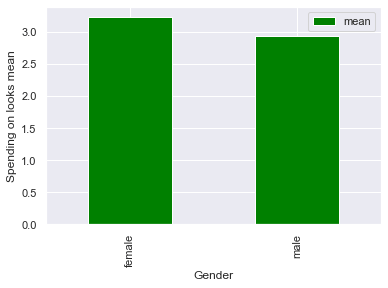
В среднем женщины тратят немного больше на внешний вид в нашем наборе данных.
Рисунок 9
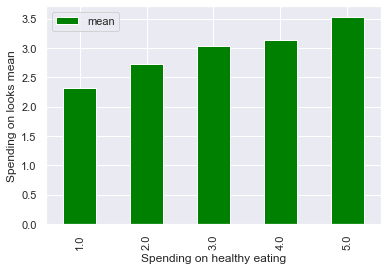
Расходы на внешний вид положительно коррелировали с большинством других переменных в категории расходов, о чем вкратце свидетельствует приведенный выше график, согласно которому группы подразумевают расходы на внешний вид как расходы на здоровое питание.
Рисунок 10
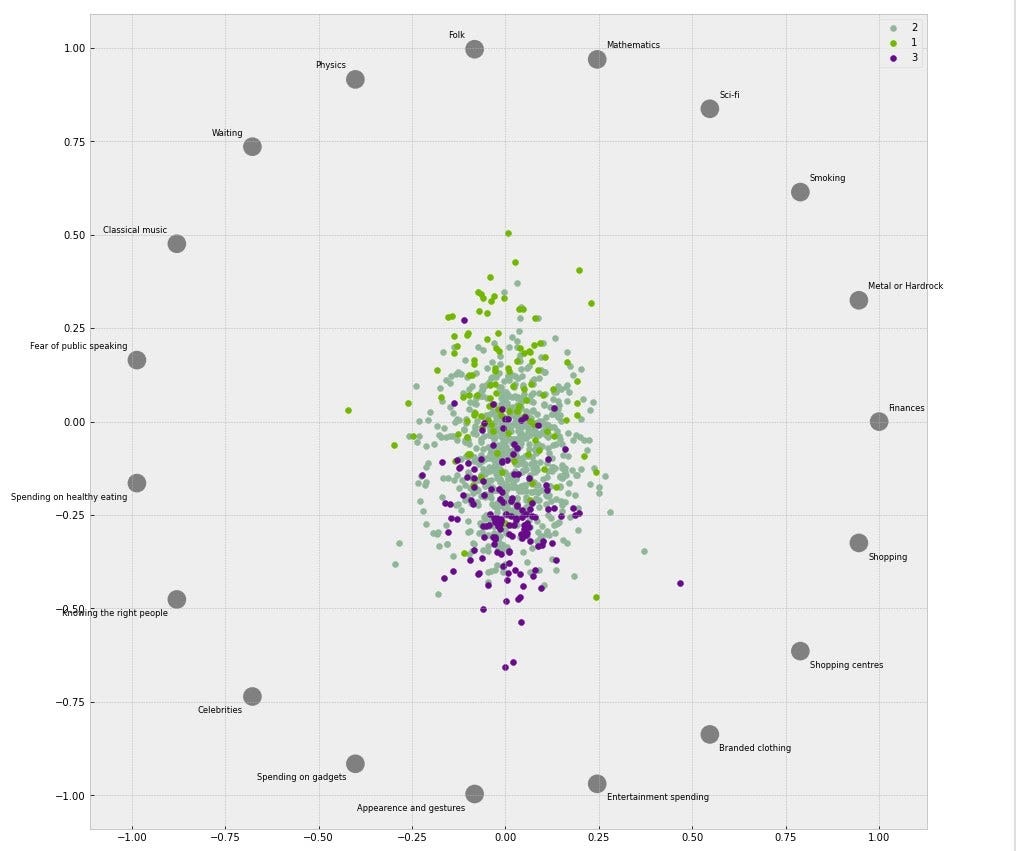
На рис. 10 показаны основные функции по классам. Люди в классе 1, вероятно, будут бояться публичных выступлений, иметь склонность к курению и, вероятно, будут интересоваться науками и математикой. Существо класса 2 более равномерно распределено по функциям набора данных. Класс 3, с другой стороны, верит в снисходительность и более склонен тратить деньги на развлечения, брендовую одежду и внешний вид.
Моделирование
** включенные GIF-файлы предназначены для иллюстративных целей и не представляют наш точный набор данных.
Для классификации были выбраны следующие модели:
- МЛП
К данным был применен многослойный персептрон из-за его высокой предсказательной способности для сложных проблем. Поскольку наш набор данных имеет табличную форму с высоким потенциалом классификации, эта модель теоретически должна работать хорошо, поскольку MLP может распознавать скрытые закономерности и неизвестные корреляции.
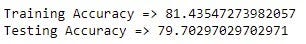
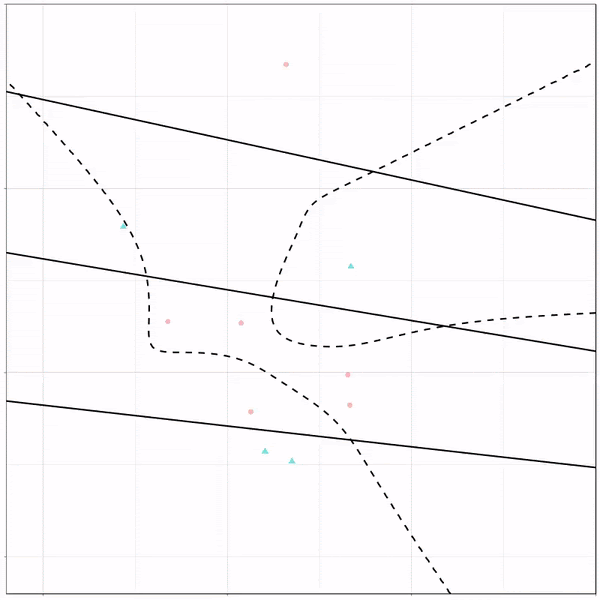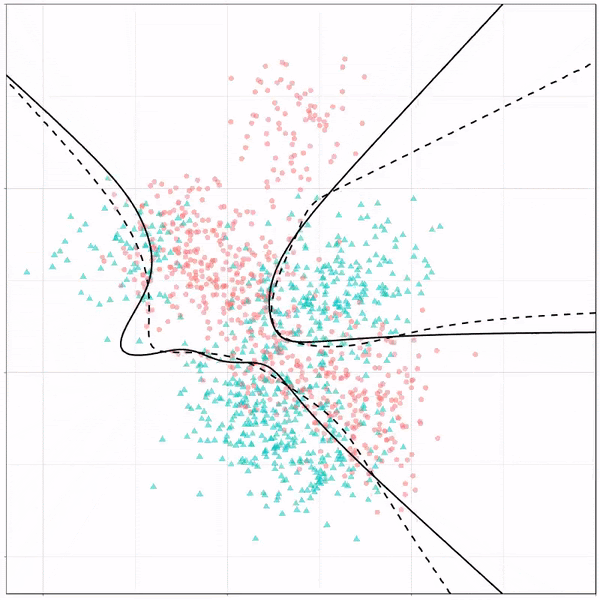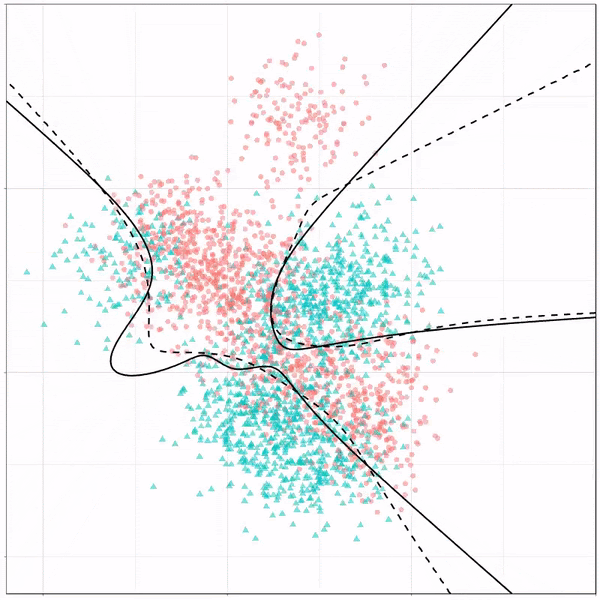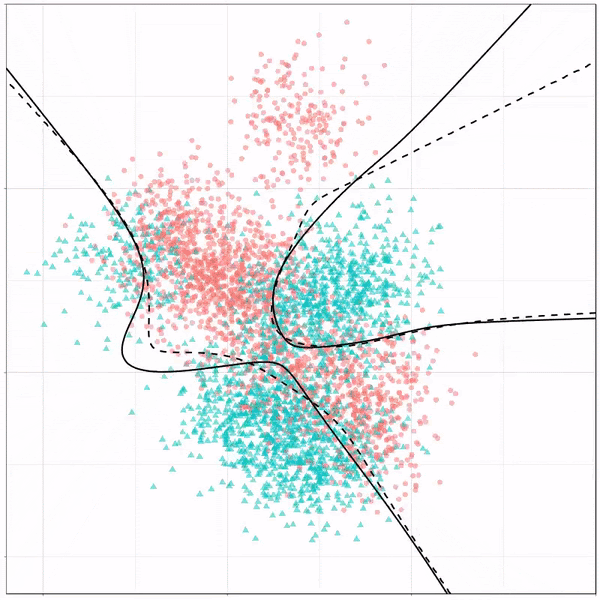
2. K-ближайшие соседи
KNN использует концепцию евклидова расстояния для идентификации и группировки похожих точек данных в идентифицируемые кластеры. Модель KNN была адаптирована к данным, основанным на гипотезе о том, что люди со схожими привычками в отношении расходов будут иметь аналогичные ответы на опросы. KNN также полезен для простой визуализации наших результатов, поскольку это модель с высокой степенью интерпретируемости, которую можно легко использовать для бизнес-приложений.
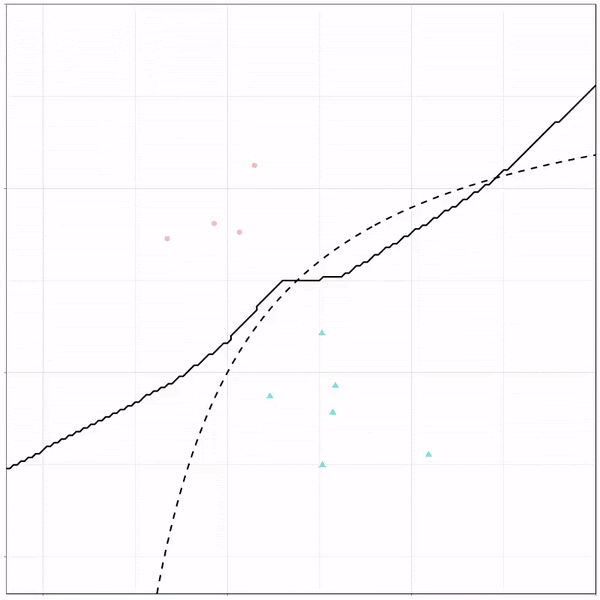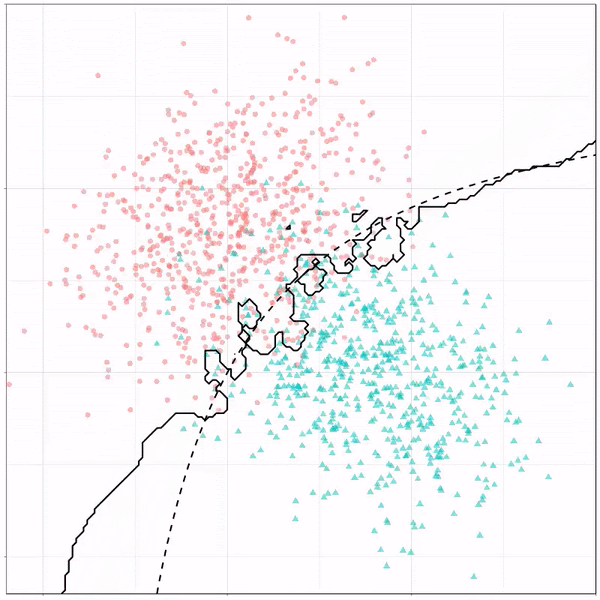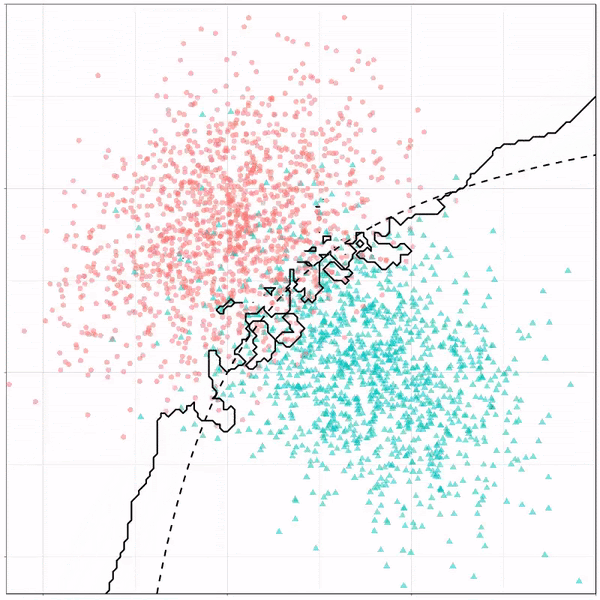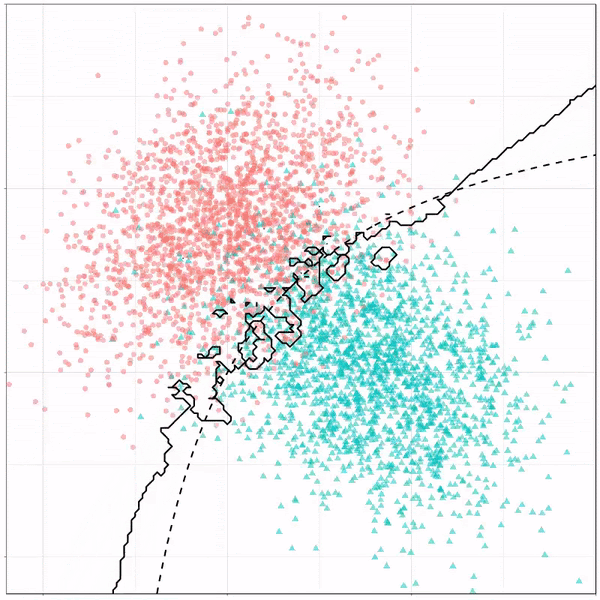
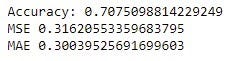
Модель хорошо показала себя на нашем тренировочном наборе с точностью 82% на тренировочном наборе и точностью 79% на тестовом наборе. KNN хорошо показал себя на нашем наборе данных, поскольку он уже разделен на классы, поэтому модель может легко определять сегменты и, соответственно, выполнять прогнозную аналитику для маркетинговой и рекламной деятельности.
3. Дерево решений
По той же причине интерпретируемости, что и для KNN, к этим данным подходило дерево решений. Кроме того, деревья являются гибкими установщиками, которые хорошо фиксируют нелинейность и взаимодействия, поэтому они хороши для нашего набора данных, в котором есть много независимых переменных, которые потенциально могут иметь эти характеристики. Деревья решений являются наиболее прозрачной моделью, поскольку пользователь может визуально увидеть, почему классификатор делает свой выбор. В управленческих решениях эта модель была бы полезным инструментом.
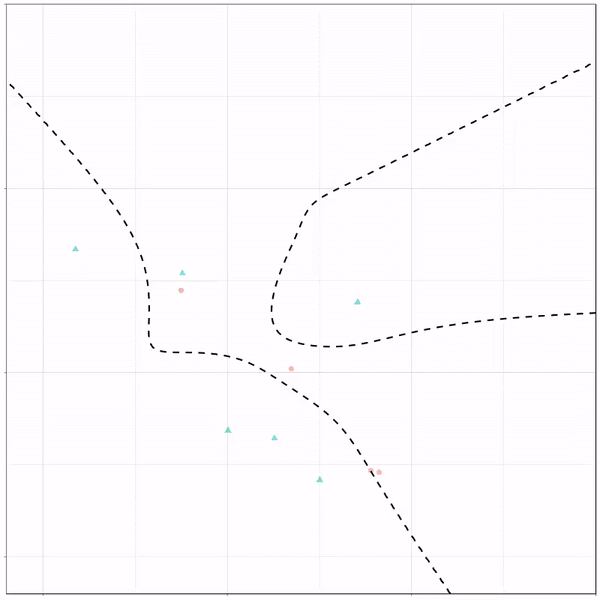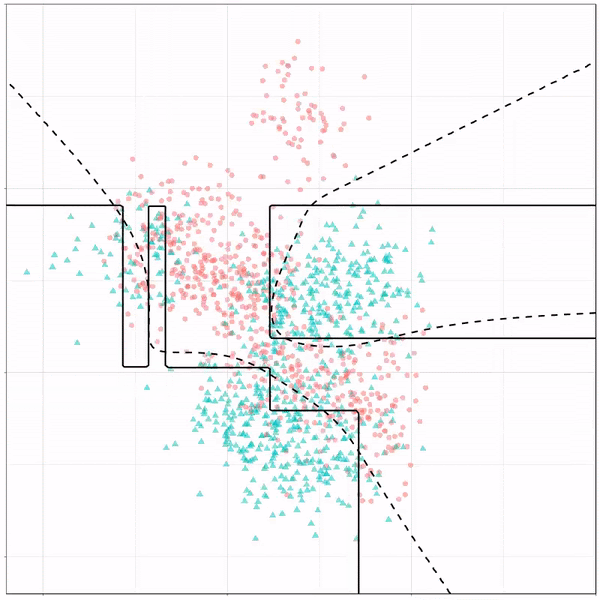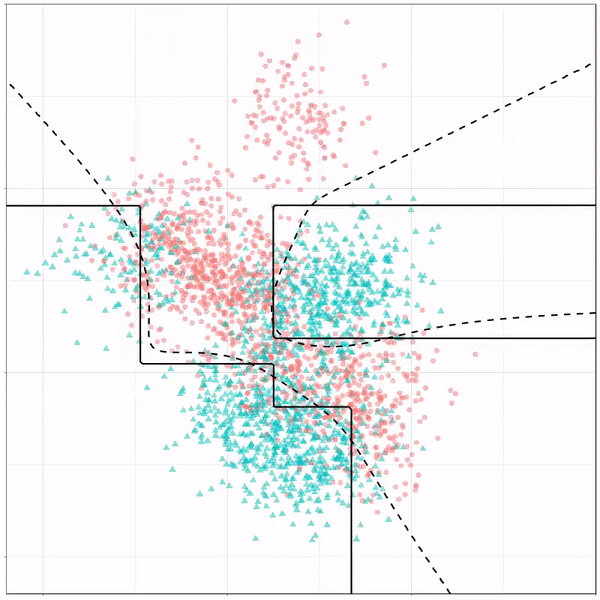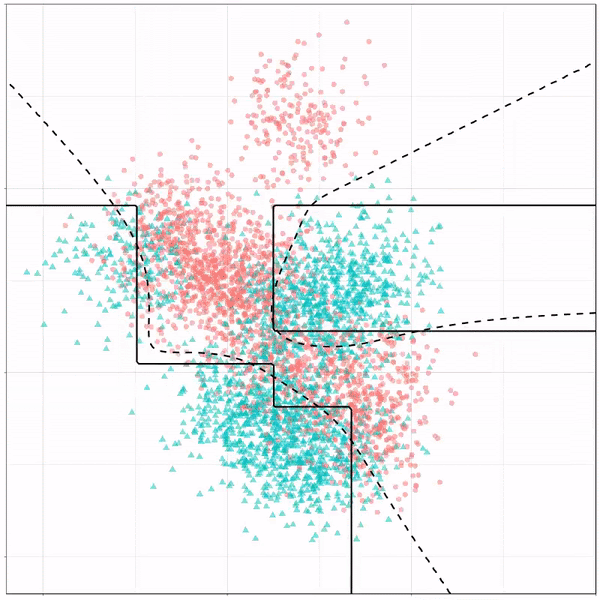
Наше дерево решений дает относительно низкую точность по сравнению с другими моделями в нашем исследовании, но остается вполне объяснимой.
4. Случайный лес
Для повышения точности дерева решений применялись ансамблевые методы, использующие деревья в качестве базовой оценки. Случайный лес создает группу некоррелированных моделей, которые превосходят отдельные составляющие модели. Низкая корреляция приводит к тому, что предсказания ансамбля имеют более высокую точность, чем индивидуальные предсказания, поскольку группа моделей уменьшает ошибку отдельных моделей.
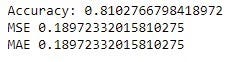
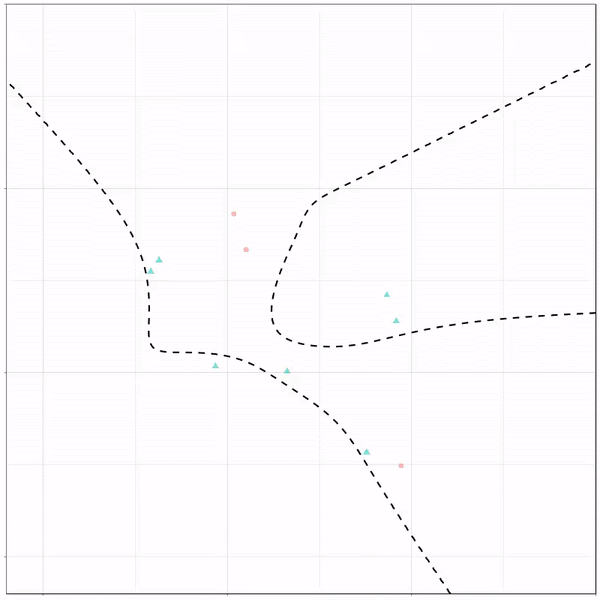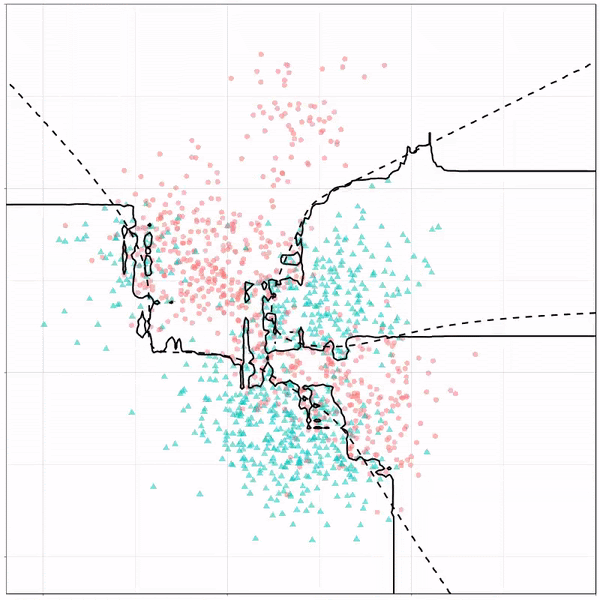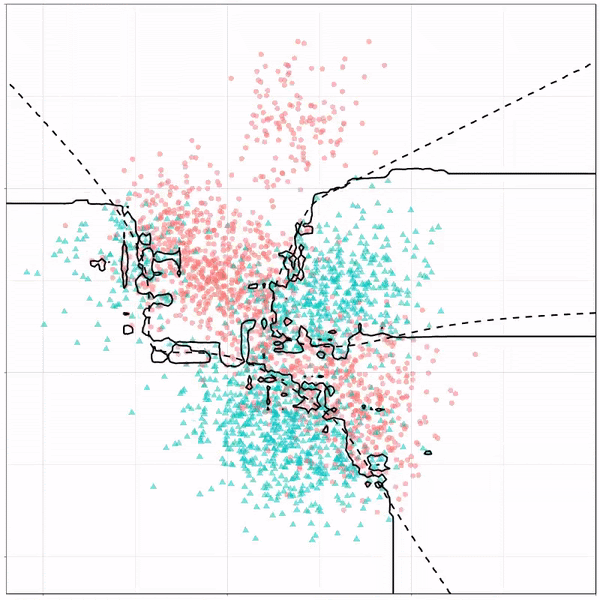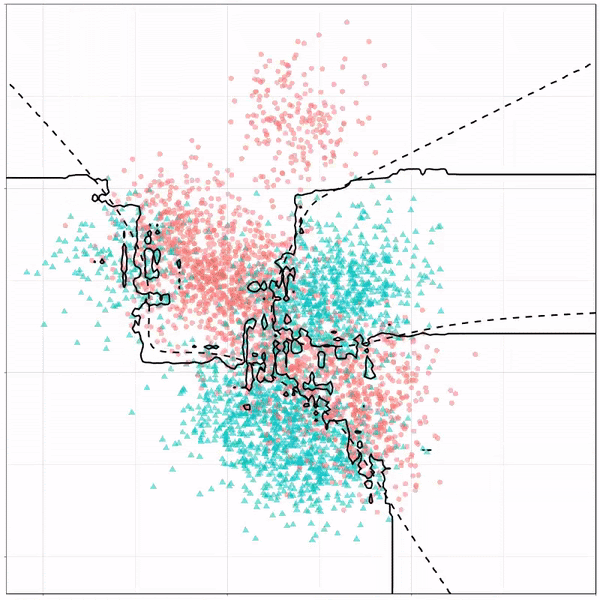
Поскольку случайный лес представляет собой ансамблевую модель, основанную на базовой модели дерева решений, а наши классы очень похожи (от 1 до 3), модель переобучает обучающие данные. Тем не менее, у нас есть надежная модель, поскольку она также обеспечивает точность 81% на данных тестирования.
5. Дерево решений в пакетах
Бэггинг (объединение начальной загрузки) модели дерева создает множество деревьев и объединяет их, чтобы получить более четкую общую картину и смыть шум. Бэггинг создает множество выборок с начальной загрузкой (выборка с заменой из исходных данных), подбирает деревья к каждой выборке с начальной загрузкой, а затем объединяет результаты деревьев путем голосования или усреднения, чтобы получить всеобъемлющее дерево прогнозов. Теоретически этот ансамблевый метод повышает точность и снижает дисперсию. Мы подогнали собранное дерево решений, чтобы сравнить результаты с нашим случайным лесом и посмотреть, сможем ли мы немного повысить точность.

Наша оценка мешков превосходит наше дерево решений и модели случайного леса.
6. АдаБуст
AdaBoost создает слабые классификаторы на основе взвешенных данных обучения. Точки данных взвешиваются на основе предыдущих неправильных классификаций, с более высокими весами тех, которые были неправильно классифицированы предыдущими слабыми учениками. Те, у кого более высокие веса, имеют больше шансов быть правильно классифицированными в следующей итерации. Мы использовали Adaboost, потому что наши деревья решений давали приличную точность, но нам было любопытно, смогут ли агрегированные слабые ученики создать модель с более высокой точностью.

Adaboost также не работает так же хорошо, как модель дерева решений с пакетами. Он имеет несколько более низкую точность теста и более высокую погрешность.
7. Усиление градиента
Повышение градиента используется для уменьшения смещения от деревьев решений. Он начинается с прогнозирования логарифмических шансов переменной ответа, а затем использует остатки для построения деревьев решений. Повышение градиента очень похоже на Adaboost, но лучше обрабатывает выбросы, поэтому мы также использовали его.


Повышение градиента имеет точность, аналогичную другим ансамблевым методам и деревьям решений, и дает более высокую точность, чем Adaboost.
8. Линейный дискриминантный анализ
LDA используется для проецирования данных высокой размерности в пространство меньшей размерности. Эта модель представляла интерес для этого проекта из-за высокой размерности нашего набора данных. Сначала мы запустили модель логистической регрессии в нашем наборе данных, поскольку она считается моделью линейной классификации по умолчанию. Однако логистическая модель потерпела неудачу, поскольку мы пытаемся смоделировать проблему множественной классификации с хорошо разделенными классами. LDA справляется с этим довольно эффективно, поскольку пытается установить линейную границу между классами.
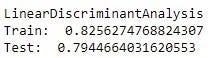
Как и предполагалось, модель LDA обеспечивает высокую точность 83% для данных обучения и 79% для данных тестирования, что показывает, что наш набор данных можно эффективно классифицировать на четкие сегменты и использовать для значимого анализа.
9. Квадратичный дискриминантный анализ
Согласно классическому определению, QDA — это вариант LDA, в котором для каждого класса наблюдений оценивается индивидуальная ковариационная матрица. QDA особенно полезен, если заранее известно, что отдельные классы демонстрируют различные ковариации. Хотя наш набор данных имеет четкое разделение, мы не уверены в ковариации между классами.
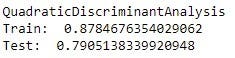
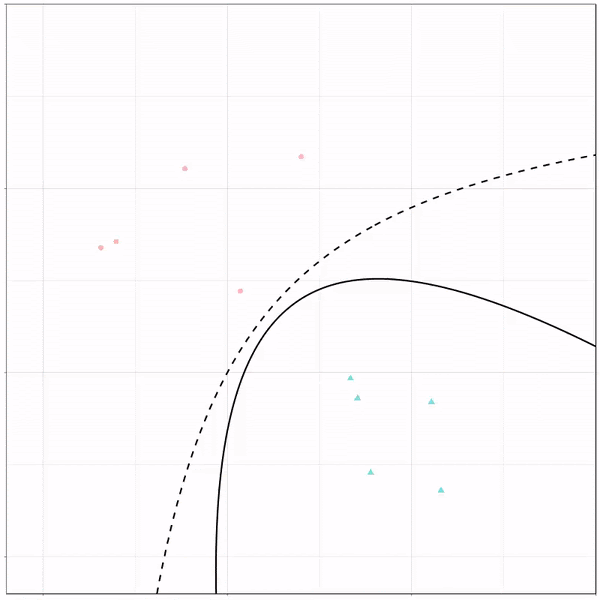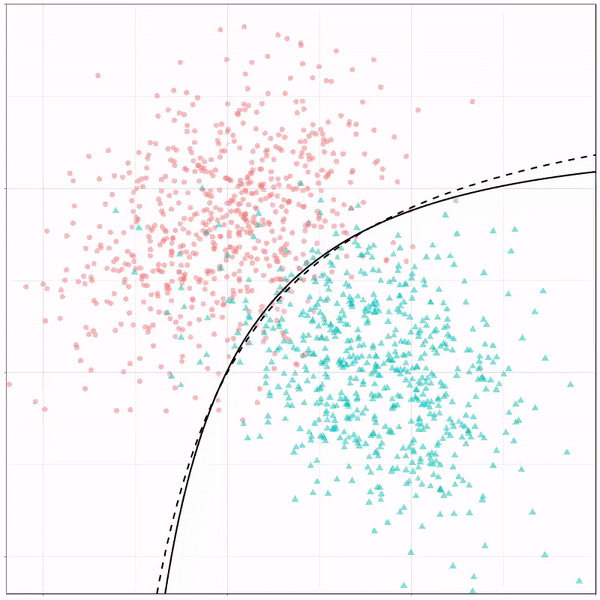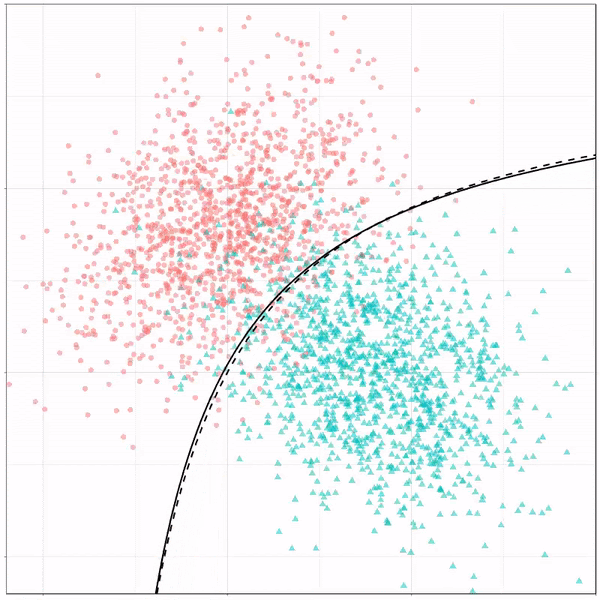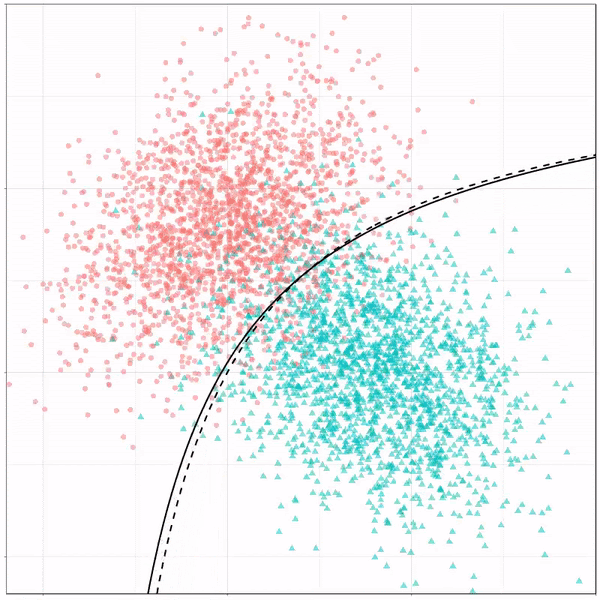
Как показано в анализе, наша модель работает лучше на тренировочном наборе с точностью 88%, в то время как наш тестовый набор имеет точность около 79%. Точность QDA немного ниже, чем у LDA полного ранга. Это указывает на то, что наша модель может иметь общую дисперсию, что весьма правдоподобно, учитывая 3 четких класса для наших ответов.
Основные выводы и оценка

Наиболее интерпретируемой моделью с высокой точностью оказалась модель K-ближайших соседей. С точностью тестирования 79% эта модель принимает решения на основе похожих личностей, которые «наиболее близки» к любой заданной точке, чтобы предсказать расходы на внешний вид. Это легче понять, особенно тем, кто не имеет опыта работы с данными, и, следовательно, его легче реализовать для фирм, которым этот анализ призван принести пользу.
Еще одним важным открытием является высокая корреляция между расходами на внешний вид и 1) интересом к покупкам, 2) брендовой одеждой и 3) расходами на развлечения. Это указывает на то, что даже без моделирования косметические бренды должны ориентироваться на людей, которые, как известно, часто посещают другие торговые центры и веб-сайты. Это особенно верно для тех, кто носит брендовую одежду или часто посещает магазины или веб-сайты узнаваемых брендов. Кроме того, расходы на развлечения в этом опросе соответствуют утверждению: «Я трачу много денег на вечеринки и общение», которому респонденты оценивают от 1 (полностью не согласен) до 5 (полностью согласен). Таким образом, те, кто тратит значительные суммы на внешний вид, как правило, также тратят значительные средства на социальную деятельность. Более крупные компании, владеющие несколькими компаниями, занимающимися развлечениями и внешним видом, могут немедленно использовать эти связанные переменные и классы KNN для сегментации клиентов, «тратящих на внешний вид», не только по покупаемым ими вещам, но и по конкретным медиа, которые они потребляют, и по их самообслуживанию. оценивали черты личности помимо расходов на внешность.
Третий ключевой вывод этого анализа произошел при предварительной обработке данных. Первоначально существовало 5 классов ответов, которые соответствовали оценкам от «Совершенно не согласен» до «Совершенно согласен» с утверждением «Я трачу много денег на свою внешность».Однако, когда классы ответов 2–4 рассматривались как один класс, повышена точность всех моделей. Этому есть два возможных объяснения. Во-первых, те, кто не тратит много денег на внешность, и те, кто тратит значительные суммы, являются двумя крайностями и имеют разные личностные характеристики. Те, кто тратит мало-умеренно (2) и высоко-умеренно (4) суммы, не имеют отдельных личностных профилей, и их труднее отличить. Вторая возможность заключается в том, что оценки между 2 и 4 более субъективны, чем две крайности. Вполне возможно, что те, кто оценивает себя по этим значениям, неправильно идентифицируют себя, и поэтому их сложнее классифицировать.
Уроки выучены
Результаты модели MLP могут сильно различаться в зависимости от того, как вы их обучаете, и поиск лучших параметров может занять некоторое время. В процессе построения модели быстро стало очевидно, что, хотя добавление скрытых слоев и нейронов имеет тенденцию повышать точность, это требует больших вычислительных ресурсов и в большинстве ситуаций может оказаться нецелесообразным. Увеличение количества складок также увеличило время перекрестной проверки; переход от cv=5 к cv=10 значительно увеличил время, затрачиваемое на перекрестную проверку. На данный момент ясно, что всегда необходимо учитывать компромисс между точностью и временными затратами.
Еще одним важным выводом является обеспечение нормализации набора данных для MLP. Это создаст среднее значение, близкое к нулю, что приведет к более быстрому обучению и, возможно, даже к конвергенции. Это было нетрудно сделать с этим довольно небольшим и простым набором данных, но все же это был важный шаг, который преподал нам ценный урок: независимо от того, с какими данными вы работаете, всегда выполняйте нормализацию при использовании нейронных сетей!
Ограничения
Хотя мы смогли сделать полезные выводы из наших моделей и набора данных, наше исследование имело четыре основных ограничения. Во-первых, наш набор данных был создан на основе опроса, который всегда может привести к систематической ошибке в ответах. Люди, принявшие участие в этом опросе, потенциально могут каким-то образом принципиально отличаться от тех, кто отказался от опроса, что внесет предвзятость в наши выводы.
Во-вторых, у нас не было никакого способа учесть усталость от реакции. Поскольку опрос, предоставленный этим учащимся, состоял из более чем 150 вопросов, учащиеся, возможно, начали отвечать с меньшей честностью и большей скоростью на более поздние вопросы, что также внесло бы предвзятость в наше исследование. В-третьих, мы должны учитывать проблемы, присущие самооценке ответов. Респонденты оценивают не свои истинные привычки к расходам, а воспринимаемые привычки к расходам относительно своих сверстников. Однако респонденты не располагают совокупными демографическими данными (которые могут существовать, а могут и не существовать) по каждому из этих вопросов. Чтобы проиллюстрировать это, респондент может ответить «3» на «Расходы на внешний вид», потому что все его друзья делают пластические операции и тратят большую часть своих денег на внешний вид, в то время как они тратят на внешний вид только 30% своих денег. Тем не менее, этот человек все еще может быть «5» по сравнению с населением в целом. Относительность самооценки ограничивает наше исследование.
Наконец, широкое определение «внешности» также может ограничить наше исследование. Внешний вид может представлять собой любое количество вещей, и у респондентов могут быть разные представления об этих вещах. Например, один респондент может думать о «внешности» только как о макияже и обуви, а другой может включать в себя операции, макияж, всю одежду, свою машину и часы.
Следующие шаги
Чтобы обойти ограничения, вызванные предвзятостью ответов, относительностью самооценки и широким определением внешности, наши идеальные следующие шаги включают более тщательный опрос и набор данных. В идеале последующее обследование должно собирать данные из случайной и репрезентативной выборки лиц. Кроме того, наш набор данных будет включать в себя еще одно наблюдение, которое будет отслеживать реальные траты на образы, которые каждый человек фактически делал в течение времени после опроса. Это дало бы нам объективную меру, поскольку требует как определения взглядов, так и устранения относительности самооценки. Мы могли бы использовать реальные расходы, чтобы лучше оценить истинную точность предсказания нашей модели. Кроме того, этот сбор данных может дать интересное представление о воспринимаемых (1–5) расходах людей на внешний вид и их истинных покупательских привычках. Наконец, мы признаем, что это последующее исследование будет дорогостоящим, и может быть не совсем осуществимо отследить все расходы такого количества людей.
Рекомендации
Достаточно ли эмпатично молодое поколение? | Kaggle (Очистка данных и код MLP)
http://uc-r.github.io/gbm_regression
Актуальные проекты
https://medium.com/@kirti.kp.94/doodling-with-deep-learning-1b0e11b858aa