
Если вам когда-либо приходилось иметь дело с открытыми вопросами в онлайн-интервью, вы определенно сталкивались с проблемой их количественной оценки. Данные ответы респондентов часто полны опечаток и несоответствий, необходимых для правильной перекодировки, что еще хуже, у большинства брендов есть различные псевдонимы, которые вы должны учитывать в своем анализе. Я покажу вам, как правильно классифицировать 95%-99% полученных ответов, даже не используя модель машинного обучения или глубокое обучение.
Отказ от ответственности за кликбейт: этот метод хорошо работает только для специальных задач перекодирования, таких как следующие. :)
Проблема
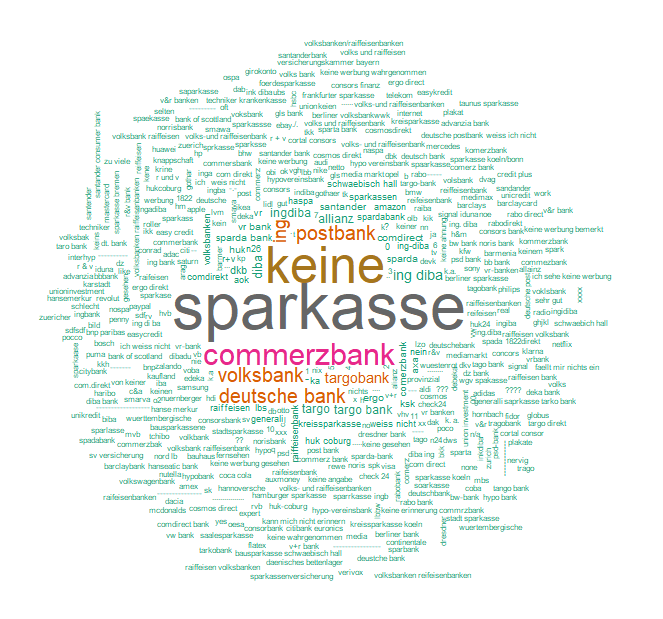
Количественное определение узнаваемости/припоминания бренда двенадцати немецких банков без посторонней помощи путем записи ответов примерно 25 000 онлайн-интервью. (Кому интересны метрики рекламы/бренда: Ссылка). Каждый человек (ID) мог вспомнить до 8 брендов, что дало 40 000 ответов! Вот как выглядит исходный вывод:

Обратите особое внимание на различные варианты написания слов «sparkasse» или «commerzbank» и различные псевдонимы «IngDiba». Облако слов из 1000 наиболее частых ответов показывает, что повторяющихся ответов всего несколько, хотя на них приходится 60% всех упоминаний!
Возможные решения
По сути, у вас есть 3 варианта выполнения работы:
- Найм низкооплачиваемого работника
Плюсы: навыки работы с данными не требуются. По-прежнему наиболее распространенное решение в большинстве компаний.
Минусы: склонность к ошибкам. Нет документации. Нет прозрачности. Субъективный. - Модель глубокого обучения
Плюсы: избавьтесь от проблемы раз и навсегда и продайте свою модель DL!
Минусы: нет данных для обучения. Бюджет?! Может быть, перестарался. - Матрица расстояний Левенштейна и простая эвристика
Преимущества: простая настройка. Очистить правила. Прозрачный.
Минусы: работает только для специальных задач.
Этот пост, очевидно, сосредоточен на третьем решении, но мне очень любопытно, можно ли применить модель глубокого обучения для этой задачи. (Не забывайте, что обучающих данных нет!)
В основном вы должны выполнить следующие пять шагов:
- Создайте словарь с псевдонимами.
- Отформатируйте свои строки (избавьтесь от специальных символов, конечных пробелов и т. д.).
- Сократите свои данные до уникальных ответов.
- Создайте «большую» матрицу расстояний Левенштейна.
- Классифицируйте ответы с помощью простых эвристик + LDM.
Шаг первый: создайте словарь с псевдонимами
Прежде всего, вам нужно создать словарь со всеми интересующими названиями брендов, включая возможные псевдонимы. Например, бренд «Deutsche Bank» может быть сокращен как «DB», а банк «Ing-Diba» часто пишется как «ing» или «diba». Вам нужно немного знаний в предметной области, чтобы упростить LDM. Словарь может выглядеть так:
Мы дорабатываем наш словарь, добавляя бренд «Не знаю / Нет», потому что многие люди в онлайн-интервью не вспомнят ни одного бренда, просто не хотели оставлять поле пустым.
Шаг второй: отформатируйте строки
К счастью, нас интересуют только торговые марки, поэтому нам не нужно выполнять расширенный поиск и лемматизацию наших ответов. Для всех, кто интересуется этими основными техниками НЛП, вот краткое введение:
Для ускорения работы функции LDM нам достаточно уменьшить количество удаляемых/заменяемых уникальных слов:
- Завершающие пробелы
- Специальные символы и умлауты
- Заглавные буквы
Шаг третий: Сократите свои данные до уникальных ответов.
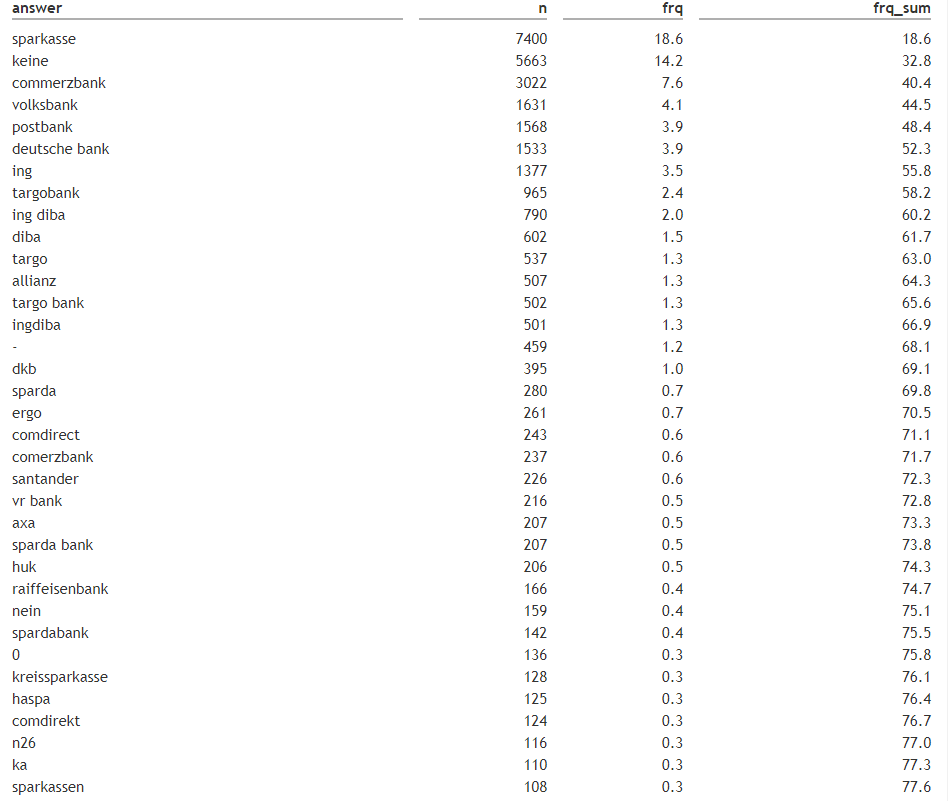
Следовательно, дублирующиеся ответы будут иметь одинаковое расстояние в нашем LDM, пора от них избавиться. Давайте сохраним частоты данных ответов, чтобы позже скорректировать нашу классификационную оценку с небольшим количеством dplyr.
Всего получается около 3000 уникальных ответов. Вот снимок первых 40 ответов в порядке убывания частоты, что указывает на то, что многие бренды написаны с ошибками или указаны под псевдонимами.
Шаг четвертый: Создайте «большую» матрицу расстояний Левенштейна.
Но подождите: что делает алгоритм Левенштейна? Короче говоря, каждое слово проверяется на предмет того, сколько «удалений», «вставок» или «замен» символа в слове необходимо, чтобы преобразовать его в желаемый результат, в данном случае в наши псевдонимы. По умолчанию удаление ивставка «стоят» штрафа в 1 балл, а замена стоит 2 балла. (Подстановка есть не что иное, как удаление после вставки!).
Некоторые примеры:
- Deutzsche Bank -› Deutsche Bank (Удаление, 1 балл)
- Deusche Bank -› DeutBank (Вставка, 1 балл)
- Deuzsche Bank -› Deutsche Bank (Замещение, 2 балла)
- Sparkasse -> Deutsche Bank (Несколько операций, 16 баллов)
Я не буду вдаваться в подробности здесь, потому что есть отличные объяснения алгоритма:
К счастью, алгоритм уже реализован в R (функция adist), и вам нужно всего лишь немного поработать с данными, чтобы получить комбинацию ответ-псевдоним с минимальным расстоянием.
Эта упрощенная матрица расстояний Левенштейна иллюстрирует основную идею, так что мы можем кратко обсудить преимущества и недостатки матрицы расстояний для нашей данной задачи:
- ** Данные***
Краткая идея, преимущества, недостатки
Шаг пятый: классифицируйте ответы с помощью простых эвристик + LDM.
Мы попробуем различные подходы к перекодированию, чтобы сравнить нашу классификацию LDM с (почти идеальным) ручным перекодированием:
- Уровень 0: точное соответствие регистра псевдонимов
- Уровень 1: Соответствие шаблону псевдонимов
- Уровень 2.1: LDM без «обрезки»
- Уровень 2.2: ЛДМ с «подсечкой» на дистанции выше 2
- Уровень 2.3: LDM с «обрезкой» в зависимости от длины символа.
- Уровень 3: LDM с «обрезкой» на основе комбинации длины символа и соответствующего шаблона.
Эффективность наших подходов измеряется специфичностью, чувствительностью и, что наиболее важно в данном случае: точностью.
Уровень 0 и 1: точное сопоставление регистра и сопоставление с образцом
Простые циклы ifelse и некоторый «grep» выполнят работу, чтобы соответствовать (точному) шаблону псевдонима:
Уровень 2.1- 2.3: Классификация по расстоянию с Левенштейном
Пришло время, наконец, сделать классификацию с помощью нашего LDM (объект: ldm).
Уровень 3: Сочетание сопоставления с образцом и LDM
На последнем этапе мы объединим подход сопоставления с образцом (уровень 1) с гибкой классификацией LDM (уровень 2.3).
Бенчмаркинг
Давайте поближе посмотрим на результаты:

Сочетание простых правил и Левенштейна приводит к точности почти 99%!
Если вникнуть в детали, то можно заметить, что только «Фолькс-унд Райффайзенбанк» работает «плохо» с 95% АКК, остальные торговые марки работают отлично:

Вкратце: несколько идей для дальнейшей оптимизации:
- Усовершенствованный алгоритм Левенштейна
- Несколько отзывов в одной ячейке
- Тонкая настройка эруистики и псевдонимов
Спасибо за прочтение! Еще один интересный анализ на моем сайте: www.halamuda.com!
Вы можете найти полный набор данных и полный R-синтаксис на github: