Оптимизация адаптации предметной области за счет переключения аннотаций данных, обучающих сред и наборов данных для предварительной подготовки.
В этом посте я представлю концепцию адаптации предметной области в машинном обучении и обсужу процесс оптимизации инфраструктуры состязательной дискриминационной адаптации предметной области (ADDA). Вот оглавление:
- Мотивация для адаптации домена — доменный сдвиг
- Цель адаптации предметной области — семантическое выравнивание
- Интернет → Адаптация домена Xray
- АДДА — Алгоритм
- Краткий обзор мультиэтикеток
- Эксперимент № 1: Точная настройка ResNet50, предварительно обученного на ImageNet, только с веб-(исходным) доменом
- Эксперимент № 2: ADDA с кодировщиком, предварительно обученным на ImageNet
- Перерыв: в чем корень перехода Web → Xray Domain Shift?
- Эксперимент №3: ADDA с кодировщиком, предварительно обученным на Stylized+Original ImageNet
- Адаптация домена: перспективы
1. Мотивация к адаптации предметной области — смена предметной области
Взгляните на это интересное наблюдение:

Этот результат представлен в CNN, обученные ImageNet, смещены в сторону текстуры; увеличение смещения формы повышает точность и надежность (2019) показывает, что, хотя большинство людей могут легко распознать все четыре изображения как кошку🐱, несмотря на изменения в стиле, производительность всех четырех моделей классификации изображений на основе CNN, AlexNet, LeNet , VGG16 и ResNet50 резко падают из-за кота, изображенного в стиле силуэта и краев.
В исследованиях разные стили/текстуры называются разными «областями»изображений. Поскольку нейронные сети очень чувствительны к распределению входящих данных, модель классификации изображений, обученная только для одного домена изображений (называемого «исходным доменом»), научится кодировать изображения с учетом только дискриминационные свойства этого конкретного домена. Таким образом, одна и та же модель, скорее всего, будет плохо работать при тестировании на другом домене изображений (называемом "целевой домен"), как показано на рисунке выше. Эта проблема известна как Смена домена.
2. Цель адаптации предметной области — семантическое выравнивание
2.1 Входное пространство и функциональное пространство
Как мы можем свести к минимуму сдвиг домена и адаптировать модель для хорошего обобщения на новый целевой домен? Эту задачу, интуитивно называемую Domain Adaptation, можно выполнить, взглянув на два места в модели глубокого обучения:
- Входное пространство — мы можем собрать или синтезировать достаточное количество входных данных в целевой области, чтобы использовать их для обучения/точной настройки модели.
- Пространство признаков. Мы можем предложить модели отображать входные данные из разных доменов, но одного и того же класса близко друг к другу в пространстве признаков (задача под названием Семантическое выравнивание).
2.2 Семантическое (характеристическое) выравнивание
В случае, если целевая область является нишевой или не изученной в исследованиях, сбор достаточного количества данных может быть невозможным или дорогим из-за нехватки данных. По этой причине многие исследования по адаптации предметной области проводятся в функциональном пространстве с целью достижения семантического выравнивания, как показано ниже:

Представленные в Drop to Adapt: Learning Discriminative Features for Unsupervised Domain Adaptation (2019) два графика показывают представления функций набора данных VisDA-2017 (12-классовая классификация изображений с синтетическими изображениями 3D-моделей). в качестве исходного домена и реальных фотографических изображений в качестве целевого домена) до и после адаптации домена. До адаптации домена (слева) объекты исходного домена (красные) показаны как 12 отдельных кластеров, а объекты целевого домена (синие) — как один большой двоичный объект. После адаптации домена (справа) функции целевого домена демонстрируют гораздо лучшее разделение. Кроме того, хотя разные классы не обозначены на графиках, некоторые пары красных и синих кластеров появляются рядом друг с другом (обозначены голубыми прямоугольниками), которые могут представлять кластеры одного и того же класса, что свидетельствует о семантическом выравнивании.
Теперь я приведу вам пример реальной адаптации домена между обычным доменом камеры и доменом камеры Xray. Позвольте мне кратко представить проект и почему я решил использовать подход адаптации домена.
3. Интернет → Адаптация домена Xray

3.1 Данная задача
В моем магистерском исследовательском проекте в Университете Торонто меня попросили выполнить автоматическое обнаружение угроз для рентгеновского сканера багажа в аэропорту, т. е. получить рентгеновское изображение, похожее на приведенное выше, обнаружить любое оружие или нож, если они есть. .
3.2 Данный набор данных
Международный аэропорт предоставил мне 450 рентгеновских снимков багажа с 3 классами: пистолет (117 изображений), нож (33 изображения) и доброкачественный/неопасный (300 изображений). Но проблема заключалась в том, что количества заданных изображений было недостаточно для обучения нейронной сети без переобучения.
3.3 Предлагаемый путь исследования
Мой научный руководитель посоветовал мне разработать модель глубокого обучения, принимая во внимание революционную производительность сверточной нейронной сети в компьютерном зрении. В частности, он предложил мне работать с целью классификации изображений (классификация всего изображения как класса), а не с обнаружением объектов (предсказание ограничивающих рамок вокруг объектов) или сегментацией объектов (классификация каждого пикселя как принадлежащего объекту). к классу или нет), чтобы поддерживать умеренную сложность модели. Он также хотел, чтобы я использовал подход адаптации домена, учитывая, что рентгеновских изображений недостаточно для обучения нейронной сети без переобучения. Этот подход заключался в том, чтобы сначала собрать большое количество нерентгеновских, похожих на стоковые фотографии изображений тех же классов объектов из Интернета, использовать их для обучения модели, а также адаптировать модель для хорошего обобщения на рентгеновских изображениях. Наконец, аспиранты из моей исследовательской группы предложили начать с платформы Состязательная дискриминационная адаптация домена (ADDA) из-за ее относительно простого в реализации, но мощного алгоритма.
Для получения более подробной информации о проекте, пожалуйста, обратитесь к этому сообщению о проекте и списку моих сообщений о проекте.
4. АДДА — Алгоритм
Структура Состязательная дискриминационная адаптация домена (ADDA) (2017 г.) представляет собой эффективную неконтролируемую (т. целевые дистрибутивы доменов и, таким образом, повысить эффективность обобщения».
4.1 ГАН против АДДА
Со состязательными и дискриминационными терминами в названии ADDA вы можете напомнить Generative Adversarial Network (GAN) (2014). Давайте сравним два:
ГАН — Генерация изображений
- Ввод, вывод —скрытый вектор z, фальшивое изображение, сгенерированное G
- Генератор G (слои деконволюции) — преобразует скрытый одномерный вектор z в поддельное трехмерное изображение.
- Дискриминатор D (сверточные слои + полносвязные слои) — сопоставляет трехмерное изображение с реальной или поддельной двоичной меткой (например, 0 для подделки, 1 для настоящей).
- Цель D — классифицировать входные данные x как настоящие, а выходные данные G как поддельные.
- Цель G – запутать D, чтобы классифицировать результаты G как настоящие.
ADDA — Классификация изображений
- Ввод, вывод — изображение x, метка класса c
- Кодировщик E (сверточные слои; обычно мощная основа, например ResNet50) — сопоставляет трехмерное изображение с вектором одномерных объектов.
- Классификатор C (полностью связанные слои) — сопоставляет выходные данные одномерного вектора признаков E с меткой класса c.
- Дискриминатор D (полностью связанные слои) — сопоставляет выходные данные одномерного вектора объектов E с меткой двоичного домена d (1 для исходного домена, 0 для целевого домена).
- Цель D – классифицировать функции исходного и целевого доменов по их меткам реального домена (1 для исходного домена, 0 для целевого домена).
- Цель E — (1) кодировать входные изображения с дискриминацией по классам и (2) перепутать D, чтобы классифицировать функции исходного и целевого доменов как их метки поддельного домена (0 для исходного домена, 1 для целевого домена), чтобы создать функции исходного и целевого доменов, которые неразличимы в пространстве функций.
- Цель C – провести различие между разными классами (например, потеря перекрестной энтропии)
4.2 ADDA — асимметричное отображение
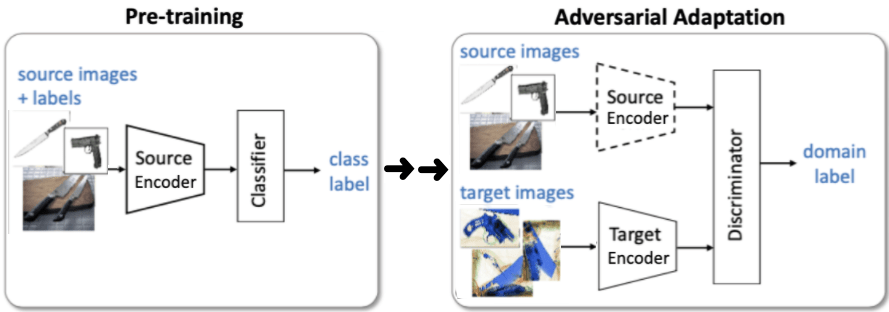
В документе ADDA предлагается использовать два отдельных кодировщика для сопоставления изображений исходного и целевого доменов. Как показано на рисунке выше, задачи классификации и адаптации предметной области выполняются последовательно, одна за другой. Во-первых, исходный кодировщик предварительно обучается на метках классов помеченных исходных изображений. Затем целевой кодировщик с архитектурой, идентичной исходному кодировщику, инициализируется с предварительно обученными весами исходного кодировщика, а затем обучается с использованием двоичных (исходный и целевой) меток домена, в то время как веса исходного кодировщика фиксируются. Поскольку ADDA выполняет неконтролируемуюадаптацию домена, предполагается, что данные целевого домена не помечены, и не оптимизируется для классификации классов в целевом домене.
В документе предполагается, что такое асимметричное сопоставление между исходным и целевым кодировщиками является более гибким, поскольку оно позволяет изучать более специфичные для предметной области функции.
4.3 Модифицированный ADDA — симметричное отображение

Я немного модифицировал ADDA, чтобы иметь один кодировщик для сопоставления изображений ОБОИХ исходного и целевого доменов. Это устраняет этап предварительной подготовки исходного кодировщика. Как показано на рисунке выше, один кодировщик одновременно обучается классификации (только с использованием изображений исходного домена и меток классов), и адаптации домена(с использованием изображений исходного и целевого доменов + бинарных меток домена) в одну эпоху.
Как я пришел к такой модификации, так это то, что в обзорном документе о применении глубокого обучения в визуализации безопасности Xray (2021 г.) сообщалось, что большинство признанных состязательных дискриминационных моделей для адаптации предметной области используют симметричное сопоставление.

Я также наблюдал лучшую производительность при использовании симметричного отображения. Это может быть связано с тем, что для асимметричного сопоставления предварительно обученные веса исходного кодировщика уже могут быть слишком смещены для сопоставления изображений исходного домена в соответствии с их метками классов, что служит неоптимальной отправной точкой для целевого кодировщика. Поскольку симметричное отображение позволяет оптимизировать классификацию и адаптацию предметной области одновременно в одну эпоху обучения, кодировщик может корректировать веса с учетом обеих задач.
4.4 ADDA — Заявленная производительность

В приведенной выше таблице показана производительность ADDA для задач распознавания цифр и офисных объектов, которая намного лучше, чем модель «Только источник», которая была обучена только с данными исходной области, и сравнительно лучше, чем предыдущие платформы адаптации предметной области. В документе не упоминается семантическое выравнивание; однако позже я покажу, как ADDA достигает этого для моей собственной задачи.
Пошаговая реализация PyTorch для обучения ADDA (плюс функции для построения графиков t-SNE и определения наборов данных с несколькими метками) включена в мою Записную книжку Colab. Далее я расскажу о своих экспериментах по адаптации домена, проведенных в хронологическом порядке. На каждом этапе я буду представлять результирующие графики t-SNE исходных и целевых объектов домена для проверки семантического выравнивания.
5. Краткий обзор мультиэтикеток

Как показано выше, большинство рентгеновских изображений содержат другие безобидные (т. е. неопасные) объекты, загроможденные пистолетом или ножом, в то время как на большинстве веб-изображений показан изолированный объект. Таким образом, модель может легко обращать внимание на другие объекты на рентгеновских снимках, кроме пистолета или ножа. Имея это в виду, аннотирование каждого изображения стандартной меткой single (класс 0, 1 или 2) не позволяет модели предсказать, что в изображении присутствует более одного класса, например. пистолет идругие безвредные предметы. Чтобы исправить это, я присвоил каждому изображению мультиметку:

Следует отметить, что я обнаружил тенденцию модели классифицировать изображения как доброкачественный класс с большей уверенностью по сравнению с классами пистолета и ножа (совершенно интуитивно, поскольку доброкачественный класс представляет вселенную помимо пистолета и ножа🤨). Поскольку обнаружение безвредных объектов не так важно, как обнаружение пистолета или ножа, я ослабил сигнал безвредных объектов, присвоив классу безвредных объектов мягкую метку 0,5, а другим — 1. Более подробная информация о множественных метках обсуждается в моем предыдущий пост об оптимизации данных.
6. Эксперимент № 1: тонкая настройка ResNet50, предварительно обученного на ImageNet, только с веб-(исходным) доменом.
Для моего первоначального эксперимента я загрузил ResNet50 с весами, предварительно обученными на наборе данных ImageNet, и точно настроил его на изображениях веб-домена (исходного) как для случаев с одной меткой, так и для случаев с несколькими метками. В процессе не использовались рентгеновские (целевые) доменные изображения. В обоих случаях полнота модели для изображений исходной области достигла 0,99+ менее чем за 10 периодов обучения. Напротив, возврат доменов Xray (целевой) был плохим из-за сдвига домена:

Хотя количество отзывов для случая с несколькими этикетками в два раза выше, чем для случая с одной этикеткой, все же намного ниже желаемых 100%. Ниже приведены графики t-SNE исходных и целевых функций домена, закодированные точно настроенным ResNet50 с данными с несколькими метками, с цветовыми метками по домену (слева) и домен + класс (справа).
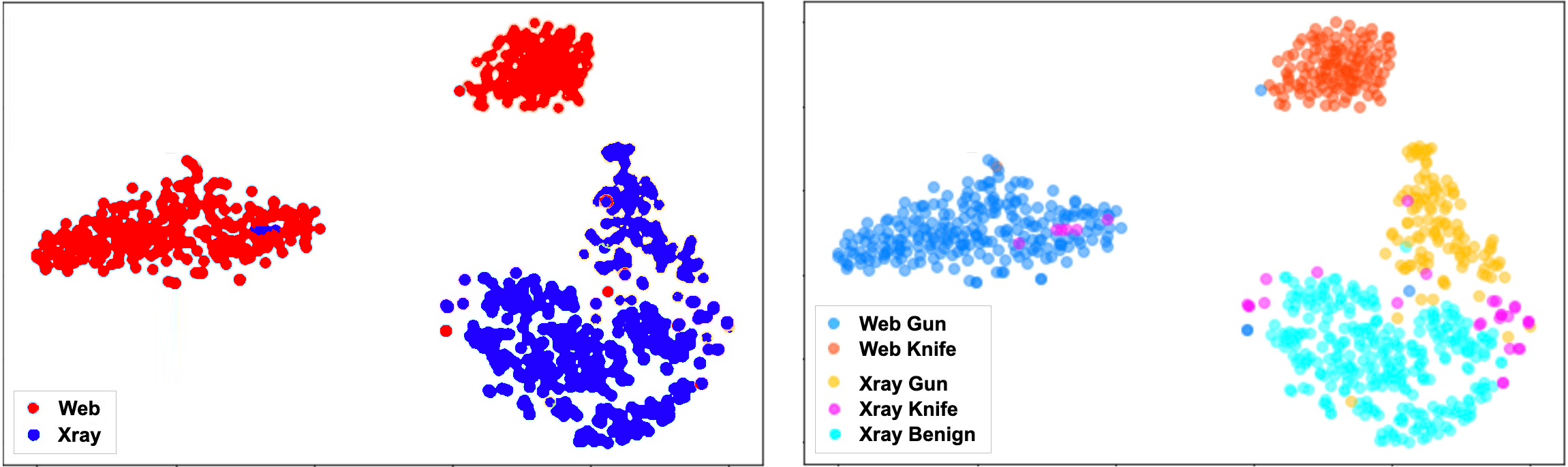
На левом графике показана аналогичная картина с левым графиком в Разделе 2.2, где объекты домена Интернета (исходного) красного цвета тесно сгруппированы по классам (пистолет и нож), а объекты домена Xray (целевой) синего цвета выглядят как одна капля. Правый график показывает, что модель далека от достижения семантического выравнивания. Мы видим, что функции рентгеновского пистолета (желтые) приближаются к функциям паутинного пистолета (красные), но они все еще более тесно связаны с рентгеновским ножом и доброкачественными функциями рентгеновского излучения. Элементы рентгеновского ножа (розовые) разбросаны случайным образом без каких-либо признаков приближения к скоплению паутинных ножей (кобальтово-синий). Это означает, что модель не может в полной мере смотреть сквозь рентгеновскую текстуру и обнаруживать объекты, которые она была обучена обнаруживать на рентгеновских изображениях.
7. Эксперимент № 2: ADDA с кодировщиком, предварительно обученным на ImageNet
Затем я тренировался с фреймворком ADDA. Сначала я назначил кодировщику ту же архитектуру, что и ResNet50, и инициализировал его с предварительно обученными весами на наборе данных ImageNet. Затем я обучил кодировщик, используя (1) веб-изображения и их метки классов для классификации и (2) как веб-изображения, так и рентгеновские изображения, а также метки доменов 0 и 1 для адаптации домена. Поскольку ADDA выполняет неконтролируемую адаптацию домена, метки рентгеновских изображений никогда не использовались. Ниже приведены результирующие графики t-SNE функций кодировщика в несколькихпромежуточных эпохах обучения: (эпоха 1, 5, 10, 15, 21)
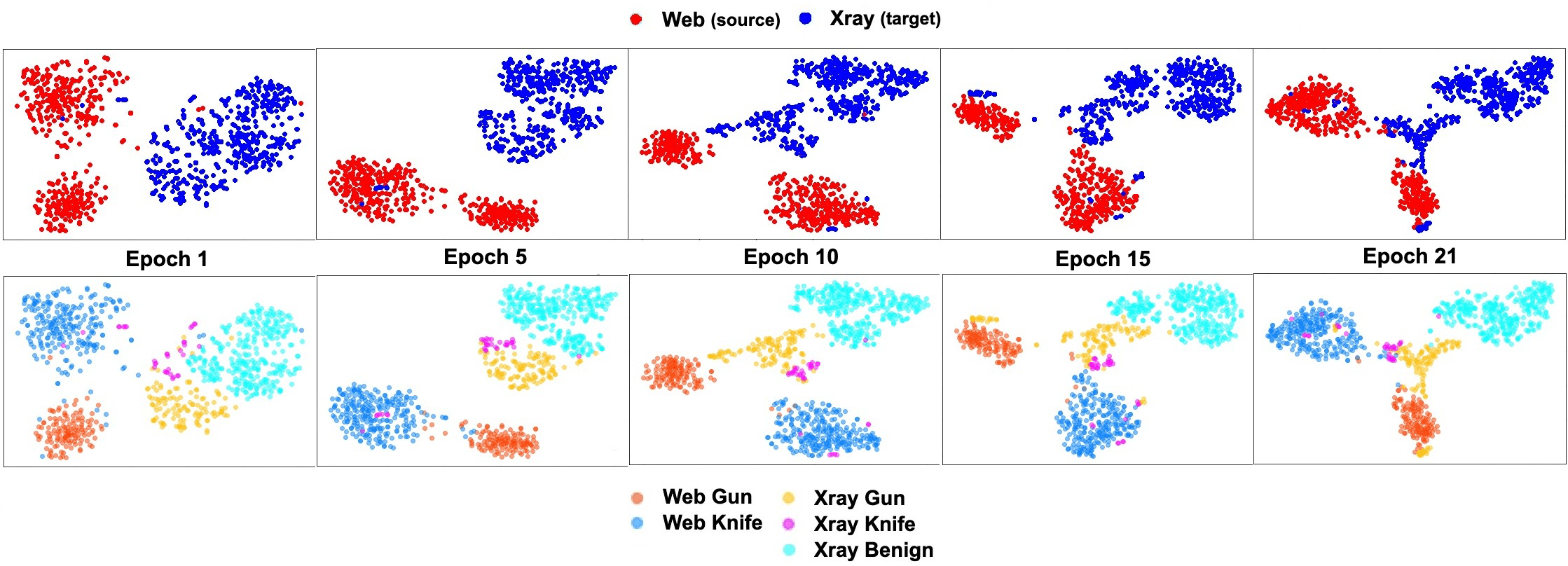
В эпоху 1 мы видим единый блок рентгеновских объектов, выделенный синим цветом, со всеми тремя классами, сгруппированными вместе. По мере прохождения обучения ADDA; однако один капля начинает распадаться. Функции рентгеновского ножа (розовые) начинают мигрировать к функциям паутинного ножа (кобальтово-синий), а функции рентгеновского пистолета (желтый) начинают мигрировать к функциям паутинного пистолета (кобальтово-синий). В эпоху 21 признаки рентгеновской пушки и рентгеновского ножа видны на небольшом расстоянии от доброкачественных признаков рентгеновского излучения, что является огромным улучшением в достижении семантического выравнивания! Такое качественное улучшение также отражается в увеличении числа отзывов оружия и ножей:

8. Перерыв: в чем корень смены домена Web → Xray?
Несмотря на такое улучшение, 78% и 70% отзывов оружия и ножей по-прежнему далеки от обеспечения безопасности полетов. Мы уже попробовали ADDA, что нам делать дальше?🤔 Я пытался обучить несколько других фреймворков адаптации предметной области, представленных совсем недавно (таких как Drop to Adapt, Domain Mixup, DADA), с моим набором данных, но не смог получить любые лучшие результаты. Поэтому вместо этого я больше думал о корнепроблемы смещения домена web → Xray.

Глядя на веб-изображения и рентгеновские снимки, я могу указать на два основных отличия:
- Сдвиг текстуры: рентгеновские изображения имели ограниченные цвета, повышенную прозрачность и небольшую размытость по сравнению с веб-изображениями.
- Уровень беспорядка объектов — рентгеновские изображения содержат различные объекты, сложенные вместе, по сравнению с веб-изображениями с явным присутствием основного объекта.
Но почему мы, люди, можем обнаружить пистолет или нож на рентгеновских снимках, несмотря на такие трудности? Возможно, мы четко помним ФОРМУ пистолета и ножа и пытаемся найти ее на рентгеновских снимках. Размышление об этом привело меня к статье, представленной в начале этого поста: CNN, обученные ImageNet, склонны к текстуре; увеличение смещения формы повышает точность и надежность (2019).
В этой статье предлагается гипотеза текстуры, в которой утверждается, что текстуры объектов более важны, чем глобальные формы объектов для распознавания объектов CNN. Локальной информации, такой как текстура, может быть достаточно, чтобы «решить распознавание объектов ImageNet». Это фатальный недостаток моделей CNN, особенно связанный с моей проблемой, когда происходит огромный сдвиг текстуры с веб-изображения на рентгеновское изображение. Поэтому, чтобы сделать модель более чувствительной к форме объектов, а не к текстуре, в документе предлагается предварительно обучать модель с помощью стилизованных изображений. . Стилизация изображения означает сохранение содержимого/форм изображения при замене стиля/текстуры изображения случайно выбранной картиной из набора данных Painter by Numbers (который содержит 79 434 картины) с использованием Передача в стиле АдаИН. Вот пример изображения, стилизованного под десять разных картин:

В документе сообщается, что модель, предварительно обученная на ОБОИХ стилизованных и исходных наборах данных ImageNet, а затем точно настроенная на оригинале, показала наилучшие результаты. Контрольные точки модели и инструкции по загрузке доступны в репозитории автора статьи на Github.
9. Эксперимент №3: ADDA с энкодером, предварительно обученным на Stylized+Original ImageNet
Поэтому я снова потренировался с ADDA, настроив архитектуру кодировщика так же, как ResNet50, и на этот раз инициализировав ее с весами из упомянутой выше модели с наибольшей производительностью. Вот итоговые графики t-SNE:

Вы заметили улучшения по сравнению с предыдущими экспериментами? Для лучшего понимания вот графики трех экспериментов:

Глядя на три нижних графика слева направо, мы видим прогресс в следующих аспектах:
- Отделение признаков рентгеновского пистолета и рентгеновского ножа (желтый и розовый) от доброкачественных признаков рентгеновского излучения (голубой)
- Миграция функций рентгеновской пушки (желтый) в функции веб-пушки (красный)
- Миграция функций рентгеновского ножа (розовый) в функции веб-ножа (синий)
Такой прогресс показывает, что эта модель достигла семантического выравнивания. Модель теперь может смотреть сквозь текстуру рентгеновского снимка и обнаруживать пистолет и нож, несмотря на изменение текстуры с обычной камеры на рентгеновский снимок. В следующей таблице показано увеличение отзыва оружия и ножей для финальной модели:

10. Адаптация домена: перспективы
Таким образом, я рассмотрел различные перспективы адаптации предметной области, включая структуру обучения модели, данные предварительной подготовки, качественную метрику (семантическое выравнивание) и количественную метрику (отзывы). Для этого поста я удобно разделил свой исследовательский процесс на три разных эксперимента, но на самом деле между ними были проведены сотни экспериментов (плюс тысячи мысленных экспериментов в душе), чтобы проверить, среди прочего, эффективность мульти-меток. », важность изучения форм объектов и эффективность графиков t-SNE при проверке семантического выравнивания (каждый из них подробно описан в других моих постах по ссылкам). Также обратите внимание, что в документе ADDA никогда не упоминается семантическое выравнивание, но я признал его основной целью адаптации предметной области после того, как откопал множество других исследовательских работ по адаптации предметной области.
Как специалисты по машинному обучению, мы часто стремимся найти исследовательскую работу, которая решает аналогичную проблему с нашей, реализовать и запустить алгоритм с нашими данными, и бум! точность достигла высокого уровня, и проблема была решена. Но если результаты недостаточно хороши, мы должны усердно искать разные точки зрения на проблему. Я полагал, что характеристики моих данных могут сильно отличаться от характеристик наборов данных, использованных в документе ADDA, и искал способы приспособиться к этой разнице.
Опять же, пошаговая реализация PyTorch для обучения ADDA (плюс функции для построения графиков t-SNE и определения наборов данных с несколькими метками) включена в мою записную книжку Colab. Вы можете связаться со мной по любым вопросам или отзывам 😊. Спасибо за чтение и счастливого машинного обучения! 🦋🦋